






1、Adaboost算法
Adaboost算法是一种集成学习方法,通过结合多个弱学习器来构建一个强大的预测模型。核心思想:如果一个简单的分类器在训练数据上犯错误,那么它在测试数据上也可能犯错误。
Adaboost通过迭代地训练一系列的分类器,并为每次训练选择训练数据的子集,从而使得每个分类器在训练数据上的错误率最小化。
算法步骤
1.1 分配每个观测样本
,一个初始权重
,
,其中n为样本总量数。
1.2 训练一个“弱模型”(常用决策树)
1.3 对于每个目标:
1.3.1 如果预测错误,
1.3.2 如果预测正确,
1.4 训练一个新的“弱模型”,其中权重较大的观测样本相应分配较高的优先权
1.5 重复步骤三和四,直到得到样本被完美预测,或是训练处当前规模的决策树
优点:
1、提高准确率:通过集成多个弱分类器,Adaboost可以显著提高预测的准确率,尤其是在处理复杂和非线性问题时。
2、处理不平衡数据:Adaboost能够自动调整每个分类器的权重,以对错误率的类别给予更多的关注,这有助于提高少数类的分类性能。
3、对异常值不敏感:由于Adaboost会根据错误率来调整权重,异常值的影响会被减少。
4、模型透明度高:Adaboost可以提供每个弱分类器的权重,这使得模型易于解释和理解。
缺点:
1、过拟合风险:如果弱分类器的选择不当或者迭代次数过多,Adaboost可能会导致过拟合,尤其是在数据量较小的情况下。
2、计算成本:由于需要训练多个弱分类器,Adaboost的计算成本较高,尤其是在大模型数据集上。
3、弱学习器选择:Adaboost的效果很大程度上取决于所选的弱学习器,如果弱学习器选择不当,Adaboost可能无法达到预测的性能。
4、对噪声敏感:Adaboost可能会对噪声数据敏感,因为噪声数据可能会导致某些分类器权重过高,从而影响最终预测。
5、解释性差:尽管Adaboost提供每个弱分类器的权重,但整个集成模型的解释性仍然不如单个决策树或线性模型。
6、依赖正则化:Adaboost依赖于正则化来防止过拟合,这意味着模型可能会在测试集上表现不佳。
2、拟合度:调整R方
是一个统计量,用于衡量线性回归模型对观测数据的拟合程度,特别是在模型中包含多个自变量时,调整R方考虑了模型中自变量的数量,从而避免了模型过渡拟合的风险。
RSS:残差平方和
TSS:总平方和
n:观测值
d:特征值
的取值范围是从0到1,
只反映了模型解释变异的能力,它并不考虑模型的复杂度。
当为0时,表示模型没有解释任何因变量的变异,即模型完全不能预测因变量的值
当为1时,表示模型完全解释了因变量的变异,即模型完美地预测了因变量的值
3、Agglomerative聚类
是一种基于距离的层次聚类算法,在这个算法中,每个数据点最初都被视为一个单独的簇,然后逐步合并这些簇,直到达到某个停止条件。合并的决策是基于簇之间的相似度(通常使用距离度量),即两个簇之间的相似度越高,他们被合并的可能性越大。
4、AIC赤池信息量准则
是一种用于评估统计模型拟合优度的指标,AIC考虑了模型拟合数据的能力和模型的复杂度,旨在找到一个在数据拟合和模型复杂度之间达到平衡的模型。
