







损失函数:预测值(y)与标准答案(y-)的差距
损失函数可以定量判断权重w和随机初始化b的优劣,当损失函数输出最小时,w、b最优
常见损失函数:均方误差 其中n为样本个数
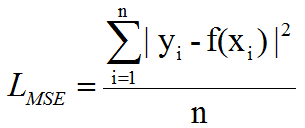
梯度下降法:沿损失函数梯度下降的方向,寻找损失函数的最小值,找到最参数的方法(w、b)
梯度下降的方向就是参数减小的方向 ,梯度:函数对各参数求偏导后的向量
目的:找到一组参数b和w,使得损失函数最小
学习率(learing rate, lr):是超参数,即开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,如果lr设置过小,收敛过程慢,如果lr设置过大,可能跳过最小值,在最优解附近来回震荡,设置无法收敛



例子:
import tensorflow as tf
w = tf.Variable(tf.constant(5, dtype=tf.float32))
lr = 0.5
epoch = 40
for epoch in range(epoch):
with tf.GradientTape() as tape:
loss = tf.square(w+1)
grads = tape.gradient(loss, w)
w.assign_sub(lr*grads)
print("After %s epoch, w is %f,loss is %f" % (epoch, w.numpy(), loss))















 3911
3911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









