




简介:斯坦福大学CS231n课程的第二份作业集中于两层神经网络的实现,使用Python和numpy库深入探讨神经网络的基础。通过该作业,学生能够掌握数据预处理、权重初始化、前向传播、损失函数、反向传播、优化算法、训练循环、过拟合预防和验证测试等关键概念,并了解图像分类中卷积神经网络的应用。
1. CS231n课程第二份作业概览
本课程的第二份作业深入探讨了计算机视觉领域的核心概念,并要求学生亲手实现一些关键的神经网络组件。本章将概述作业的要求,以及完成作业所需的先决知识。通过本章,你将对课程的结构有一个清晰的认识,并且了解如何使用Python和numpy来搭建基础的神经网络。
1.1 作业目的和目标
CS231n课程的第二份作业旨在使学生掌握神经网络的基础知识。它涵盖了从数据预处理到模型评估的整个流程。通过这次作业,学生将学会如何准备数据、设计网络结构、初始化权重以及优化网络参数,最终对模型进行验证和测试。这个过程模拟了在实际机器学习项目中遇到的挑战。
1.2 本章内容安排
本章将简要介绍第二份作业的背景和目标,为后续章节中对每个特定主题的详细介绍打下基础。接下来,我们将具体分析在使用Python和numpy进行神经网络实现中所扮演的角色。本章的重点是为读者提供一个作业概览,为深入学习接下来的各个章节内容做好准备。
2. Python与numpy在神经网络实现中的作用
2.1 Python编程语言概述
2.1.1 Python语言的特点和优势
Python是一种高级编程语言,它以其简洁的语法、强大的标准库和多样的第三方库而闻名于开发者社区。Python的设计哲学强调代码的可读性和简洁的语法结构,这使得Python在数据科学、机器学习和人工智能领域得到了广泛应用。其主要优势包括:
- 易学易用 :Python的语法清晰明了,初学者可以快速上手,而且它支持多种编程范式。
- 丰富的库支持 :Python拥有大量的开源库,涵盖了数学计算、数据分析、机器学习、深度学习等多个方面。
- 跨平台兼容性 :Python可以在多个操作系统上运行,包括Windows、Mac OS X和Linux。
- 社区支持 :Python有一个活跃的开发者社区,这为解决编程问题提供了巨大的帮助。
2.1.2 Python在机器学习中的应用案例
Python在机器学习领域中的应用案例非常丰富,从简单的统计分析到复杂的模型构建,Python都有涉及。比如,它在以下场景中的应用:
- 数据预处理 :使用Pandas库处理数据,进行数据清洗、编码、归一化等。
- 特征工程 :利用scikit-learn进行特征选择、特征提取等。
- 模型构建与训练 :使用TensorFlow或PyTorch等深度学习框架构建和训练神经网络模型。
- 模型评估 :通过scikit-learn库中的各种评估工具对模型进行准确性和效率的评估。
Python凭借其灵活性和强大的工具生态系统,在机器学习领域中占据着举足轻重的地位。
2.2 numpy库的介绍和使用
2.2.1 numpy数组基础操作
numpy是一个专注于数值计算的Python库,它提供了高性能的多维数组对象和用于处理数组的工具。numpy数组(ndarray)是numpy中的基本数据结构,它在性能上优于Python原生的list对象,是进行科学计算的基础。numpy数组的基础操作包括:
- 数组创建 :通过
numpy.array()或numpy.arange()等函数创建数组。 - 数组维度操作 :使用
reshape()方法改变数组形状,或者使用squeeze()和expand_dims()增加或删除维度。 - 数组索引和切片 :像操作Python列表一样使用索引和切片选择数组元素。
- 数组计算 :执行元素级的运算,如加法、减法、乘法等。
2.2.2 numpy在矩阵运算中的应用