AIC的基本思想:一个好的模型应该既能够很好地拟合数据,又不会过于复杂。因此,AIC在计算似然函数值的基础上,对模型复杂度进行惩罚,即增加一个与模型参数数量成正比的项。这样,AIC的值越小,表示模型越优秀。
n:观测值
:样本方差
RSS:残差平方和
d:特征值
AIC的缺点:对模型复杂度的惩罚是固定的,即每个参数的惩罚都是2。这可能会导致某些模型在参数数量上略有不同,但整体结构相似时,AIC的值差异较大。为了解决这个问题,出现了贝叶斯信息量准则(BIC)。
5、AUC值
AUC值是机器学习中用于评估分类模型性能的一种指标,全称Area Under the Curve(曲线下面积)。这里的曲线通常指的是接受者操作特征曲线Receiver Operating Characteristic(ROC)。
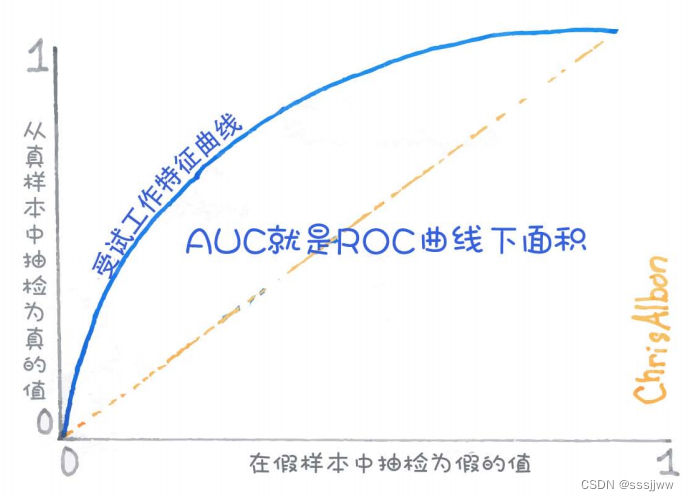
ROC曲线是一个二维图,横坐标为假阳性率(False Positive Rate,FPR),纵坐标为真阳性率(True Positive Rate,TPR)。
AUC值表示的是ROC曲线下的面积大小,其取值范围为0到1,AUC值越高,表示模型的分类性能越好。AUC值为0.5表示模型的性能与随机猜测相当,而AUC值为1表示模型能够完美地区分正负类。
6、防止过拟合
①简易模型:
简易模型通常具有较少的参数,因此不容易过拟合。例如,线性模型比深度神经网络简单,因此更不容易过拟合。通常选择简易模型,可以减少模型的复杂度,从而防止过拟合。
②交叉验证评估:
交叉验证是一种评估模型性能的方法,它通过将数据集分成多个小组,每次使用一个小组作为测试集,其余小组作为训练集,来评估模型的性能。通过这种方式,可以确保模型在不同的数据子集上都表现良好,从而防止过拟合。
③正则化:
正则化是一种减少模型复杂度的方法,它通过在损失函数中添加一个正则项来惩罚模型的复杂度。常见的正则化方法有L1正则化和L2正则化。正则化可以使模型参数变得更小,从而减少模型的复杂度,防止过拟合。
④获取更多数据:
获得更多的数据可以使模型有更多的样本来学习,从而减少过拟合的风险。当数据量增加时,模型可以更好地泛化到未见过的数据上。
⑤集成学习:
集成学习是一种将多个模型组合起来的学习方法,它通过组合多个模型的预测结果来提高模型的性能。集成学习可以减少模型的方差,从而防止过拟合。常见的集成学习方法有随机森林、梯度提升树等。
7、词袋模型
把文本转化成矩阵。矩阵的每一行都是一个样本,每一个特征都是一个单词。矩阵中的每一个元素都是一个标志这个单词有没有出现的二元分类器,或者是这个单词出现的次数。
词袋模型的构建过程通常包括以下几个步骤:
1、分词:将文本分割成单词或短语
2、构建词汇表:将所有文档中的单词或短语汇总起来,构建一个词汇表
3、计算词频:对于每个文档,计算词汇表中每个单词或短语在该文档中出现的次数
4、构建词频向量:将每个文档表示为一个向量,向量的每个元素对应词汇表中的一个单词或短语,元素的值为该单词或短语在文档中出现的次数
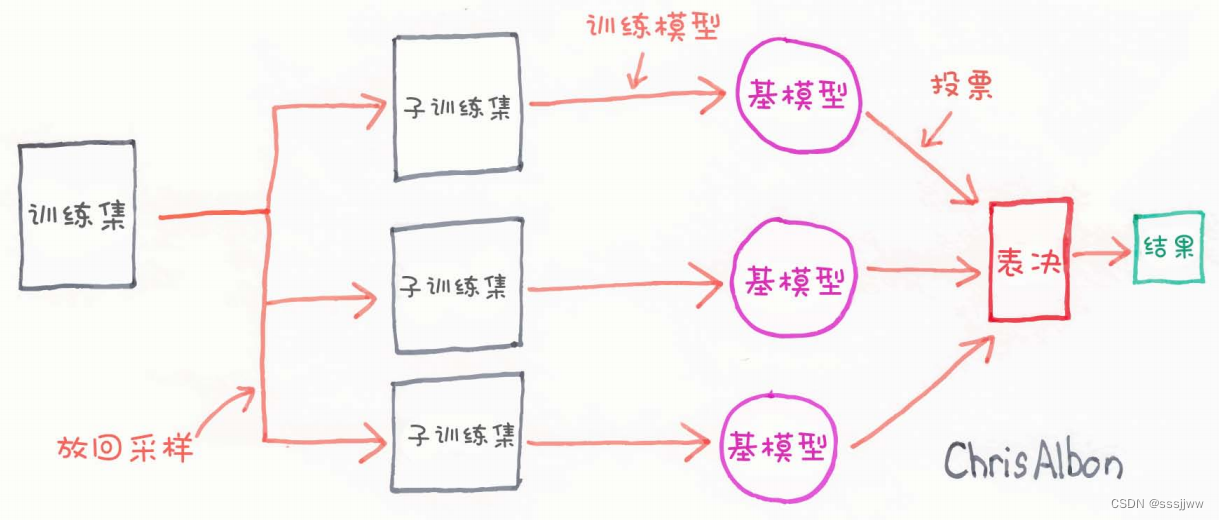
8、Bagging算法
Bagging算法是一种集成学习算法,通过组合多个模型的预测结果来提高整体的预测性能。
Bagging算法的原理:
1、从原始数据集中通常有放回的抽样方式生成多个训练数据集,每个训练数据集的大小与原始数据集形同。
