









说明:这是一个机器学习实战项目(附带数据+代码+文档+代码讲解),如需数据+代码+文档+代码讲解可以直接到文章最后获取。
1.项目背景
支持向量机可以用于回归问题,即支持向量机回归,简称支持向量回归(Support vector regression, SVR)。支持向量机(SVM)建立在 VC 维理论和结构风险最小化原理基础之上,最初用于解决二分类问题(支持向量机分类),后被推广到用于解决函数逼近问题,即支持向量回归(SVR)。通常而言,可以使用核技巧将作为输入的非线性样本集变换到高维空间而改善样本分离状况。本项目使用svr算法进行建模预测。
2.数据获取
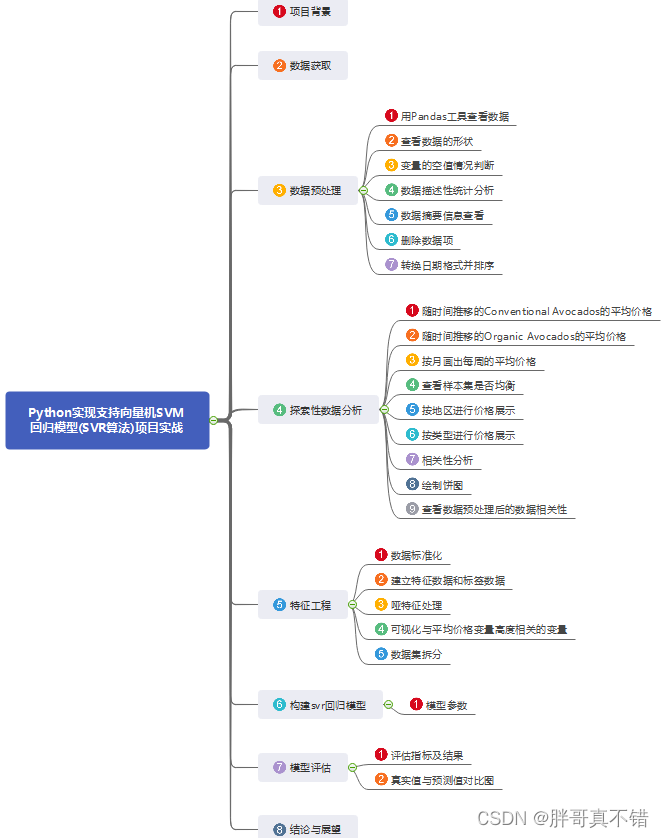
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
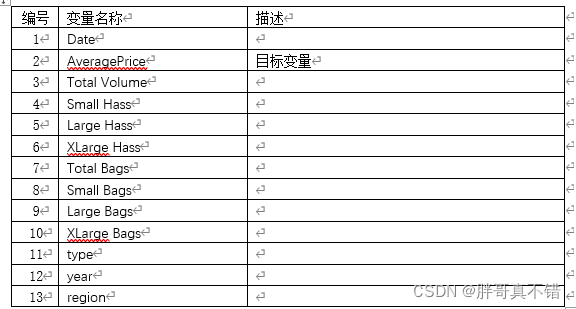
数据详情如下(部分展示):
3.数据预处理
真实数据中可能包含了大量的缺失值和噪音数据或人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、数据挖掘等使用。