







VGG,也叫VGGNet,是ImageNet大赛2014年的亚军,总体也是通过卷积层和池化层的叠加,最后加上一个全连接层来实现的卷积神经网络。它的主要特点是采用了更小的滤波器,也就是卷积核,不像AlexNet那样使用11x11这样大的卷积核,它使用3x3的卷积核以及2x2的池化层;同时采用了更深层的结构。AlexNet只有8层,而VGG达到了16~19层。
与LeNet和AlexNet一样,VGG模型可以分为两部分:第一部分由卷积层和池化层所构成;第二部分由全连接层构成。VGG模型的网络结构和AlexNet的网络结构对比如下图所示:
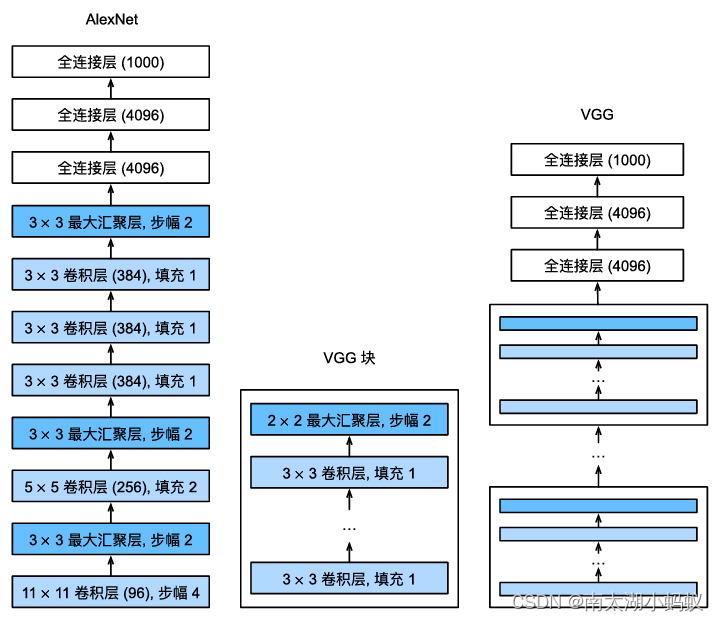
由于VGG模型是由N个VGG块组合再叠加上和AlexNet一样的全连接层构成的,所以我们可以把VGG块提炼出来,避免重复构建同样的结构。论文中作者使用了3x3的卷积层,填充为1,以及2x2的最大池化层,步幅为2(为了使得每个块之后的分辨率减半)。
一个VGG块代码如下所示:
# 定义VGG块
def vgg_block(num_conv, in_channels, out_channels):
'''
num_conv: 卷积层的个数
in_channels: 输入通道数
out_channels: 输出通道数
'''
layers = []
# 叠加卷积层
for i in range(num_conv):
layers.append(nn.Conv(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU(True))
in_channels = out_channels
# 拼上池化层
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers) # 带星号的参数如果为空返回一个空的元组我们使用conv_arch超参数表示VGG模型的层级架构,conv_arch是一个元组,每个元素也是一个元组,代表每个阶段卷积层的重复次数以及此阶段卷积层输出的通道数,如((2,64),(2,128),(3,256),(3,512),(3,512)),代表了该模型第一阶段经过两次卷积操作,输出通道数64,第二阶段经过2次卷积操作,输出通道数128,第三阶段经过3次卷积操作,输出通道数256,第四阶段经过3次卷积操作,输出通道数512,第五阶段经过3次卷积操作,输出通道数512。
从VGG原始论文中,我们可以看到VGG11,VGG13,VGG16和VGG19的架构,我们以VGG16为例(图片中的D列)。可以看到VGG16一共由16个权重层:

具体流程如下:
- 输入224x224的三通道彩色图像
- 经过两个叠加的卷积块,输出通道数为64,输出为64x224x224,之后拼上一个最大池化层,输出为64x112x112
- 经过两个叠加的卷积块,输出通道数为128,输出为128x112x112,之后拼上一个最大池化层,输出为128x56x56
- 经过三个叠加的卷积块,输出通道数为256,输出为256x56x56,之后拼上一个最大池化层,输出为256x28x28
- 经过三个叠加的卷积块,输出通道数为512,输出为512x28x28,之后拼上一个最大池化层,输出为512x14x14
- 经过三个叠加的卷积块,输出通道数为512,输出为512x14x14,之后拼上一个最大池化层,输出为512x7x7
- 把得到的结果展平,进行全连接操作,输出大小为4096的向量
- 继续进行全连接操作,输出大小为4096的向量
- 再进行最后一次全连接操作,输出大小为1000的向量(因为ImageNet比赛的分类结果是1000,我们自己可以修改成我们需要的分类数目)
- 最后进行softmax操作,获得打分值,得到分类结果。
整个VGG模型的代码如下:
# 定义VGG16网络
class VGG(nn.Module):
def __init__(self, conv_arch, num_classes) -> None:
super(VGG, self).__init__()
# 卷积层部分
conv_blocks = [] # 卷积层列表
in_channels = 3 # 开始的输入通道数
for(num_conv, out_channels) in conv_arch:
conv_blocks.append(vgg_block(num_conv, in_channels, out_channels))
in_channels = out_channels # 上一个卷积层的输出通道数就是下一个卷积层的输入通道数
self.features = nn.Sequential(*conv_blocks)
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(0.4),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(0.4),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x =self.features(x)
x = x.view(x.size(0), 512*7*7)
x = self.classifier(x)
return x训练代码和AlexNet文章中的代码一样,就不再赘述了,下面是我们用VGG16模型来训练一下cifar-10数据集,采用原始VGG16模型的话,我们需要先把cifar-10数据集大小调整到224x224:
if __name__ == '__main__':
# cifar10
# 加载cifar数据集
import torchvision.datasets as datasets
from torchvision.transforms.functional import InterpolationMode
conv_arch = ((2,64),(2,128),(3,256),(3,512),(3,512)) # VGG16网络的架构
net = VGG(conv_arch, num_classes=10)
print(net)
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616]) # 此为训练集上的均值与方差
])
train_dataset_cifar = datasets.CIFAR10('./data', train=True, transform=transform, download=True)
test_dataset_cifar = datasets.CIFAR10('./data', train=False, transform=transform, download=True)