numpy在矩阵运算中的应用广泛,尤其是在神经网络实现中不可或缺。其主要特点包括:
- 高效的矩阵运算 :numpy利用底层优化的C语言库执行矩阵运算,提供了高效的计算性能。
- 向量化操作 :numpy支持向量化操作,可以避免显式循环,使得代码更加简洁。
- 广播机制 :numpy的广播机制允许不同形状的数组进行数学运算。
下面是一个简单的示例,展示numpy在矩阵运算中的应用:
import numpy as np
# 创建两个随机矩阵
A = np.random.rand(3, 2)
B = np.random.rand(2, 3)
# 矩阵乘法
C = np.dot(A, B)
print("Matrix multiplication result:\n", C)
# 广播机制应用 - 向量与矩阵相加
vector = np.random.rand(3)
result = vector + A
print("Broadcast addition result:\n", result)
以上代码执行了矩阵乘法和向量化操作,展示了numpy在矩阵运算中的便利性和高效性。
以上内容详尽地介绍了Python编程语言及numpy库的基础知识和在机器学习中的应用。通过对Python语言特点的分析、实例演示numpy数组操作和矩阵运算,我们为后续章节中实现神经网络打下了坚实的基础。在下一章节中,我们将进一步深入到神经网络的基础架构,探索其内部工作机制。
3. 神经网络基础:两层网络架构介绍
3.1 神经网络的基本组成单元
3.1.1 神经元的工作原理
神经元,作为神经网络中最基础的单元,模仿了生物神经元的结构和功能。在人工神经网络中,每个神经元接收一组输入信号,这些信号对应于前一层神经元的输出。每个输入信号通过加权的方式与一个连接强度(权重)相关联。神经元计算这些加权输入的总和,并通过一个激活函数来决定其输出信号的强度。这个过程可以用以下数学公式表示:
[ y = f(\sum_{i=1}^{n} w_i x_i + b) ]
其中,( x_i ) 表示输入信号,( w_i ) 表示对应的权重,( b ) 是偏置项,( f ) 为激活函数,( y ) 是神经元的输出。
激活函数是引入非线性的关键因素,没有激活函数,无论神经网络有多少层,最终都可以被压缩成只有一层线性映射,失去深度网络的优势。
3.1.2 激活函数的选择和作用
激活函数的目的是增加神经网络模型的非线性,从而使网络能够学习和执行更复杂的任务。最常用的激活函数包括:
- Sigmoid 函数:( f(x) = \frac{1}{1 + e^{-x}} )
- Tanh 函数:( f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} )
- ReLU 函数(Rectified Linear Unit):( f(x) = \max(0, x) )
ReLU 由于其计算简单和高效的特性,在很多深度神经网络中被广泛使用。但是,ReLU 在负数区间的导数为零,这可能导致所谓的“死亡ReLU”问题,即部分神经元可能永久不激活。
3.2 两层网络架构的构建
3.2.1 前向传播的实现步骤
前向传播是神经网络中信息从输入层经过隐藏层直到输出层的流动过程。对于一个两层网络(一层隐藏层和一层输出层),其前向传播可以分为以下几个步骤:
- 将输入数据通过权重矩阵和偏置项进行线性变换。
- 应用激活函数到上一步的线性变换结果上,得到隐藏层的输出。
- 将隐藏层的输出作为下一层的输入,重复以上步骤。
- 在输出层应用激活函数(对于分类问题可能是softmax函数),得到最终输出。
3.2.2 网络参数的初始化策略
网络参数的初始化是优化网络性能的重要步骤。不恰当的初始化可能导致学习过程缓慢或收敛困难。以下是几种常见的初始化策略:
- 随机初始化:权重是从一个小范围内的均匀或高斯分布中随机选取。