数据预处理通常包含数据清洗、归约、聚合、转换、抽样等方式,数据预处理质量决定了后续数据分析挖掘及建模工作的精度和泛化价值。以下简要介绍数据预处理工作中主要的预处理方法:
3.1 用Pandas工具查看数据
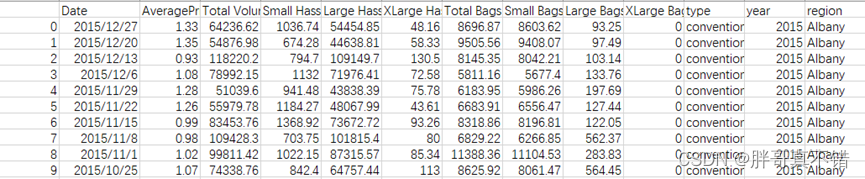
使用Pandas工具的head()方法查看前五行数据:
从上图可以看到,总共有14个字段:变量13个,其中第一列是一个索引,建模时我们要去掉它。
关键代码:
3.2查看数据的形状
使用Pandas工具的shape属性查看数据集的数量和字段数量:
从上图可以看到,总共有14个变量、数据量为18249条数据。
关键代码:
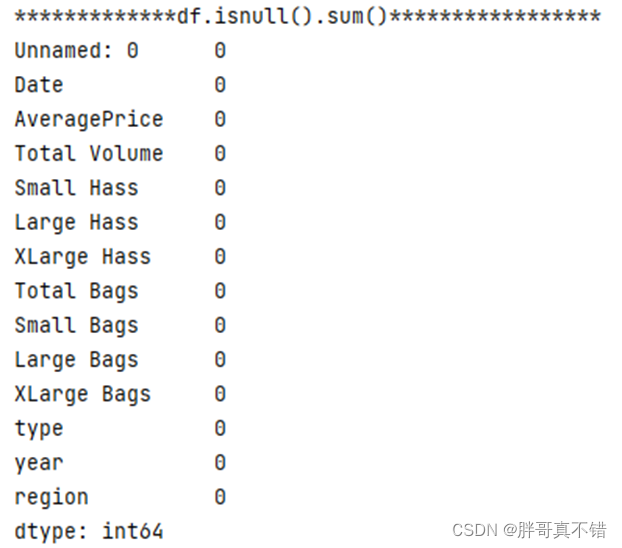
3.3变量的空值情况判断
通过Pandas工具的isnull().sum()方法来统计变量的空值情况,结果如下图:
通过上图可以看到,数据字段中无空值情况。
关键代码如下:
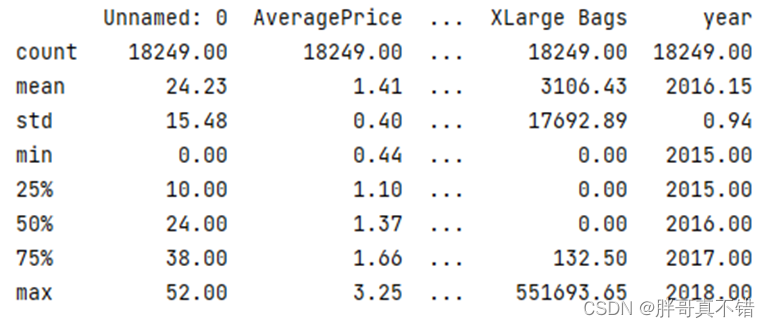
3.4数据描述性统计分析
通过Pandas工具的describe()方法来进行数据描述性统计分析,结果如下图:
通过上图可以看到,数据项的平均值、标准差、最小值、最大值以及分位数。
关键代码如下:
3.5数据摘要信息查看
通过Pandas工具的info()方法来进行查看数据摘要信息,结果如下图:
关键代码如下:
3.6删除数据项
删除掉Unnamed: 0数据项,关键代码如下:
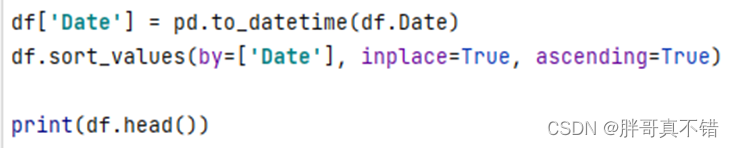
3.7转换日期格式并排序
关键代码如下:
针对排序后的数据进行查看:
4.探索性数据分析
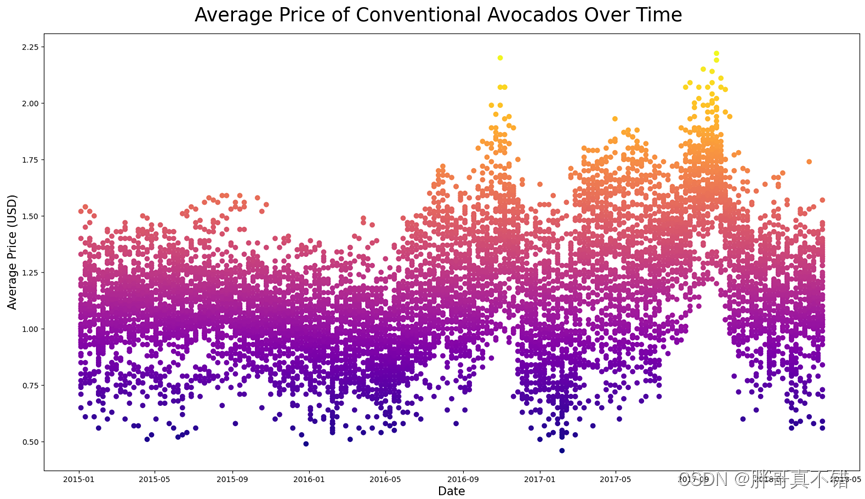
4.1 随时间推移的Conventional Avocados的平均价格
用Matplotlib工具的scatter()方法进行统计绘图,图形化展示如下:
从上图中可以看到,类型为conventional的Avocados的平均价格在2016年11月左右和2017年10月左右价格比较高。
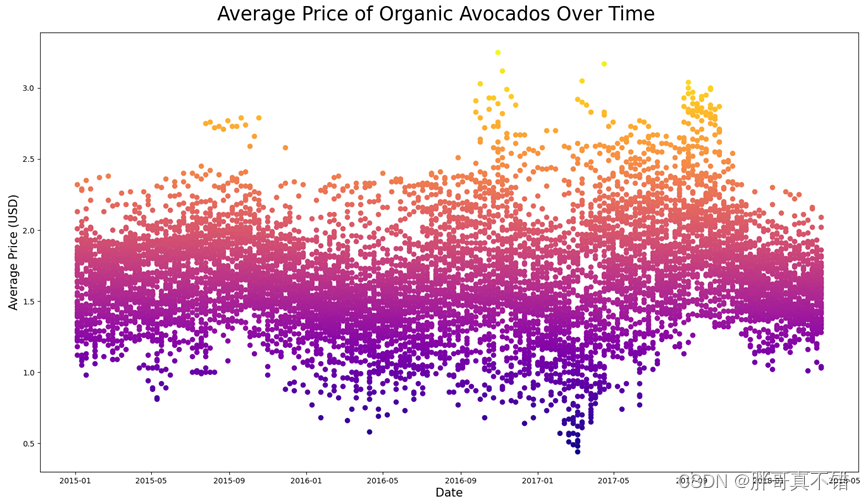
4.2 随时间推移的Organic Avocados的平均价格
从上图中可以看到,类型为Organic的Avocados的平均价格在2016年11月左右和2017年5月左右价格比较高。另外,通过4.1和4.2的图可以看到不同类型Avocados的平均价格,Organic类型的平均价格略高于conventional类型的平均价格。
