







原文:最初发布地址
一、问题描述
来源:Leetcode
难度:中等
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例一
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例二
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
二、问题分析
S代表用于匹配的字符串
T代表模式字符串
先通过一个例子来看子串匹配过程
判断 T是否是S的子串
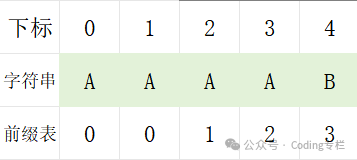
S = AAAAAAB T = AAAAB人可以一眼看出T是S的子串,但是计算机只能通过一点点匹配来判断
每次都从头开始进行匹配,如果不符合,S的下标s++,T的小标t=0,然后继续比较,但是可以看到这两个字符串有很多重复的部分,这部分有没有办法进行跳过呢,这就是这篇文章的重点,KMP算法,通过KMP算法就可以实现跳过重复部分,对字符串匹配进行加速
Knuth–Morris–Pratt(KMP)算法是一种改进的字符串匹配算法,它的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。它的时间复杂度是 O(m+n)。
KMP的核心思路
KMP算法的关键在于一个称为“部分匹配表”(也叫“前缀表”)的数据结构。这个表基于模式串本身构建,用来记录模式串每个位置前的子串中,前缀和后缀最长共有元素的长度。这里的“前缀”指的是除了最后一个字符外,一个字符串的全部头部组合;“后缀”指的是除了第一个字符外,一个字符串的全部尾部组合。
例如上面的例题,对模式串计算前缀表得到
计算过程是
又例如 abcdabcf
计算过程是
一句话就是找公共前缀,只能从前面的子串找
利用这个前缀表,来加速字符串匹配
S = AAAAAAB T = AAAAB # 前缀表 next [0,0,1,2,3]
S[i]和T[j]做比较,相等,则i++,j++,不等则j=next[j]
当i=4,j=4时,S[i]!=T[j], j=next[4]=3, 可以接着从3开始比较
S[4]=T[3],i++,j++, 重复上述过程,过程如图,删除线表示跳过的比较
再例如
S=a b a b e a b a b f T=a b a b f [0 0 0 1 2] # 前缀表计算过程
【细节处理见代码】






三、代码实现
func buildNext(str string) []int {
next := make([]int, len(str))
// j=1是 为了保证字符串错开,例如 abc ,a应该不能直接跟a比较,那样没有意义,应该是 a跟b比较
j := 1
k := 0
for j < len(str)-1 {
if str[j] == str[k] {
k++
j++ // 加1,是因为 j和 k相等,则说明j+1的前缀是 k
next[j] = k
} else {
// 为什么只有为0,才能加1
// 因为:如果k不为0,则可能,next[k]大于0,则当前的值,需要和str[k]进行比较,来得到next[k+1]的前缀
// 例如 aabaaacth 的前缀长度数组是[0,0,1,0,1,2,2,0,0]
// 如 str[2]=b和str[5]=a比较后,不等
// 比较后k=2,j=5,
// 加1: 则k=1,j=6, str[1]!=str[6],所以next[6]=0
// 不加1,则j=5,k=1, str[j]==str[k],则next[5+1]=k+1,
if k == 0 {
j++
}
// 取next[k]的值赋给k,
//相当于一个动态规划的缓存,用前面的值推出后续的值
// 但是不像动态规划,能够直接给出推到公式
k = next[k]
}
}
return next
}
// 子串
func subStr(haystack string, needle string) int {
N := buildNext(needle)
L1 := len(haystack)
L2 := len(needle)
i := 0
k := 0
for i < L1 && k < L2 {
if haystack[i] == needle[k] {
k++
i++
} else {
// k不等于0时,
// 当前haystack[i]需要和模式串的[k]进行比较
// 所以不能+1
if k == 0 {
i++
}
k = N[k]
}
}
// 这里如果 模式串【needle】长度如果等于k,说明模式串是匹配串【haystack】的子串
// 通过匹配串目前的下标减模式串的长度,即可得到第一个匹配的位置
if k == L2 {
return i - L2
}
return -1
}
代码验证:
必应百度谷歌














 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









