









今天看一篇ACL findings上关于对比学习的论文。故事点是小样本+文本的数据增强方式。 过两天总结一下NLP领域数据增强的方式吧。
Title: Constructing Contrastive Samples via Summarization for Text Classification with Limited Annotations
From: EMNLP Findings 2021
Link: https://aclanthology.org/2021.findings-emnlp.118/
Code: https://github.com/ChesterDu/Contrastive_summary
文章的重点是在标注数据有限的情况下,使用对比学习来改善文本分类任务。
文章利用文本摘要来作为数据增强的方式来生成正负样本。假设前提为一个好的文本摘要系统可以保持原始文本的最关键信息,生成的摘要与原始文本术语同一类别。
Method
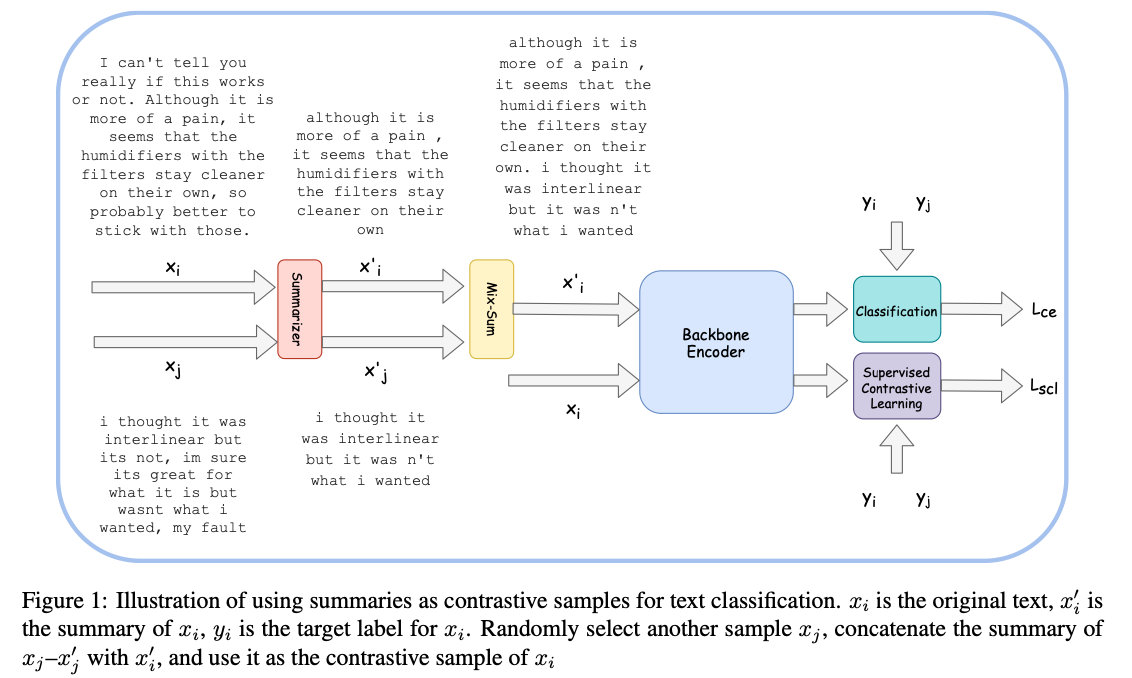
- 文本摘要
文章使用PreSumm (Liu and Lapata, 2019) 来自动生成摘要。PreSumm有两种方式: extractive 和 abstractive summarization,文章选用的是后一种。因为extractive是从原文中选择句子,abstractive是生成式的。对于样本x,摘要得到其正样本x’。
Summarization的过程可以认为是过滤掉不重要的和冗余的信息,抽取出最具有代表性的语义。而且,摘要和原文具有同一类标签。
- Mixsum
另一个贡献点在于作者提出了Mixsum。和MIT在ICLR 2018上提出的mix-up类似。都是对已有训练样本进行“混合”来构建新的训练样本。
首先介绍下相关背景。
