







简介:本教程详述了如何利用VC++进行光学字符识别(OCR),揭示了OCR技术的关键步骤和实现方法。通过分析VC++项目中的“VC汉字识别”,介绍了图像预处理、字符定位、特征提取和分类识别等核心流程。教程中还涉及了使用OpenCV库进行图像处理,以及如何集成Tesseract OCR引擎来提升字符识别的准确性和效率。 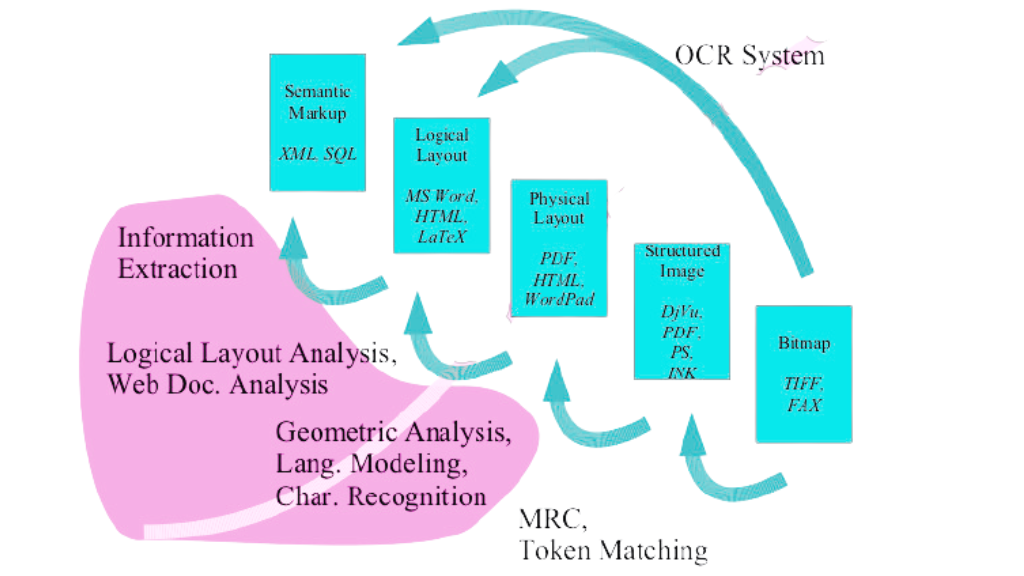
1. OCR技术概述
1.1 OCR技术简介
OCR(Optical Character Recognition)即光学字符识别技术,是将图片或扫描的文档中的文字转化为可编辑、可搜索的电子文档的过程。随着计算机视觉和机器学习的发展,OCR技术已经能够准确识别多种字体、字号和语言。
1.2 OCR技术的发展
最初,OCR技术仅限于简单文本的识别,其准确性和适应性较差。随着深度学习的应用,现在的OCR技术已经可以处理复杂的文本布局、表格、手写体和多种语言混合的文本,准确率有了大幅提升。
1.3 OCR技术的应用领域
OCR技术广泛应用于银行票据识别、车牌识别、证件扫描、图书数字化和历史文档的数字化等多个领域。它极大地提高了信息处理的效率,是自动化办公和数据采集的关键技术之一。
在下文中,我们将详细介绍如何在VC++环境中搭建OCR应用,以及如何进行图像预处理、特征提取和分类识别等关键步骤。
2. VC++在OCR中的应用
2.1 VC++环境搭建与配置
2.1.1 开发环境的准备
在开始使用VC++进行OCR应用开发之前,首先需要一个稳定的开发环境。Microsoft Visual C++ (MSVC) 是一个集成开发环境 (IDE),是进行Windows平台下C++开发的首选工具。以下是搭建VC++开发环境的基本步骤:
-
安装Visual Studio :下载并安装Visual Studio。在安装过程中,确保选择包含C++开发工具的安装选项。较新版本的Visual Studio已经集成了最新版本的MSVC编译器。
-
配置开发工具链 :安装完成后,打开Visual Studio,通过“工具”菜单选择“获取工具和功能”,在“工作负载”选项卡下选择C++桌面开发,并添加相关的组件。
-
配置项目设置 :创建一个新项目,选择适合的项目类型,如Win32控制台应用程序。在项目属性中,确保指定了正确的C++标准,如C++17或更高版本,以及选择合适的平台和配置(通常为x86或x64)。
-
安装和配置第三方库 :根据OCR项目的需求,可能需要安装如OpenCV等第三方图像处理库。在Visual Studio中,可以通过NuGet包管理器进行安装,并在项目中正确配置它们的包含目录和库目录。
2.1.2 相关库文件的引入
在VC++中使用第三方库,如Tesseract OCR库,需要正确地引入它们的头文件和库文件。以Tesseract为例,需要进行以下操作:
-
下载Tesseract :访问Tesseract的GitHub仓库,下载适用于Windows的预编译二进制文件和相应的头文件。
-
配置项目以包含Tesseract :在项目属性中,配置包含目录和库目录以包含Tesseract头文件和库文件。在链接器设置中,添加Tesseract库文件到附加依赖项中。
-
配置运行时库 :确保项目配置中设置了正确的运行时库版本。通常,你可以使用多线程调试 (/MDd) 或多线程 (/MD) 版本。
-
示例代码 :编写示例代码以测试Tesseract库是否正确集成。例如,使用Tesseract的API来执行基本的OCR操作。
```cpp #include #include
int main() { tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI(); if (ocr->Init(NULL, "eng")) { fprintf(stderr, "Could not initialize tesseract.\n"); exit(1); }
Pix *image = pixRead("/path/to/image.png");
ocr->SetImage(image);
char *text = ocr->GetUTF8Text();
printf("%s", text);
delete[] text;
pixDestroy(&image);
ocr->End();
return 0;
} `` 在上述代码中,我们首先包含了Tesseract和Leptonica库的头文件。然后在 main 函数中,我们创建了一个Tesseract实例,并尝试用英语数据集初始化它。之后,读取一张图片并使用 SetImage 方法传递给Tesseract实例,通过 GetUTF8Text`方法提取图片中的文本。最后,输出识别结果并进行清理工作。