- Xavier(Glorot)初始化:通过考虑输入输出神经元的数量来初始化权重,使前向和反向信号的方差保持一致。
- He初始化:类似于Xavier初始化,但是特别为ReLU激活函数进行了优化。
初始化方法的选择对于深度神经网络的性能有着显著影响,因为它直接影响到梯度的大小和网络训练的稳定性。
import numpy as np
def initialize_parameters(n_x, n_h, n_y):
np.random.seed(2) # 设置随机种子,保证结果的可复现性
W1 = np.random.randn(n_h, n_x) * 0.01 # Xavier初始化
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
以上代码展示了如何使用Python和numpy库初始化一个具有单个隐藏层的简单神经网络的参数。这里我们使用了Xavier初始化策略,以确保参数的合理范围,促进梯度流的稳定。
4. 数据预处理方法
数据预处理是机器学习中一个至关重要的步骤,它直接影响到模型训练的效果和最终性能。对于深度学习模型来说,尤其是在图像处理、语音识别等领域的应用,高质量的数据预处理是必不可少的。本章节将深入探讨数据预处理的两个主要方面:数据清洗和标准化、数据增强技术,并分析它们对模型训练和性能的具体影响。
4.1 数据清洗和标准化
数据清洗和标准化是数据预处理的基础,它们涉及去除数据噪声、处理异常值、填补缺失值以及将数据调整到一个统一的尺度,从而使模型能够更有效地学习。
4.1.1 缺失值处理
在实际数据集中,经常会出现缺失值的问题。缺失值可能是由于数据采集过程中的错误、数据传输失败或者其他原因造成的。处理缺失值的方法有很多,每种方法都有其适用场景。
4.1.1.1 删除含有缺失值的数据
在一些情况下,如果数据集很大,而且缺失值所占比例很小,可以简单地选择删除含有缺失值的样本。这种方法的缺点是可能会丢失大量有用信息,尤其是当缺失值并非随机分布时。
import pandas as pd
# 假设df是包含缺失值的DataFrame
df.dropna(inplace=True) # 删除含有缺失值的行
4.1.1.2 填充缺失值
另一种常见的方法是用某个值填充缺失值。这个值可以是均值、中位数或是一个特定值。使用均值填充适用于数值型数据,而对于类别型数据,则常用众数(即出现频率最高的值)。
df['column_name'].fillna(df['column_name'].mean(), inplace=True) # 用均值填充
4.1.1.3 利用模型预测填充
更高级的方法是使用其他特征建立一个回归模型,来预测缺失值。这种方法在医学数据处理中特别常见,其中缺失值可能包含着重要的医疗信息。
4.1.2 数据归一化和标准化
数据归一化和标准化都是将数据缩放到一个特定范围,或者使其具有统一的分布。这是为了避免在训练神经网络时,输入特征的数值范围差异影响模型性能。
4.1.2.1 Min-Max归一化
Min-Max归一化将特征数据缩放到0到1的范围内。具体公式为:
[ x_{\text{norm}} = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}} ]
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_scaled = scaler.fit_transform(df[['column_name']]) # 将特定列进行归一化
4.1.2.2 Z-Score标准化
Z-Score标准化将数据转换成均值为0,标准差为1的分布。这样做的好处是,数据的分布将更加接近正态分布,有助于一些优化算法的收敛。
[ x_{\text{std}} = \frac{x - \mu}{\sigma} ]