经验风险最小化(Empirical Risk Minimization,ERM) 是我们监督学习中最通用的理论,让学习器在训练样本上的"训练误差"/"经验误差"最小。其实我们的最终目标是让”泛化误差“最小,但由于测试样本是未知的,所以只能退而求其次,试图通过最小化经验误差,来达到最小化泛化误差的效果。当经验误差被过分减小时,就变成了”过拟合“。一般来说,随着数据量的增大,过拟合的风险就会变小。但在有限的标注数据上,”领域风险最小化“可以帮助缓解这个问题。
领域风险最小化(Vicinal Risk Minimization,VRM)是通过先验知识构造样本的领域值。Mix-up对随机两个样本进行融合得到新样本,通过Beta分布来控制融合的程度。
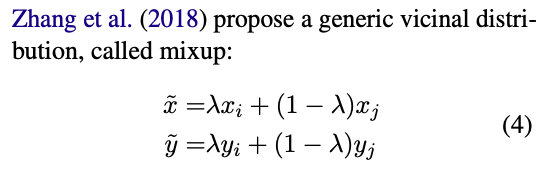
作者提出的Mixsum是直接把通过摘要得到的文本拼接在一起,作为新样本。标签也是一样。
Experiments
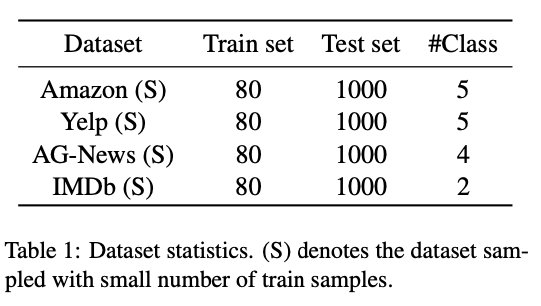
选用了Amazon-5, Yelp-5, AG News and IMDb四个数据集。为了验证对小样本的效果,每个数据都随机划分出了样本量为80的训练集和样本量为1000的测试集。
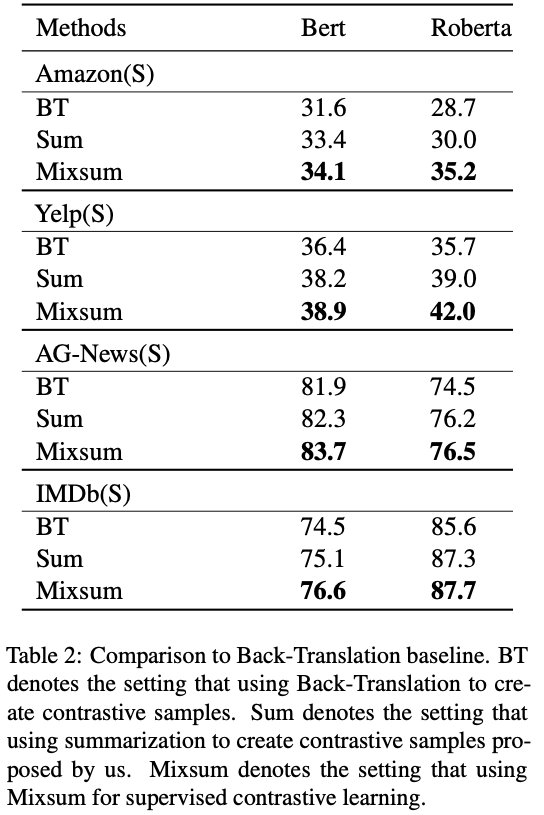
实验效果如下:
作者还做了实验来验证训练样本数量对结果的影响。
除了80个样本的Small数据集,还对每个benchmark划分出了800和6500训练样本的Medium和Large数据集。
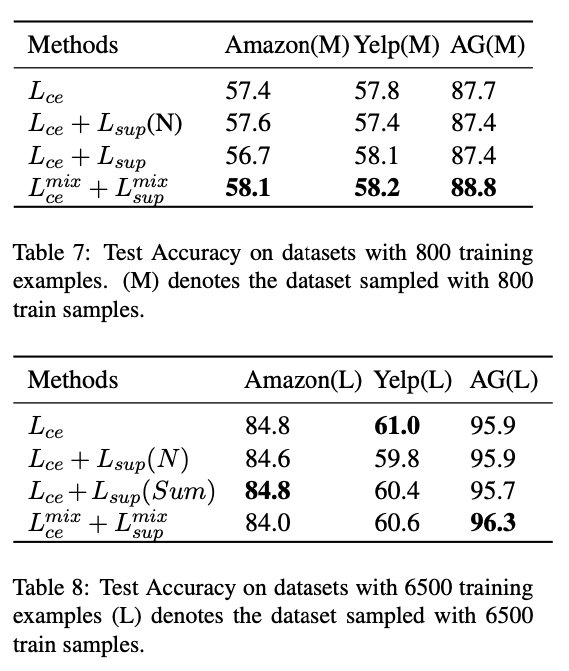
d
结果说明在有限的标注样本的场景下,该方法是十分有益的,但是当训练样本充足时,这种方法可能就是不必要的。















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