2.2 VC++与图像处理
2.2.1 图像数据结构的处理
在VC++中,处理图像数据通常需要使用适合的图像处理库,如OpenCV。OpenCV中的图像数据结构为 cv::Mat ,它是一个多维数组,用于存储图像数据。下面是一些基本操作:
- 加载和显示图像 : ```cpp #include using namespace cv;
int main() { Mat image = imread("path/to/image.jpg"); if(image.empty()) { printf("Cannot read image \n"); return -1; }
namedWindow("Display window", WINDOW_AUTOSIZE);
imshow("Display window", image);
waitKey(0); // Wait for a keystroke in the window
return 0;
} `` 在此代码中,我们使用 imread 函数加载了一张图片到 Mat 对象中。如果图片加载成功,则使用 imshow`函数显示图片,等待用户按键操作后退出。
- 图像像素的访问和修改 :
cpp for (int y = 0; y < image.rows; y++) { for (int x = 0; x < image.cols; x++) { Vec3b pixel = image.at<Vec3b>(y, x); pixel[0] = 0; // Set Blue channel to 0 image.at<Vec3b>(y, x) = pixel; } } 通过 at 方法我们可以访问和修改 Mat 对象中的像素值。 Vec3b 是指向三个字节(代表BGR三个颜色通道)的指针。在上面的代码中,我们遍历了图像的每一个像素,并将其蓝色通道的值设置为0。
2.2.2 图像处理中的内存管理
在进行图像处理时,内存管理是一个不可忽视的问题。高效的内存管理能够保证程序运行的稳定性和性能。
-
使用智能指针 :为了避免内存泄漏,在VC++中推荐使用智能指针如
std::shared_ptr和std::unique_ptr。 -
资源释放 :确保创建的所有资源在不再使用时被正确释放。例如,读取图像后,使用
imwrite保存图像并使用destroyAllWindows释放OpenCV创建的窗口资源。 -
避免使用全局变量 :全局变量会延长对象的生命周期,应该尽量避免使用。使用局部变量并在作用域结束时自动销毁。
-
图像复制与克隆 :在需要操作图像副本时,使用
clone方法代替复制构造函数,以避免不必要的内存复制。
cpp Mat imageCopy = image.clone(); 在这里, image 的一个完整克隆被创建,并被赋给 imageCopy ,原图像与克隆图像在内存中占据不同的位置。
代码块解析和参数说明
每个代码块中所使用的函数和方法都应当有相应的注释,以解释代码的功能和行为。参数说明可以帮助开发者理解每个参数的含义和如何选择合适的参数值。例如,在Tesseract的初始化过程中:
if (ocr->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
在这段代码中, Init 方法用于初始化Tesseract对象。第一个参数为NULL,表示使用Tesseract默认的配置文件。第二个参数"eng"指定了需要使用的语言数据文件。
在操作图像像素的代码中:
for (int y = 0; y < image.rows; y++) {
for (int x = 0; x < image.cols; x++) {
Vec3b pixel = image.at<Vec3b>(y, x);
pixel[0] = 0; // Set Blue channel to 0
image.at<Vec3b>(y, x) = pixel;
}
}
在这段代码中, rows 和 cols 分别代表了图像的高度和宽度。 at<Vec3b> 方法用于访问特定像素值,而 Vec3b 是一个用于存储三个字节值的向量,代表了BGR颜色空间中的颜色值。
以上章节中,我们介绍了如何在VC++中搭建和配置开发环境,如何引入和使用相关库文件,以及如何进行图像数据结构的处理和内存管理。这些都是进行OCR应用开发的基础,而深入理解这些内容对于后续开发中图像预处理和字符定位、特征提取与分类识别以及OCR实战项目中的应用至关重要。
3. 图像预处理与字符定位
3.1 图像预处理方法