2、对于每个训练数据集,训练一个基模型(如决策树、逻辑回归等)
3、将所有基模型的预测结果进行组合,通常采用多数投票(分类问题)或平均值(回归问题)的方式,得到最终的预测结果
对比bagging和dropout
bagging算法是一种集成学习算法,它通过组合多个模型的预测结果来提高整体的预测性能。Bagging算法的核心思想是减少模型的方差,同时保持模型的偏差不变。Bagging算法通过从原始数据集中通过有放回的抽样方式生成多个训练数据集,然后训练多个基模型,最后将所有基模型的预测结果进行组合,得到最终的预测结果。
Dropout是一种正则化技术,用于防止神经网络中的过拟合,Dropout通过在训练过程随机地丢弃网络中的一些神经元,以及他们的连接,来减少网络的复杂度。这样可以减少网络对训练数据的依赖,提高网络的泛化能力。
9、贝叶斯误差
贝叶斯误差是指在贝叶斯决策理论中,即使使用了最优决策规则,仍然存在的误差。贝叶斯误差是由数据本身的分布决定的,它反映了给定数据分布的情况,最佳决策规则所能达到的最低误差率。
贝叶斯误差的原理如下:
1、贝叶斯决策理论基于贝叶斯定理,它考虑了先验概率、类条件概率和损失函数,以做出最优决策。
2、在贝叶斯决策理论中,最优决策规则是选择具有最小期望能够损失的决策。
3、贝叶斯误差是基于数据本身的分布决定的,它反映了在给定数据分布的情况下,最佳决策规则所能达到的最低误差率。
贝叶斯误差是机器学习中的一个重要概念,它反映了即使使用了最优决策规则,仍然存在误差。贝叶斯误差是由数据本身的分布决定的,它反映了给定数据分布的情况下,最佳决策规则所能达到的最低误差率。
后验概率=似然度*先验概率/边际似然度
贝叶斯法则说明当不能准确知悉一个事务的本质时,可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。即支持某项属性的时间发生得愈多,则该属性成立的可能性就愈大。
优点:数据量小的情况下也很好用,经常很直观
缺点:大数据下计算消耗很大,必须选择一个先验
10、误差BIAS
误差是一种预期的由使用模型来逼近真实世界函数创建的误差。
11、大o算法
表示算法的空间或时间会随着输入规模的增大而增大
大o表示法是计算机科学中用来描述算法复杂度的一种数学符号,它用来表示算法执行时间(或所需空间)的上界,即算法在最坏情况下的性能表现。
大o表示法通常用来描述算法的时间复杂度,即算法执行所需的时间与输入数据量之间的关系。例如,如果一个算法的时间复杂度是O(n),这意味着算法的执行时间与输入数据量n成正比。如果一个算法的时间复杂度是O(n^2),这意味着算法的执行时间与输入数据量n的平方成正比。
大o表示法通常用来描述算法的空间复杂度,即算法执行所需的空间与输入数据量之间的关系。例如,如果一个算法的空间复杂度是O(n),这意味着算法的执行空间与输入数据量n成正比,如果一个算法的空间复杂度是O(n^2),这意味着算法的执行空间与输入数据量n的平方成正比。
12、Boosting算法
Boosting算法是一种集成学习算法,它通过组成多个弱学习器(即性能略好于随机猜测的模型)来构建一个强学习器。Boosting算法的核心思想是通过迭代的方式,逐步提高弱学习器的性能,最终得到一个性能强大的强学习器。