train_loader_cifar = torch.utils.data.DataLoader(dataset=train_dataset_cifar, batch_size=64, shuffle=True)
test_loader_cifar = torch.utils.data.DataLoader(dataset=test_dataset_cifar, batch_size=64, shuffle=False)
train(net, train_loader_cifar, test_loader_cifar, lr=0.01, epochs=10)训练了四个epoch发现结果如下:
Epoch 1, Loss: 2.3027, Time 00:19:31
Epoch 2, Loss: 2.3026, Time 00:18:59
Epoch 3, Loss: 2.3026, Time 00:19:09
Epoch 4, Loss: 2.3026, Time 00:19:00可以看到,用我们自己定义的模型很难训练。采用预训练模型的训练cifar-10数据集的结果如下,可以看到测试精度还是比较高的:
import torchvision.models as models
net2 = models.vgg16(pretrained=True) # pytorch提供的预训练模型
dim_in = net2.classifier[-1].in_features # 最后一个分类层的输入维度
net2.classifier[-1] = nn.Linear(dim_in, 10) # 网络最后一层改为分类到10类
train(net2, train_loader_cifar, test_loader_cifar, lr=1e-5, epochs=10)Epoch 1, Loss: 0.8323, Time 00:20:04
Epoch 2, Loss: 0.3974, Time 00:18:44
Epoch 3, Loss: 0.3279, Time 00:18:37
Epoch 4, Loss: 0.2835, Time 00:18:45
Epoch 5, Loss: 0.2531, Time 00:18:31
Epoch 6, Loss: 0.2272, Time 00:18:43
Epoch 7, Loss: 0.2103, Time 00:18:40
Epoch 8, Loss: 0.1931, Time 00:18:47
Epoch 9, Loss: 0.1777, Time 00:18:48
Epoch 10, Loss: 0.1639, Time 00:18:51
Test Accuracy: 92.21%但是,训练时间比较长,每个epoch大约需要18分钟,可能是由于我们把cifar-10图像放大后训练时间较长,我们尝试直接在原始cifar-10数据集上训练,那样的话,我们需要修改一下VGG16模型,因为卷积层的最终输出不再是512*7*7,而是512*1*1。
Epoch 1, Loss: 1.2827, Time 00:01:17
Epoch 2, Loss: 0.8012, Time 00:01:20
Epoch 3, Loss: 0.6175, Time 00:01:13
Epoch 4, Loss: 0.5044, Time 00:01:10
Epoch 5, Loss: 0.4298, Time 00:01:11
Epoch 6, Loss: 0.2126, Time 00:01:12
Epoch 7, Loss: 0.1415, Time 00:01:11
Epoch 8, Loss: 0.1173, Time 00:01:12
Epoch 9, Loss: 0.1047, Time 00:01:11
Epoch 10, Loss: 0.0975, Time 00:01:11
Test Accuracy: 83.11%可以看到每个epoch训练时间缩短到了1分钟左右。
然而我们自己定义的VGG模型在原始cifar-10数据集上依然无法训练。后来我查阅了一些文档,发现如果在模型中引入批量归一化层,也就是batchNorm操作,立刻就发现损失下降了。简单来说就是,如果不做归一化操作,由于不同特征的尺度不同,而深度学习模型会学习每个特征的权重,这些特征也在不同的尺度上,大特征的梯度会容易淹没小特征的梯度,模型会对权重进行较大的更新,导致梯度下降轨迹会沿着一个维度来回震荡,损失不容易下降。如果特征调整到统一的尺度上,梯度可以平稳的下降。
我们修改卷积块后,完整代码如下:
# 定义VGG块
def vgg_block(num_conv, in_channels, out_channels):
'''
num_conv: 卷积层的个数
in_channels: 输入通道数
out_channels: 输出通道数
'''
layers = []
# 叠加卷积层
for i in range(num_conv):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.BatchNorm2d(out_channels)) # 加上批量归一化操作
layers.append(nn.ReLU(True))
in_channels = out_channels
# 拼上池化层
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers) # 带星号的参数如果为空返回一个空的元组
# 定义VGG16网络
class VGG2(nn.Module):
def __init__(self, conv_arch, num_classes) -> None:
super(VGG2, self).__init__()
# 卷积层部分
conv_blocks = [] # 卷积层列表
in_channels = 3 # 开始的输入通道数
for(num_conv, out_channels) in conv_arch:
conv_blocks.append(vgg_block(num_conv, in_channels, out_channels))
in_channels = out_channels # 上一个卷积层的输出通道数就是下一个卷积层的输入通道数
#conv_blocks.append(nn.AvgPool2d(kernel_size=1, stride=1))
self.features = nn.Sequential(*conv_blocks)
self.classifier = nn.Sequential(
nn.Linear(512*1*1, 4096), # 采用原始cifar-10数据集训练,最终卷积层输出张量大小为512*1*1
nn.ReLU(True),