3.1.1 去噪技术
在图像预处理中,去噪是一个关键步骤,它的目的是去除图像中的噪点,提高图像质量,为后续的字符识别提供清晰的图像数据。常见的去噪技术包括均值滤波、中值滤波、高斯滤波和双边滤波等。
均值滤波是一种简单的去噪方法,通过计算图像中每个像素点周围邻域的平均值来代替该像素点的值。这种方法可以有效减少图像中的随机噪声,但可能会导致图像边缘的模糊。
// C++ 代码示例:均值滤波去噪
Mat applyMeanFilter(Mat src, int kernelSize) {
Mat dst;
// 创建均值滤波器核
Mat kernel = Mat::ones(kernelSize, kernelSize, CV_32F) * (1.0 / (kernelSize * kernelSize));
// 应用均值滤波器
filter2D(src, dst, -1, kernel);
return dst;
}
中值滤波则利用了图像中邻域像素值的中值来代替中心像素,它对于去除椒盐噪声尤其有效,同时也能在一定程度上保持图像的边缘信息。
高斯滤波是一种根据高斯函数进行加权平均的去噪方法,它对于去除高斯噪声非常有效。高斯滤波可以处理不同大小的图像噪声,但与均值滤波类似,边缘信息可能会受到影响。
// C++ 代码示例:高斯滤波去噪
Mat applyGaussianFilter(Mat src, int kernelSize, double sigmaX) {
Mat dst;
// 使用高斯滤波器
GaussianBlur(src, dst, Size(kernelSize, kernelSize), sigmaX);
return dst;
}
双边滤波是近年来较为流行的一种滤波技术,它在保持边缘信息的同时去除噪声,代价是计算量相对较大。
3.1.2 二值化处理
二值化是将图像像素值从灰度空间转换到二值空间的过程,即将图像中所有的像素值量化为0和255。在OCR中,二值化可以帮助我们更容易地区分文字和背景,提高文字的可识别性。
在进行二值化之前,通常会先对图像进行标准化处理,确保图像的亮度和对比度达到最优状态。之后,可以应用Otsu算法自动计算最佳的阈值。
// C++ 代码示例:Otsu二值化处理
Mat applyOtsuThresholding(Mat src) {
Mat dst;
// 将图像转换为灰度图
Mat gray;
cvtColor(src, gray, COLOR_BGR2GRAY);
// 应用Otsu算法自动计算最佳阈值
double threshold = threshold(gray, dst, 0, 255, THRESH_BINARY | THRESH_OTSU);
return dst;
}
3.2 字符定位策略
3.2.1 边缘检测与轮廓识别
字符定位指的是在预处理后的图像中,确定字符的位置。这通常依赖于边缘检测和轮廓识别技术。边缘检测的目的是找到字符的边界,而轮廓识别则用于提取出字符的实际形状。
边缘检测中较为常用的算法包括Sobel算法、Canny算法等。Sobel算法通过计算图像亮度的一阶导数来检测边缘,而Canny算法则是一个多阶段的边缘检测算法,它在检测边缘时会先进行高斯模糊,然后使用两个不同方向的滤波器检测水平和垂直边缘,最后进行非极大值抑制和滞后阈值化。
// C++ 代码示例:Canny边缘检测
Mat applyCannyEdgeDetection(Mat src, double threshold1, double threshold2) {
Mat dst;
// 应用高斯模糊减少噪声
GaussianBlur(src, src, Size(5, 5), 1.0);
// 应用Canny边缘检测算法
Canny(src, dst, threshold1, threshold2);
return dst;
}
3.2.2 连通区域分析
连通区域分析是一种用于识别图像中相互连接的像素点集的方法,通过它可以分离出独立的字符或文字块。在二值化图像中,字符通常表现为连通区域。
为了实现连通区域分析,首先需要对图像进行二值化处理,然后使用findContours函数检测并获取图像中所有的轮廓。根据轮廓特征,可以进一步筛选出目标字符的轮廓。
// C++ 代码示例:连通区域分析
void findConnectedComponents(Mat src) {
Mat binary;
// 二值化处理
cvtColor(src, binary, COLOR_BGR2GRAY);
threshold(binary, binary, 127, 255, THRESH_BINARY_INV);
// 查找连通区域的轮廓
