







说明:如需数据可以直接到文章最后关注获取。
1.数据背景
数据集的历史与来源:Iris 鸢尾花数据集是由英国统计学家和生物学家 Ronald A. Fisher 于 1936 年首次引入的,因此也被称为 "Fisher's Iris" 数据集。Fisher 是现代统计学的奠基人之一,他在《The Use of Multiple Measurements in Taxonomic Problems》这篇论文中使用了该数据集来展示如何通过多个测量值(即特征)来进行分类问题的研究。Fisher 的研究旨在通过数学和统计方法来解决生物学中的分类问题,特别是如何根据植物的形态特征将其归类到不同的物种。
数据集的采集:Iris 数据集中的样本来源于三种不同种类的鸢尾花(Iris),这些样本由 Edward Anderson 收集。Anderson 是一位植物学家,他专注于北美西部的植物分类学研究。他在 1935 年发表了《The Species Problem in Iris》,其中详细描述了这三种鸢尾花的形态特征,并提供了大量的观测数据。Fisher 后来使用 Anderson 的数据进行了进一步的统计分析,最终形成了我们现在所熟知的 Iris 数据集。
数据集的应用场景:Iris 数据集因其简单性和代表性,广泛应用于以下领域:
1)机器学习与数据挖掘:作为入门级的数据集,Iris 被广泛用于教授分类算法(如 KNN、SVM、决策树、随机森林等)、聚类算法(如 K-means)、降维技术(如 PCA)等。它帮助初学者理解如何从数据中提取有用的信息,并构建预测模型。
2)统计学与数据分析:Iris 数据集常用于展示多变量统计分析方法,如多元回归、判别分析、主成分分析等。它还被用于演示如何通过可视化工具(如散点图矩阵、箱线图、直方图等)来探索数据的分布和关系。
3)生物分类学:虽然 Iris 数据集最初是为了展示统计方法而设计的,但它仍然具有一定的生物学意义。它展示了如何通过植物的形态特征来进行物种分类,这对于植物学家和生态学家来说是非常重要的。
4)教育与培训:由于其简单易懂的特点,Iris 数据集被广泛用于大学课程、在线教程和工作坊中,帮助学生和从业者快速掌握数据科学的基本概念和技术。
Iris 鸢尾花数据集是一个经典的机器学习数据集,具有重要的历史意义和广泛的应用价值。它不仅为统计学家和生物学家提供了宝贵的分类工具,也为数据科学家和机器学习爱好者提供了一个理想的入门数据集。尽管它的规模较小,特征简单,但它仍然是一个非常有价值的教学资源,帮助人们理解如何从数据中提取有用的信息,并构建有效的预测模型。
2.数据介绍
数据格式为csv格式。
| 编号 | 变量名称 | 描述 |
| 1 | sepal length | 萼片长度(厘米) |
| 2 | sepal width | 萼片宽度(厘米) |
| 3 | petal length | 花瓣长度(厘米) |
| 4 | petal width | 花瓣宽度(厘米) |
| 5 | y | Iris-setosa(山鸢尾) Iris-versicolor(变色鸢尾) Iris-virginica(维吉尼亚鸢尾) |
数据详情如下(部分展示):
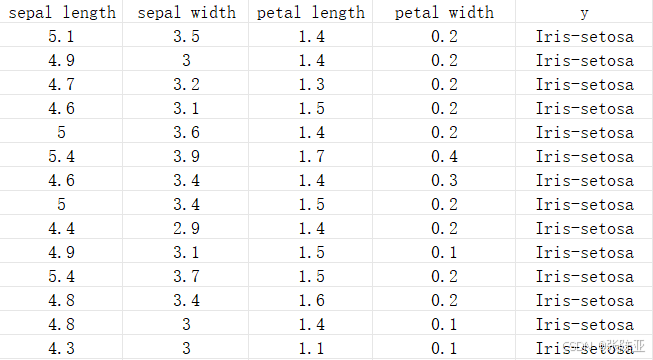
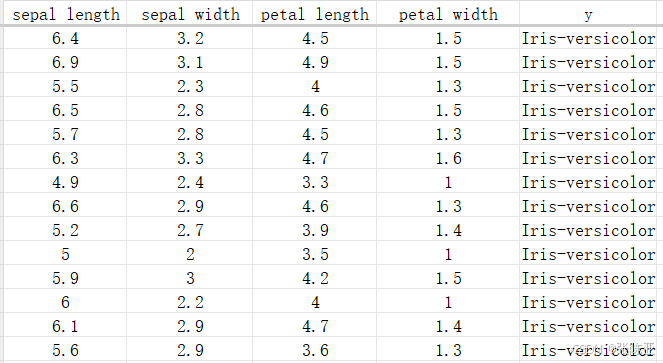
3.数据获取
关注下方 回复1006,获取。


















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