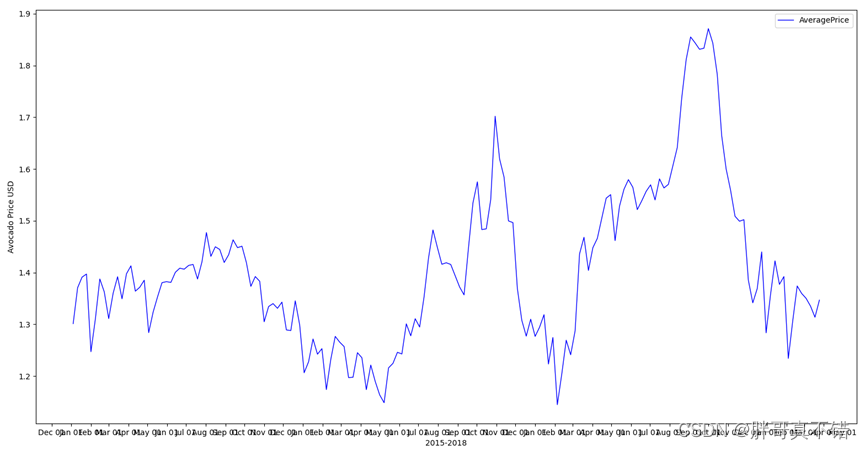
4.3 按月画出每周的平均价格
从上图中可以看到,分2017年9月、10月中每周的平均价格最高。
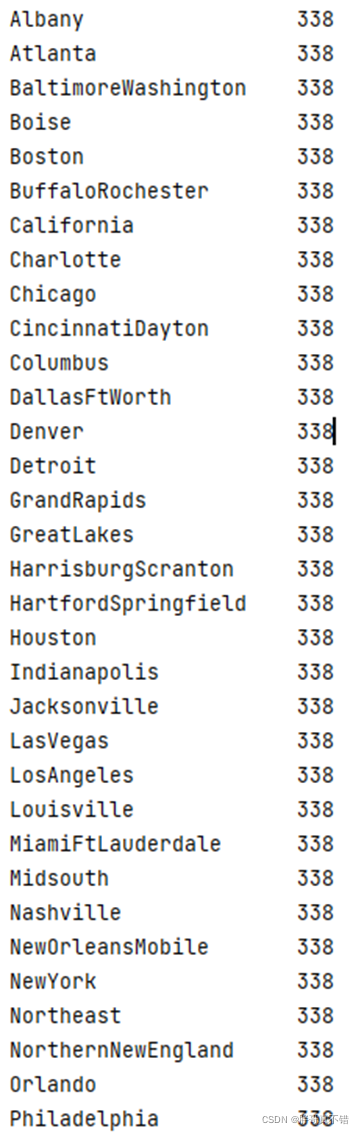
4.4 查看样本集是否均衡
从上图中可以看到,数据均为338,数据较为均衡。
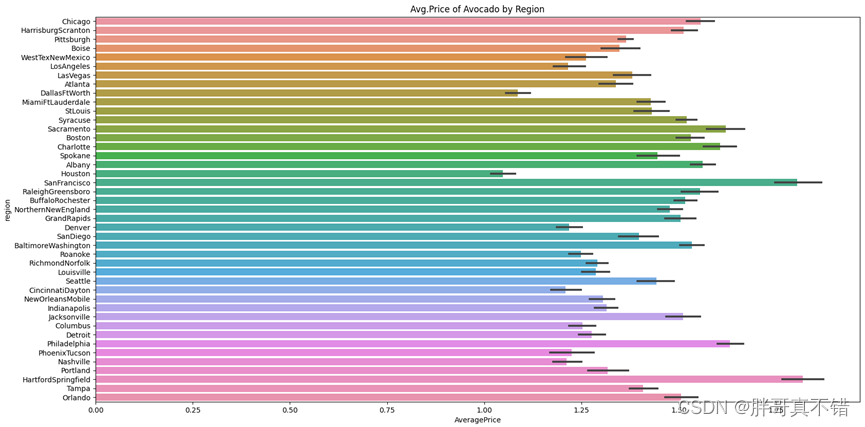
4.5 按地区进行价格展示
从上图中可以看到,HartfordSpringfield地区平均价格最高,Houston地区平均价格最低。
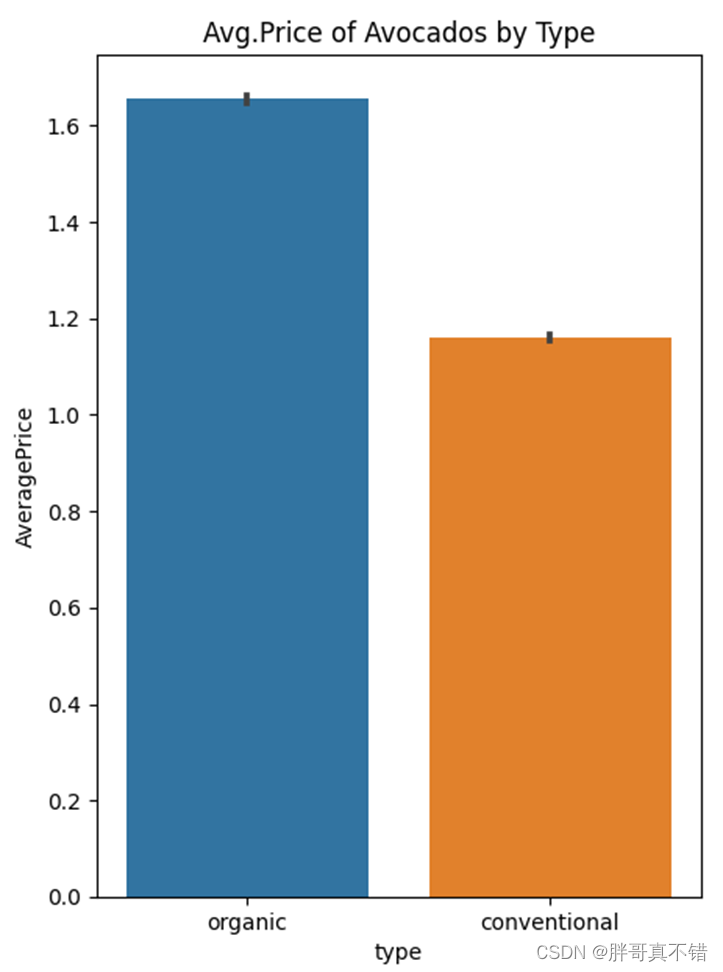
4.6 按类型进行价格展示
从上图可以看到organic类型的平均价格达到1.65,高于conventional类型的平均价格。
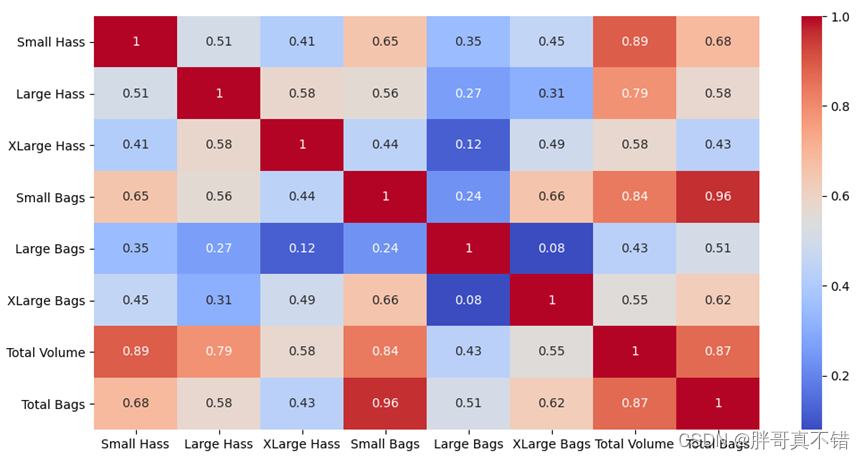
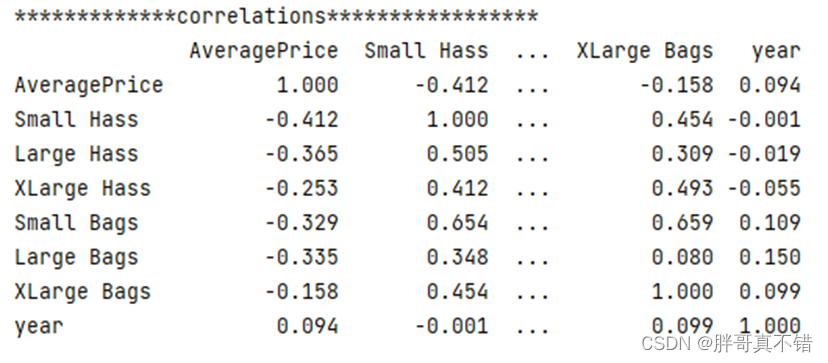
4.7 相关性分析