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(binary, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
// 绘制轮廓
Mat contourOutput = src.clone();
drawContours(contourOutput, contours, -1, Scalar(0, 255, 0), 2);
imshow("Connected Components", contourOutput);
waitKey(0);
}
在上述示例代码中, findContours 函数用于检测二值图像中的轮廓,并将它们存储在 contours 变量中。函数的输出参数 hierarchy 用于存储轮廓之间的层次关系。根据这些轮廓信息,可以进一步分析和识别字符。
通过结合边缘检测和连通区域分析技术,可以有效地定位OCR处理中的字符,为接下来的特征提取和分类识别打下良好的基础。
4. OCR中的特征提取与分类识别
4.1 特征提取技巧
4.1.1 特征点的提取方法
特征点提取是光学字符识别(OCR)中一个关键步骤,它涉及到识别图像中那些最能代表字符形状的部分。现代的OCR技术通常会运用一些先进的图像处理算法来确定这些点。
算法分析:
-
角点检测 :这是一种常用的特征点提取方法,角点是图像中具有独特性质的位置,常见算法包括Harris角点检测算法和Shi-Tomasi角点检测算法。角点检测算法通常会评估图像中的每个像素点,寻找具有最大变化率的位置。
-
尺度不变特征变换(SIFT) :SIFT算法能够检测并描述局部特征。它对旋转、尺度缩放、亮度变化甚至视角变化等保持不变性,适合于处理图像中的局部特征。
-
快速鲁棒特征(ORB) :ORB是一种改进的特征检测器和描述符,它是基于FAST角点检测器和BRIEF描述符的优化版本。ORB在速度上进行了优化,非常适合实时或资源受限的应用。
代码实现:
import cv2
import numpy as np
# 图像预处理
image = cv2.imread('image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# ORB特征点检测
orb = cv2.ORB_create()
keypoints, descriptors = orb.detectAndCompute(gray, None)
# 绘制关键点
result = cv2.drawKeypoints(image, keypoints, None, color=(0, 255, 0), flags=0)
cv2.imshow('ORB Features', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中,我们使用了ORB算法来检测图像中的特征点,并将这些点绘制在原始图像上。这有助于我们理解哪些部分被算法认定为特征点。
4.1.2 特征向量的构造
特征向量是将提取的特征点转换成可被机器学习算法使用的数值形式。特征向量通常是一个多维数组,数组的每一维代表图像中的一个特征。
特征向量构建步骤:
-
特征点描述 :对每个检测到的特征点使用描述符进行编码,描述符能够捕捉到特征点周围的局部信息。常见的描述符有BRIEF、BRISK等。
-
向量转换 :将图像的像素值转化为一组数值,这些数值反映了图像的几何和统计特性。例如,从图像的灰度共生矩阵(Grey Level Co-occurrence Matrix, GLCM)中提取纹理特征。
-
标准化 :对特征向量进行标准化处理,使得不同特征之间可以进行比较。常用的方法有Z-score标准化和L2范数归一化。
代码实现:
# 以BRIEF描述符为例,构建特征向量
# 假设已经有了关键点的关键点列表
# 初始化BRIEF检测器
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create()
# 计算描述符
_, descriptors = brief.compute(gray, keypoints)
# 标准化描述符
descriptors = descriptors / np.linalg.norm(descriptors, ord=2, axis=1, keepdims=True)
在该代码块中,我们使用OpenCV的xfeatures2d模块中的BRIEF算法来生成描述符,并通过归一化操作对特征向量进行了标准化处理。
4.2 分类识别技术
4.2.1 机器学习算法的选择
分类识别是OCR技术中的核心环节,负责将提取出的特征向量识别为具体的字符。在机器学习领域,有许多算法可以用于分类任务。