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df[['column_name']]) # 将特定列进行标准化
4.2 数据增强技术
数据增强是提高模型泛化能力的有效手段,尤其在数据量相对较少时,数据增强能够有效地模拟新的训练样本,增加模型对数据变化的鲁棒性。
4.2.1 常用的数据增强方法
数据增强对于图像数据而言尤其重要,下面列举一些常见的图像增强技术。
4.2.1.1 随机旋转
随机旋转图像能够在不改变图像内容的前提下,提供新的视角,这对于识别旋转不变的对象非常有用。
from imgaug import augmenters as iaa
seq = iaa.Sequential([
iaa.Affine(rotate=(-10, 10)) # 随机旋转-10度到10度之间
])
4.2.1.2 随机裁剪
随机裁剪可以在保持图像标签不变的情况下,提供新的图像尺寸和内容,训练网络更好地识别图像的局部特征。
seq = iaa.Sequential([
iaa.Crop(percent=(0, 0.1)) # 随机裁剪出原图的0%到10%
])
4.2.1.3 颜色抖动
颜色抖动通过调整图像的颜色参数,如亮度、对比度等,来增加数据的多样性。
seq = iaa.Sequential([
iaa.Multiply((0.8, 1.2)) # 随机调整亮度至原亮度的80%到120%
])
4.2.2 数据增强对模型性能的影响
数据增强能够提高模型的泛化能力,因为它引入了更多的样本变化,这有助于模型学会忽略不重要的特征变化,更加关注关键特征。然而,数据增强也需要谨慎使用,过多或不恰当的数据增强可能会引入噪声,导致模型性能下降。
数据增强的技术和应用是深度学习领域研究的热点之一,持续有新的方法被提出和验证。在本章中,我们深入了解了数据清洗和标准化的必要性,以及数据增强技术在提高模型性能方面的潜力。掌握这些技能对于构建一个健壮的机器学习系统至关重要。
5. 权重初始化技术
权重初始化在神经网络的训练中扮演着至关重要的角色。在这一章中,我们将探讨初始化的重要性、不同初始化方法的基本原理以及它们对网络训练的影响。
5.1 权重初始化的重要性
权重初始化是设置神经网络参数的初始值的过程。良好的初始化方式对于训练神经网络是非常重要的,它直接影响到训练速度以及模型能否成功收敛到一个好的性能。
5.1.1 随机初始化与零初始化的比较
在神经网络研究的早期阶段,许多研究人员和工程师尝试使用零初始化,即将所有的权重和偏置初始化为零。这种方法的问题在于,如果每一层的参数都相同,那么在反向传播过程中,每层的梯度更新也会相同。这种对称性破坏了网络参数的多样性,导致了所谓的对称性消失问题,并且限制了神经网络的学习能力。
为了避免这个问题,研究人员提出了随机初始化方法。通过为每个权重分配一个小的随机值(例如,从一个小的均匀分布或正态分布中抽取),可以保证每一层的神经元接收到不同的输入,从而打破对称性。这种方法允许网络参数在训练开始时就具有足够的多样性,促进了更有效的学习过程。
5.1.2 好的初始化方式对训练的影响
一个好的权重初始化策略不仅帮助避免对称性问题,还可以影响训练过程的稳定性,特别是对于深层网络而言。例如,如果初始化的权重值过大,那么在前向传播时,激活函数可能会饱和,导致梯度消失的问题,这会极大地减慢学习过程。相反,如果权重值太小,那么前向传播和反向传播中的梯度可能会非常小,使得网络几乎不学习或者学习得非常慢。因此,合理选择权重初始化策略,能够显著加快模型的收敛速度,并提高最终模型的性能。
5.2 各种权重初始化方法介绍
为了应对不同网络结构和激活函数带来的挑战,研究人员开发了多种权重初始化方法。接下来,我们将详细介绍两种广泛使用的初始化技术:Xavier初始化和He初始化。