通过Pandas工具的corr()方法进行查看如下:
通过上图可以看到,数据项之间正直是正相关,负值为负相关;值越大相关性越强。
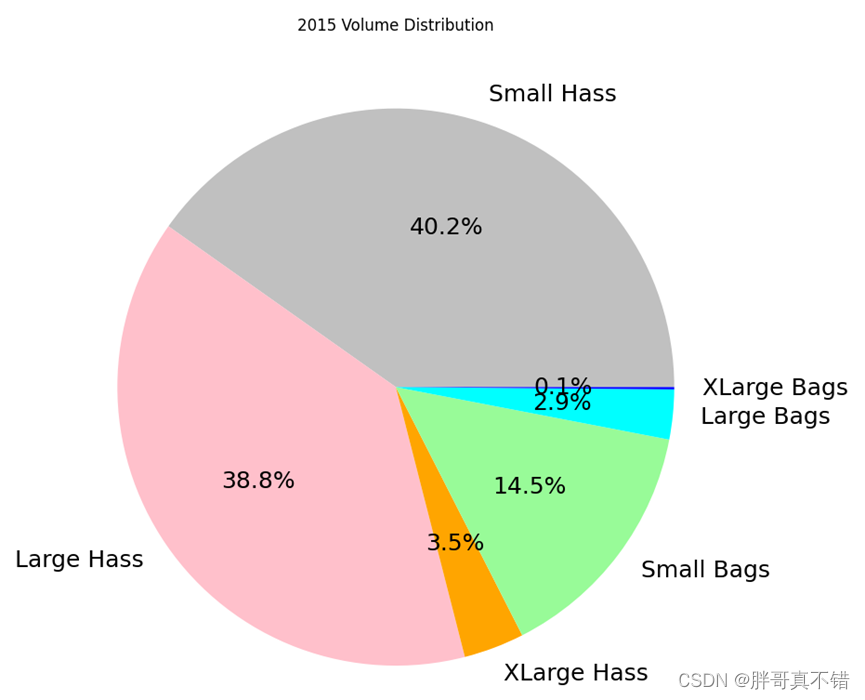
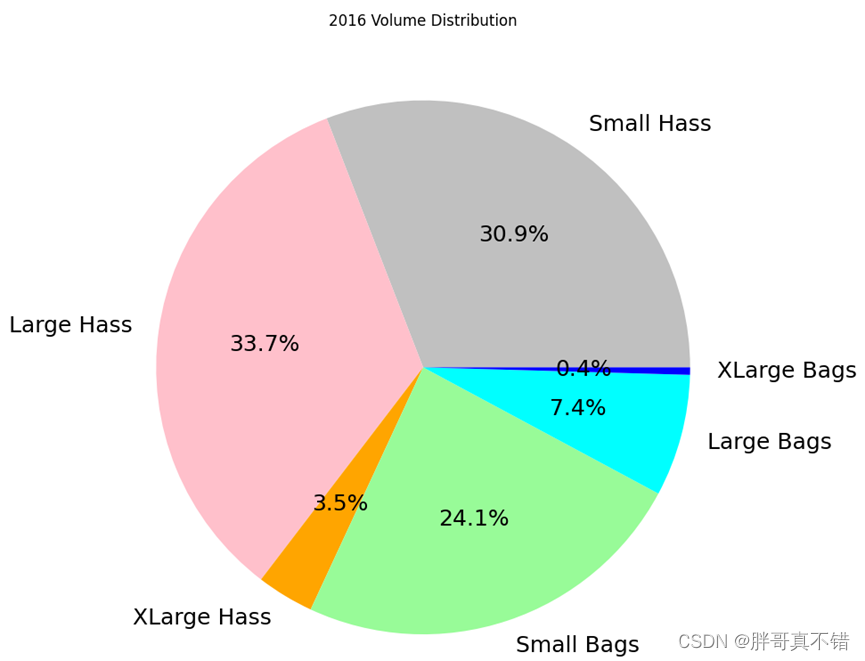
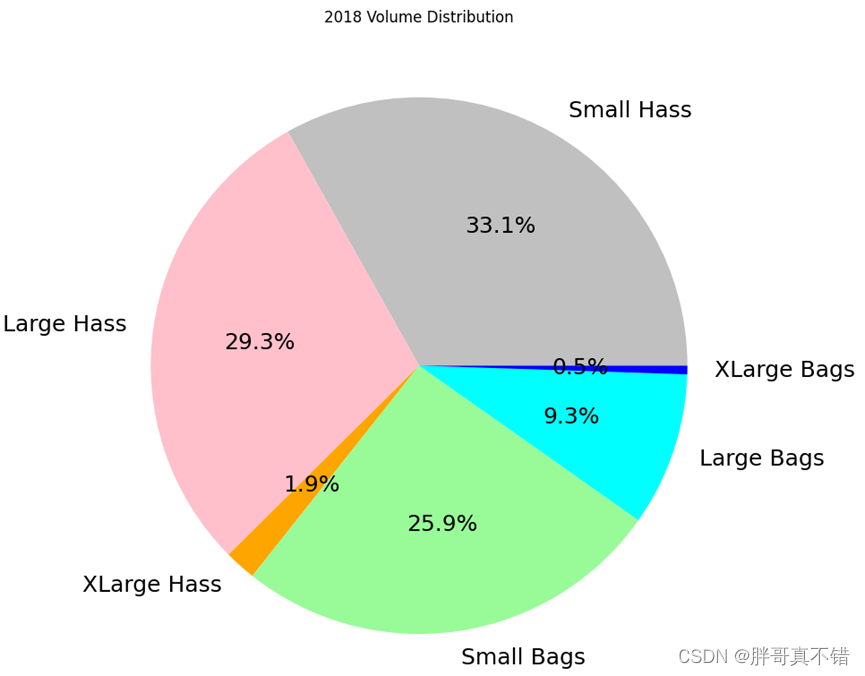
4.8绘制饼图
通过上图可以看到,2015年 SmallHass占比40.2% 占比最多;XLarge Bags占比0.1% 占比最少。
通过上图可以看到,2016年 SmallHass占比30.9% 占比最多;XLarge Bags占比0.4% 占比最少。
通过上图可以看到,2017年 SmallHass占比33.0% 占比最多;XLarge Bags占比0.5% 占比最少。
通过上图可以看到,2018年 SmallHass占比33.1% 占比最多;XLarge Bags占比0.5% 占比最少。
4.9查看数据预处理后的数据相关性
通过上图可以看到,数据预处理后的数据项相关性数值,正值为正相关,负值为负相关,数值越大相关性越强。
5.特征工程
5.1 数据标准化