Boosting算法的原理如下:
1、初始化数据集的权重分布,使得所有数据点的权重相等
2、训练第一个弱学习器,并计算器错误率
3、根据第一个弱学习器的错误率,调整数据集的权重分布,使得被第一个弱学习器错误分类的数据点的权重增加,而被正确分类的数据点的权重减少
4、训练第二个弱学习器,并计算其错误率
5、根据第二个弱学习器的错误率,再次调整数据集的权重分布
6、重复上述过程,直到训练出一定数量的弱学习器
7、将所有若学习器组合起来,形成一个强学习器,在组合时,每个弱学习器的权重与其性能相关,性能好的弱学习器权重较大,性能差的弱学习器权重较小
13、布莱尔分数
布莱尔分数表示了所有样本的预测概率值与它们实际结果的均方误差,这个分数范围为0到1,越低代表预测越准确。
n:样本数量
:预测概率
:实际结果
举例说明,比如预测过去某一天会不会下雨,预测值为100%,真实情况为1(表示下雨),则布莱尔分数为0,最佳的布莱尔分数。如果预测值为30%,真实情况为0,则布莱尔分数为0.09,也是不错的预测值。
14、正则化强度的倒数C
在机器学习中,正则化是一种减少模型过拟合的技术。正则化通过在损失函数中添加一个正则化项来惩罚模型的复杂度,从而使模型更加简单和泛化能力更强。
正则化强度的倒数C是一个超参数,用于控制正则化项的权重。C的值越大,正则化强度越小,模型越容易拟合;C的值越小,正则化强度越大,模型越不容易过拟合。
在支持向量机中,C是一个重要的超参数,用于平衡模型的分类间隔和分类错误。C的值越大,模型越注重分类间隔,可能导致过拟合;C的值越小,模型越注重分类错误,可能导致欠拟合。
在逻辑回归中,C也是一个重要的超参数,用于平衡模型的复杂度和泛化能力。C的值越大,模型越容易过拟合;C的值越小,模型约不容易过拟合。
在实际应用中,通常需要通过交叉验证来选择一个合适的C值,以达到最佳的模型性能。
15、微积分中的链式求导法则
链式法则用于有效计算反向传播算法中的梯度。
若:,
,即
:
反向传播算法常常将链法则用于张量的计算,但概念本质上是一样的。
16、特征选择中的卡方应用
在特征选择中,卡方检验是一种常用的统计方法,用于评估特征与目标变量之间的独立性。卡方检验可以用来是被哪些特征与目标变量相关,从而帮助我们选择最有信息量的特征。
卡方检验的基本思想是计算观察到的特征值和期望的特征值之间的差异,并通过卡方统计来衡量这种差异的显著性。如果卡方统计量的值较大,说明观察到的特征值和期望的特征值之间的差异显著,即特征与目标变量之间存在相关性。
在特征选择中,卡方检验通常用于分类问题,特别是当特征是离散的或经过离散化处理时。卡方检验可以用来评估每个特征与目标变量之间的独立性,并根据卡方统计量的值来选择最有信息量的特征。
卡方检验的步骤:
1、构建卡方统计量:计算每个特征与目标变量之间的卡方统计量
2、计算P值:根据卡方统计量和自由度来计算P值,P值表示在原假设(即特征与目标变量独立)成立的条件下,观察到的卡方统计量值出现的概率
3、选择特征:根据P值来选择特征。通常,我们会选择P值较小的特征,因为这些特征与目标变量之间的相关性较强
4、确定阈值:确定一个阈值,用于选择P值小于该阈值的特征。这个阈值通常是根据经验或业务需求来确定的