nn.Dropout(0.4),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(0.4),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x =self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
if __name__ == '__main__':
# 加载cifar数据集
import torchvision.datasets as datasets
from torchvision.transforms.functional import InterpolationMode
conv_arch = ((2,64),(2,128),(3,256),(3,512),(3,512))
net = VGG2(conv_arch, num_classes=10)
transform = transforms.Compose(
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616]) # 此为训练集上的均值与方差
])
train_dataset_cifar = datasets.CIFAR10('./data', train=True, transform=transform, download=True)
test_dataset_cifar = datasets.CIFAR10('./data', train=False, transform=transform, download=True)
train_loader_cifar = torch.utils.data.DataLoader(dataset=train_dataset_cifar, batch_size=24, shuffle=True)
test_loader_cifar = torch.utils.data.DataLoader(dataset=test_dataset_cifar, batch_size=24, shuffle=False)
train(net, train_loader_cifar, test_loader_cifar, lr=0.01, epochs=10)训练效果如下:
Epoch 1, Loss: 1.5935, Time 00:01:22
Epoch 2, Loss: 1.0860, Time 00:01:27
Epoch 3, Loss: 0.8365, Time 00:01:18
Epoch 4, Loss: 0.6733, Time 00:01:13
Epoch 5, Loss: 0.5624, Time 00:01:13
Epoch 6, Loss: 0.4696, Time 00:01:12
Epoch 7, Loss: 0.3997, Time 00:01:11
Epoch 8, Loss: 0.3355, Time 00:01:11
Epoch 9, Loss: 0.2772, Time 00:01:11
Epoch 10, Loss: 0.2361, Time 00:01:11
Test Accuracy: 84.43%可以看到,可以正常训练了,训练10个epoch后,测试精度达到了84.43%。
下面是调用VGG16网络训练我们之前的猫狗分类数据集的代码:
import torchvision.models as models
net2 = models.vgg16(pretrained=True)
dim_in = net2.classifier[-1].in_features # 最后一个分类层的输入维度
net2.classifier[-1] = nn.Linear(dim_in, 2) # 网络最后一层改为分类到两个类别
# 猫狗分类
from dogcat import myDataset
trainDataset = myDataset(r'D:\样本库\dogcat\zip\train',transform=transform)
train_loader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=True)
valDataset = myDataset(r'D:\样本库\dogcat\zip\val',transform=transform)
val_loader = DataLoader(dataset=valDataset, batch_size=32, shuffle=False)
net = VGG(conv_arch, num_classes=2)
train(net, train_loader, val_loader, lr=1e-5, epochs=50) # 用我们自定义的VGG16模型训练
train(net2, train_loader, val_loader, lr=1e-5, epochs=10)# 用预训练模型进行训练Epoch 50, Loss: 0.6198, Time 00:00:39
saveing checkpoints/vgg.pt
Test Accuracy: 61.50%可以看到,我们自己的定义的模型训练猫狗分类数据集的效果比较差,训练50个epoch后,测试精度仅仅达到61.5%。下面换成预训练过的模型试试:
Epoch 1, Loss: 0.7044, Time 00:00:22
Epoch 2, Loss: 0.6663, Time 00:00:19
Epoch 3, Loss: 0.6247, Time 00:00:19
Epoch 4, Loss: 0.6050, Time 00:00:19
Epoch 5, Loss: 0.5531, Time 00:00:19
Epoch 6, Loss: 0.5177, Time 00:00:19
Epoch 7, Loss: 0.4908, Time 00:00:19
Epoch 8, Loss: 0.4631, Time 00:00:19
Epoch 9, Loss: 0.4467, Time 00:00:19
Epoch 10, Loss: 0.4284, Time 00:00:19
Test Accuracy: 93.50%可以看到,采用预训练模型后仅仅10个epoch,测试精度就达到了93.5%,而AlexNet的预训练模型,同样训练10个epoch的时候,测试精度仅有74.5%,从这里也可以看出VGG模型相对于AlexNet的巨大性能提升。下一次我们介绍一下谷歌推出的深度神经网络模型——GoogleNet,该模型创新性的应用了Inception模块。















 7112
7112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