对Small Hass:XLarge Bags的数据项进行数据的标准化处理,关键代码如下:
标准化的数据,如下图所示:
5.2 建立特征数据和标签数据
AveragePrice为标签数据,除 AveragePrice之外的为特征数据。关键代码如下:
5.3 哑特征处理
由于type, region数据项为分类型变量,且为本文类型,不符合机器学习建模要求;针对type, region进行哑特征处理,转变为数值型,关键代码如下:
转变后的结果,如下图所示:
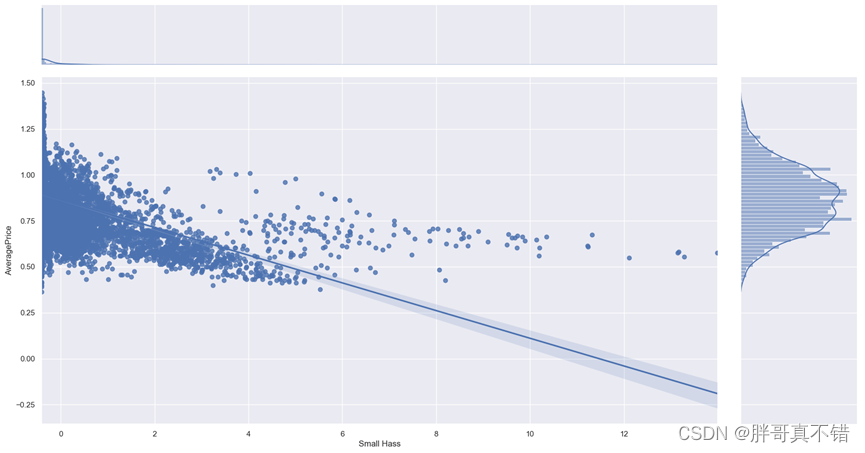
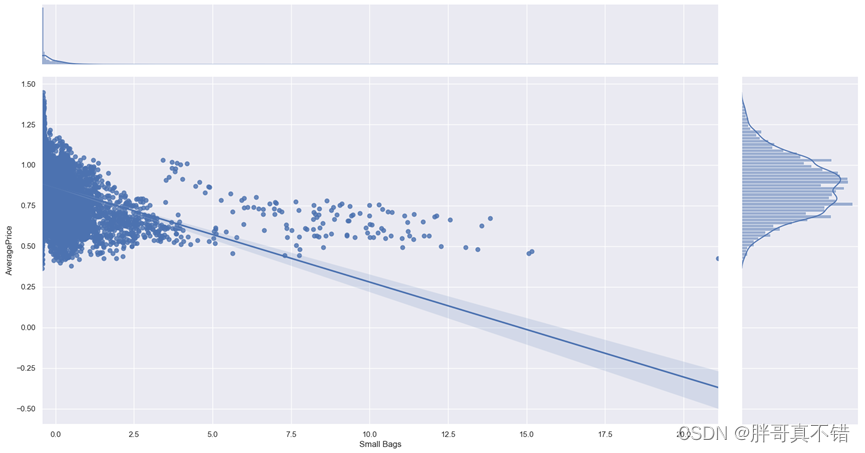
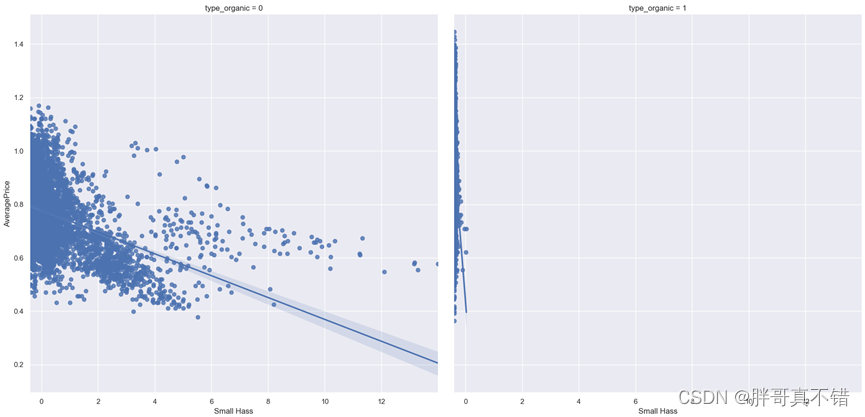
5.4 可视化与平均价格变量高度相关的变量
通过上图可以看出,随着Small Hass的增大,平均价格整体成下降趋势。
通过上图可以看出,随着Small Bags的增大,平均价格整体较为平稳。
通过上图可以看出,随着Large Bags的增大,平均价格整体较为平稳。
通过上图可以看出,organic类型相较于Conventional类型对平均价格影响较小。
5.5 数据集拆分