5.2.1 Xavier初始化
Xavier初始化(也被称为Glorot初始化)是一种根据网络层的输入和输出单元数来选择合适的权重初始值的方法。它是由Xavier Glorot和Yoshua Bengio在2010年提出的。该方法的动机是保持前向传播和反向传播过程中信号的方差一致,以使训练过程更加稳定。
初始化公式如下:
$$ W \sim U \left[-\frac{\sqrt{6}}{\sqrt{n_{in} + n_{out}}}, \frac{\sqrt{6}}{\sqrt{n_{in} + n_{out}}} \right] $$
其中,$W$ 是权重矩阵,$U$ 表示均匀分布,$n_{in}$ 是输入单元的数量,$n_{out}$ 是输出单元的数量。
5.2.2 He初始化
He初始化是为ReLU(Rectified Linear Unit)激活函数特别设计的初始化方法。由Kaiming He等在2015年提出,该初始化方法在Xavier初始化的基础上进行了改进,以适应ReLU激活函数的非对称性和稀疏性。它通过增加方差来考虑ReLU在正向传播时死亡的问题。
初始化公式如下:
$$ W \sim N \left(0, \frac{2}{n_{in}} \right) $$
其中,$N$ 表示高斯分布,$n_{in}$ 是输入单元的数量。
初始化方法的比较
Xavier和He初始化方法都是根据网络结构计算权重的初始值,但它们适用于不同的激活函数。Xavier初始化适用于tanh或sigmoid激活函数,而He初始化适用于ReLU激活函数。此外,还有其他初始化技术,例如MSRA初始化,它与He初始化非常相似,但有细微的数学差异。
在选择合适的初始化技术时,需要考虑网络的深度、使用的激活函数以及训练数据的特性。一个合适的初始化方法可以使模型更快地收敛,并且有时可以提高模型的最终性能。
实际应用建议
当使用深度学习框架进行模型设计时,如TensorFlow或PyTorch,开发者可以利用框架提供的现成初始化方法。例如,在PyTorch中,可以使用 torch.nn.init.xavier_uniform_() 或 torch.nn.init.kaiming_uniform_() 等函数来进行权重初始化。这些方法可以很容易地应用于自定义的网络结构中,无需手动编写初始化代码。
import torch.nn.init as init
# 假设layer是网络层的权重
layer = torch.empty(10, 10) # 10x10的权重矩阵
init.xavier_uniform_(layer.data) # Xavier初始化
权重初始化在实际中的效果
在实践中,我们可以观察到不同权重初始化方法对模型训练的影响。以一个使用ReLU激活函数的简单全连接层为例,我们可以通过实验比较Xavier初始化和He初始化的收敛速度和最终性能。通常,我们会发现He初始化收敛得更快,并且最终模型性能更优。
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 实例化模型和优化器
model = SimpleNet(input_size=10, hidden_size=50, output_size=2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 使用He初始化权重
def he_init(module):
if isinstance(module, nn.Linear):
init.kaiming_uniform_(module.weight)
model.apply(he_init)
在使用适当的权重初始化方法后,模型的训练和性能将会有明显的改进。权重初始化对于神经网络的成功训练至关重要,它确保了网络在开始训练时就具有良好的学习能力,为模型的优化和收敛奠定了基础。
