







TRPO——Trust Region Policy Optimization置信域策略优化算法
TRPO要解决的是AC网络在沿着策略梯度更新参数,很有可能会因为步长太长导致策略限制变差,进而影响训练效果。TRPO可以解决该问题,通过置信域俩控制步长,通过引入每一幕的回报总望,判断新策略的优劣。TRPO是一种改进的自然梯度策略优化算法,通过限制KL散度(或策略改变范围)来避免每次迭代中,参数过大的变化。
TRPO的优化目标是最小化当前策略与最优策略之间的KL散度,同时最大化新策略的期望回报,并且保证新的策略在信任域内。在每次迭代中,TRPO算法都会评估旧策略π旧的性能。这通常是通过在环境中收集样本数据并计算其平均回报来完成的。根据旧策略的性能,算法会确定一个新的信任域半径。这个半径通常与旧策略的性能成正比。如果旧策略的性能良好,信任域半径会较大,允许较大的策略更新;如果性能不佳,半径会较小,限制较大的更新。
优势函数:
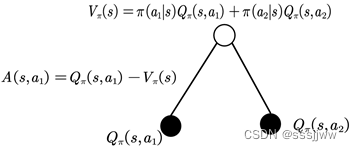
值函数可以理解为:在该状态S下所有可能动作所对应的动作值函数乘以采取该动作的概率的和,即所有动作值函数关于动作概率的平均值。动作函数
是单个动作所对应的值函数,
能评价当前动作函数相对于平均值的大小。
假设表示策略
的参数,
是状态价值函数,
是目标函数:
找到,策略梯度算法主要沿着
方向迭代更新策略参数
假设当前的目标策略,参数为
,需要借助当前的
找到一个更好的参数
,使得
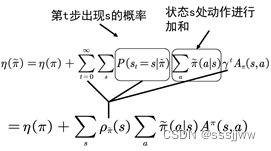
改动一:忽略状态分布的变化,采用旧的策略所对应的状态分布,原因:当新旧参数很接近时,可以用旧的状态分布替代新的状态分布,修改后:
改动二:利用重要性采样(从与原分布不同的另一个分布中采样,而对原先分布的性质进行估计。)对动作分布进行处理,改动后表示为:
、
将S求和的形式写成期望能够,则函数表示为:
KL散度:
KL散度作为两个分布之间的有向差异衡量,用来衡量一个概率分布P(实际分布)与另一个概率分布Q(假设分布)之间的差异,它反映了从P到Q的信息量。KL散度的值总是非负的,当且仅当Q为P的分布时,KL散度为0。

对比:
发现:两个公式的区别在于分布不同,他们都是关于的函数,可以用KL散度表示两个分布之间的差异:
下限:,
在实际中,如果用C来作为惩罚项的系数,步长会变得非常小,一种可以保证更新稳定的前提下采取较大步长的方法是在新旧策略的KL散度上施加约束。
KL散度的上限很难获得,一般情况下可以用平均KL散度来代替
看不懂了......
重点应该是信任域的半径的选择:

算法步骤:
初始化策略网络参数和价值网络参数
for 序列 ,do:
基于当前策略采样轨迹
根据收集到的数据和价值网络估计每个状态动作对的优势函数
计算策略目标函数的梯度
用共轭梯度法计算
用线性搜索到一个i值,并更新策略网络参数,其中
为能提升策略并满足KL距离限制的最小整数
更新价值网络参数
end for

TRPO的优势:
①性能好,能够有效学习复杂策略
②稳定性强,不易陷入局部最优
③易于实现
TRPO的劣势:
①计算复杂度较高
②需要设置超参数,随性能影响较大















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