训练集拆分,分为训练集和验证集,70%训练集和30%验证集。关键代码如下:
6.构建SVR回归模型
主要使用svr算法,用于目标回归。
6.1模型参数
关键代码如下:
7.模型评估
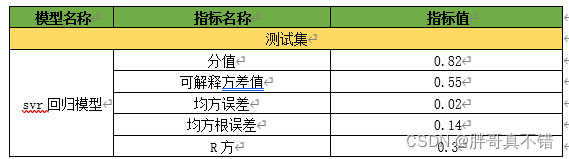
7.1评估指标及结果
评估指标主要包括分值、可解释方差值、均方误差、R方值等等。
从上表可以看出,分值0.82,svr回归模型良好。
关键代码如下:
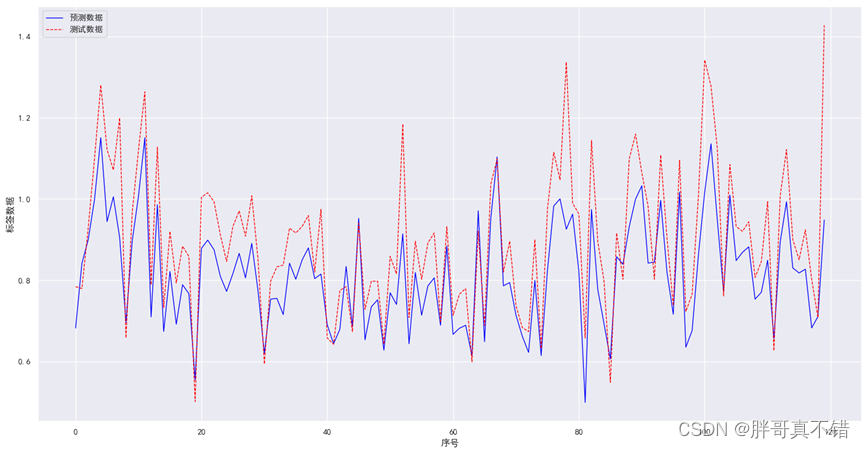
7.2 真实值与预测值对比图
从上图可以看出真实值和预测值波动基本一致,模型拟合效果良好。
8.结论与展望
综上所述,本文采用了svr回归模型,最终证明了我们提出的模型效果良好。可用于实际业务中建模预测。

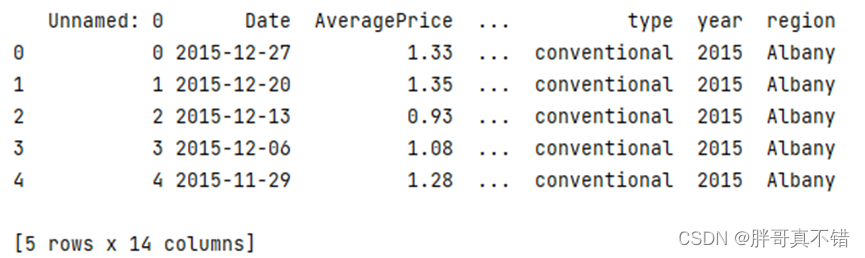





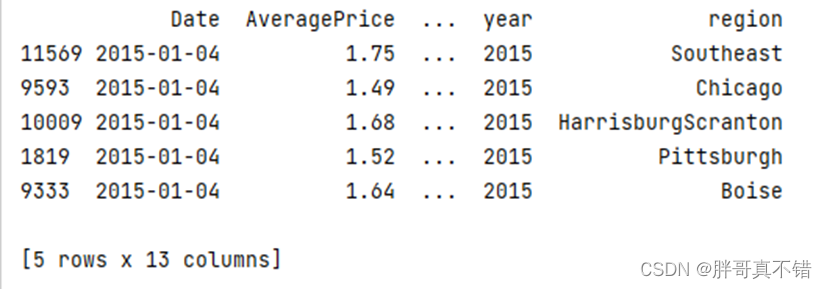








print('*************df.head()*****************') print(df.head()) # 查看数据的形状 print('*************df.shape*****************') print(df.shape) # 本次机器学习项目实战所需的资料,项目资源如下: 链接:https://pan.baidu.com/s/1oQEbg6-X6RyVl29uyLipdg 提取码:m7w4 # 变量的空值情况判断 print('*************df.isnull().sum()*****************') print(df.isnull().sum()) # 数据描述性统计分析 print('*************df.describe().round(2)*****************') print(df.describe().round(2)) # 数据摘要信息查看 print('*************df.info()*****************') print(df.info()) # 删除和重命名数据项 df = df.drop(['Unnamed: 0'], axis=1)


















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