常用算法:
-
支持向量机(SVM) :SVM算法在小规模数据集上表现优秀,对于二分类任务非常有效,但当数据维度很高时会遇到困难。
-
随机森林 :随机森林是一种集成学习方法,它构建多个决策树并合并结果以提高准确率和防止过拟合。
-
深度学习 :随着计算能力的提升,深度学习在图像识别方面取得了突破性进展,尤其是卷积神经网络(CNN),在处理复杂图像和大规模数据集方面显示出巨大优势。
技术比较:
-
SVM适合于特征数量较少、数据集不大的情况。
-
随机森林能够处理大量的特征和更大的数据集,但在数据量大时训练速度较慢。
-
深度学习,尤其是CNN,需要大量数据和计算资源,但通常在识别准确率上表现更优。
4.2.2 训练数据集的准备
训练数据集是机器学习模型学习的基础,对于分类识别效果的好坏有着决定性的影响。
数据集准备步骤:
-
数据收集 :收集大量高质量的图像,并对这些图像进行标注。标注工作包括标注图像中的每个字符的位置以及类别。
-
数据增强 :对图像进行一系列的转换,如旋转、缩放、裁剪等,以增加数据集的多样性和泛化能力。
-
数据分割 :将数据集划分为训练集、验证集和测试集,通常比例为70:15:15或80:10:10。
代码实现:
# 以数据增强为例,使用imgaug库进行数据增强
import imgaug.augmenters as iaa
seq = iaa.Sequential([
iaa.Affine(rotate=(-20, 20)),
iaa.Sometimes(0.5, iaa.GaussianBlur(sigma=(0, 0.5))),
iaa.Fliplr(0.5) # 水平翻转
])
images_aug = seq.augment_images(images) # images为原始图像列表
这段代码使用了imgaug库来对图像进行一系列的变换,从而得到增强后的图像数据,这有助于提升模型在不同情况下的识别准确性。
以上内容针对“OCR中的特征提取与分类识别”章节中的特征提取技巧和分类识别技术进行了详细的介绍和代码实践。特征点提取和特征向量构造是数据准备的关键步骤,而分类识别技术的选择和数据集的准备则是模型训练的基础。通过这些技术的应用与优化,OCR系统能够更好地识别和理解图像中的文字信息。
5. OCR实战项目中的OpenCV与Tesseract应用
在当今的OCR(光学字符识别)项目中,OpenCV和Tesseract已经成为业界标准的工具库,尤其在开源社区中广受欢迎。本章将深入探讨如何在实战项目中有效地应用OpenCV进行图像处理,以及如何集成和优化Tesseract OCR引擎。
5.1 OpenCV和Tesseract OCR库的使用
OpenCV是一个开源的计算机视觉和机器学习软件库,它提供了大量的图像处理功能。Tesseract则是一个开源的OCR引擎,它能够识别多种语言的文字,并可以被定制以识别特定的文字样式。
5.1.1 OpenCV基础功能介绍
OpenCV提供了一系列的图像处理函数,例如滤波、形态操作、特征检测、物体检测等。下面是一个简单的代码示例,展示了如何使用OpenCV读取图像并进行基本的处理。
import cv2
# 读取图像
image = cv2.imread('example.jpg')
# 转换为灰度图
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 显示图像
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray_image)
cv2.imshow('Blurred Image', blurred_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.1.2 Tesseract的安装与环境配置
Tesseract的安装和配置比较直接。以下是在大多数基于Linux的系统上安装Tesseract的步骤。
sudo apt update
sudo apt install tesseract-ocr
安装完成后,需要设置环境变量以便能够从命令行或编程环境中调用Tesseract。
5.2 图像读取与预处理流程
处理OCR任务时,图像预处理是一个关键步骤,它可以显著地提升OCR的识别准确率。
5.2.1 图像的读取与格式转换
图像的读取和格式转换是预处理的第一步,这可以通过OpenCV或Python的PIL库完成。
from PIL import Image
# 使用PIL读取图像并转换格式
image = Image.open('example.jpg')