6. 神经网络的前向传播机制
前向传播是神经网络中数据从输入层经过隐藏层最终到输出层的过程。理解前向传播对于构建和训练神经网络至关重要,它不仅涉及数据流的传递,还涉及到权重和激活函数如何共同作用以产生输出。
6.1 前向传播的计算过程
6.1.1 线性变换的实现
在神经网络中,每个节点的线性变换可以表示为加权输入的总和,通常还包括一个偏置项。这个过程可以用如下数学公式表示:
[ z^{(l)} = W^{(l)}a^{(l-1)} + b^{(l)} ]
其中 ( z^{(l)} ) 是第 ( l ) 层的线性变换结果,( W^{(l)} ) 是对应层的权重矩阵,( a^{(l-1)} ) 是上一层的激活输出,而 ( b^{(l)} ) 是偏置向量。
6.1.2 激活函数的引入
线性变换之后,激活函数用于引入非线性因素,使得神经网络有能力学习和表示复杂的功能。常见的激活函数有 Sigmoid、ReLU 等。例如,ReLU 激活函数的数学表达式为:
[ a^{(l)} = \max(0, z^{(l)}) ]
6.2 前向传播的代码实现
6.2.1 Python代码示例
为了更直观地展示前向传播的实现,以下是一个简化的 Python 代码示例,使用 numpy 库进行矩阵运算:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def forward_propagation(W1, b1, W2, b2, X):
# 第一层的线性变换与激活函数
z1 = np.dot(W1, X) + b1
a1 = sigmoid(z1)
# 第二层的线性变换与激活函数
z2 = np.dot(W2, a1) + b2
a2 = sigmoid(z2)
return a1, a2
# 假设参数已经被初始化
W1, b1, W2, b2 = ... # 省略了权重和偏置的初始化
X = ... # 输入数据
a1, output = forward_propagation(W1, b1, W2, b2, X)
6.2.2 numpy在前向传播中的应用
在上述代码中,numpy库被用来执行矩阵乘法和加法,这些是实现线性变换的基础。通过利用 numpy 的高效矩阵操作,可以简化前向传播的实现,并且执行速度非常快,这对于深度学习中的大规模运算至关重要。
需要注意的是,在实际应用中,前向传播通常包含多层,每层可能有不同的激活函数。此外,激活函数的选择取决于具体任务的需求,有时候也会使用如 tanh、LeakyReLU 等其他激活函数。
mermaid 格式流程图示例 :
graph LR
A[输入数据 X] -->|加权求和| B(W1 * X + b1)
B -->|激活函数| C[ReLU]
C -->|加权求和| D(W2 * A + b2)
D -->|激活函数| E[输出]
在这个流程图中,我们可以清晰地看到数据是如何通过网络的各个节点流动的,并且每个节点都执行了加权求和和激活函数的操作。
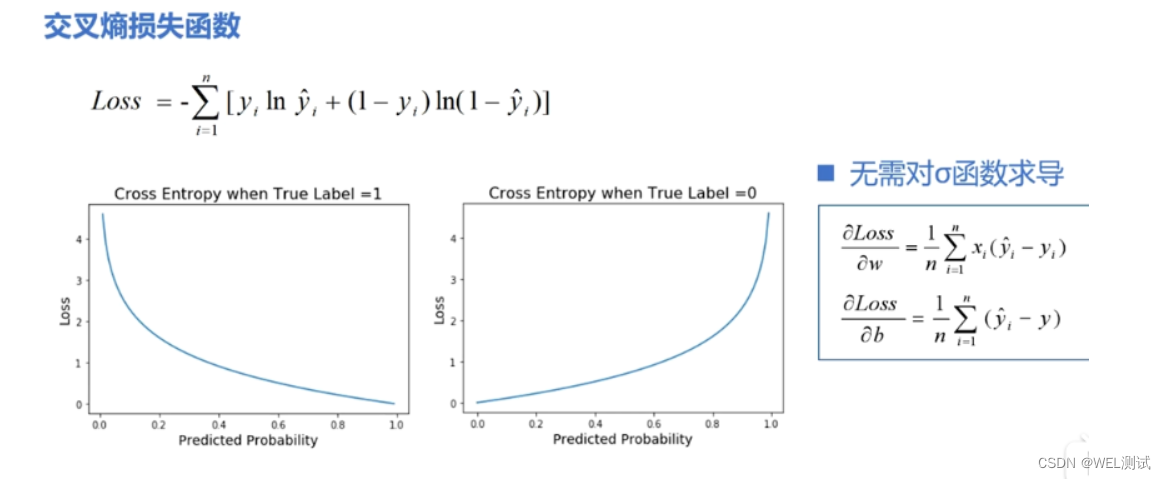
通过上面的讲解,我们了解了前向传播机制的数学原理和编程实现。在下一章中,我们将探讨神经网络训练过程中的损失函数和其优化策略。
简介:斯坦福大学CS231n课程的第二份作业集中于两层神经网络的实现,使用Python和numpy库深入探讨神经网络的基础。通过该作业,学生能够掌握数据预处理、权重初始化、前向传播、损失函数、反向传播、优化算法、训练循环、过拟合预防和验证测试等关键概念,并了解图像分类中卷积神经网络的应用。

















 2678
2678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