想要在特征选择时运用,我们需要计算特征和目标之间的
,然后按所需数量选择那些
分数最高的特征。
:第i类中样本的数量
:特征和目标没有关系的情况下,第I类中期望样本的数量
16、one_hot对特性的影响
在随机森林中,能计算每个特征的重要性,然而,如果我们的特征是一个one_hotted的分类的名义特征,那么这个特征的重要性会被分配到所有one-hotted特征上。
独热编码是一种将分类特征转换为数值特征的方法,通过为每个类别创建一个新的特征,并根据类别是否出现来设置特征为1或0。例如,如果一个特征有三个类别,那么经过独热编码后,它会被转换为三个新的特征,每个特征对应一个类别,如果样本属于某个类别,则对应的新特征为1,否则为0。
在随机森林中,每个特征的重要性是通过计算特征在决策树中的分裂重要性来确定的,如果一个特征是经过独热编码的分类特征,那么这个特征的重要性会被分配到所有经过独热编码的特征上,因为这些特征实际上是同一个原始特征的不同变现形式。这意味着,在计算特征重要性时,需要将所有经过独热编码的特征的重要性合并起来,以得到原始特征的整体重要性。
17、弹性网络
弹性网络是一种集合了岭回归(Ridge Regression)和Lasso回归(Least Absolute Shrinkage and Selection Operator,LASSO)优点的惩罚回归模型。这种模型在处理高维数据、特征相关性较强以及存在大量冗余特征的问题上表现出色,弹性网络通过同时使用L1和L2正则化项来优化模型,其中L1正则化有助于生成稀疏模型,L2正则化有助于控制模型稀疏的大小,从而减少过拟合的风险。
18、迭代轮次 epoch
在人工神经网络中,每次所有的样本被送进网络中训练一次,称为一轮,训练神经网络通常需要多个轮次。
19、错误类型
目标是判断病人是否怀孕
第一类错误:假阳性 (一个医生对一名男性说你怀孕了)
第二类错误:假阴性(医生又对一名孕妇说你没怀孕)
20、梯度爆炸
当带参数的损失函数前期层的梯度非常大时,会造成不稳定学习和低性能,一个可能修复的方式是梯度裁剪。
21、F检验
也称为方差比率检验或方差齐性检验,是一种统计假设检验方法,用于检验两个或多个样本的方差是否相等,这种检验方法基于F分布,其统计量是F值,该值是通过比较两个或多个样本的方差比值来计算的。
TSS:总平方和;RSS:残差平方和; n:样本数量; P特征数量
22、特征重要度
决策树将最大化减少杂质,通过计算所有决策树中各特征的杂志的平均减少量,我们可以知道特征的重要性。
23、梯度下降

梯度下降口诀:如果特征之间的数值范围较大,梯度下降会花更长时间。Andrew Ng的法则是如果特征值大小在-3到3之间,或者-1/3到1/3之间,那么就没啥问题。
24、贪心算法
只优化最近的决策,例如,我们要找到坐飞机去十个城市最便宜的方法,一个贪心策略则是,当我们到达某个侧灰姑娘是后,总是买去剩下城市中最便宜的机票。
25、希腊字母




26、网格搜索
一种模型选择策略,该策略中,对每组学习算法/或者超参数的组合训练一个模型,然后选择其中最优模型。















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