gray_image = image.convert('L')
# 使用OpenCV读取图像
import cv2
image_cv = cv2.imread('example.jpg')
gray_image_cv = cv2.cvtColor(image_cv, cv2.COLOR_BGR2GRAY)
5.2.2 自动化预处理流程设计
自动化预处理流程通常包括二值化、去噪、缩放和旋转校正等步骤。
def preprocess_image(image_path):
# 读取图像
image = cv2.imread(image_path)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊去噪
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 二值化
_, binary_image = cv2.threshold(blurred_image, 128, 255, cv2.THRESH_BINARY)
return binary_image
processed_image = preprocess_image('example.jpg')
5.3 Tesseract OCR集成与配置
集成Tesseract到OCR项目中,并进行配置以满足特定需求,是实现高准确率的关键。
5.3.1 Tesseract接口调用
Tesseract提供了命令行接口和API两种方式,下面是一个使用Python调用Tesseract API的示例。
import pytesseract
# 对处理后的图像使用Tesseract进行文字识别
text = pytesseract.image_to_string(processed_image, lang='eng')
print(text)
5.3.2 OCR引擎配置与优化
配置Tesseract以适应不同的使用场景需要调整其参数。以下是一些常见的优化配置。
from pytesseract import Output
config = r'--oem 3 --psm 6 outputbase digits'
custom_config = r'-l eng --oem 3 --psm 6'
# 运行Tesseract
custom_text = pytesseract.image_to_string(processed_image, config=custom_config, output_type=Output.DICT)
print(custom_text['text'])
5.4 OCR后处理及校正
OCR引擎识别后的文本通常需要进一步处理,以便于最终使用。
5.4.1 识别结果的后处理方法
后处理可能包括去除噪声字符、纠正拼写错误等。
# 去除结果中的常见噪声字符
def clean_text(ocr_result):
result = ''.join(e for e in ocr_result if e.isalnum() or e.isspace())
return result
cleaned_text = clean_text(text)
print(cleaned_text)
5.4.2 字符校正技术与实例分析
字符校正技术可以使用机器学习算法进行更深层次的校正。
# 示例:使用字典进行简单的拼写校正
corrector = {
'tezt': 'text',
'te4t': 'test'
}
def spell_corrector(ocr_text):
return ' '.join(corrector.get(word, word) for word in ocr_text.split())
spell_corrected_text = spell_corrector(cleaned_text)
print(spell_corrected_text)
通过上述步骤,我们可以将一个原始的图像转换为格式化好的文本文件,而这一切都可以在自动化处理流程中完成。重要的是,在任何项目中,不断地测试和调整算法参数是至关重要的,以获得最佳的识别结果。
简介:本教程详述了如何利用VC++进行光学字符识别(OCR),揭示了OCR技术的关键步骤和实现方法。通过分析VC++项目中的“VC汉字识别”,介绍了图像预处理、字符定位、特征提取和分类识别等核心流程。教程中还涉及了使用OpenCV库进行图像处理,以及如何集成Tesseract OCR引擎来提升字符识别的准确性和效率。

















 3193
3193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









