







在深度计算机视觉领域中,有几种类型的卷积层与我们经常使用的原始卷积层不同。在计算机视觉的深度学习研究方面,许多流行的高级卷积神经网络实现都使用了这些层。这些层中的每一层都有不同于原始卷积层的机制,这使得每种类型的层都有一个特别特殊的功能。
在进入这些高级的卷积层之前,让我们先快速回顾一下原始的卷积层是如何工作的。
原始卷积层
在原始的卷积层中,我们有一个形状为WxHxC的输入,其中W和H是每个feature map的宽度和高度,C是channel的数量,基本上就是feature map的总数。卷积层会有一定数量的核,核会对这个输入进行卷积操作。内核的数量将等于输出feature map中所需通道的数量。基本上,每个内核都对应于输出中的一个特定的feature map,并且每个feature map都是一个通道。
核的高度和宽度是由我们决定的,通常,我们保持3x3。每个内核的深度将等于输入的通道数。因此,对于下面的例子,每个内核的形状将是(wxhx3),其中w和h是内核的宽度和高度,深度是3,因为在这种情况下,输入有3个通道。
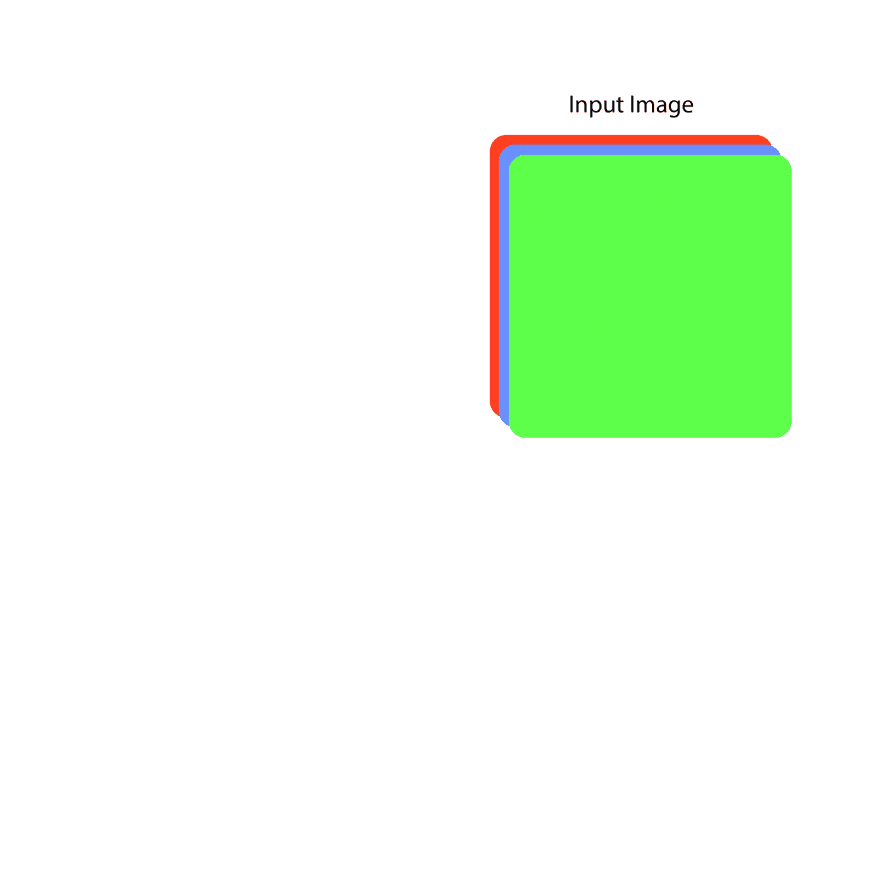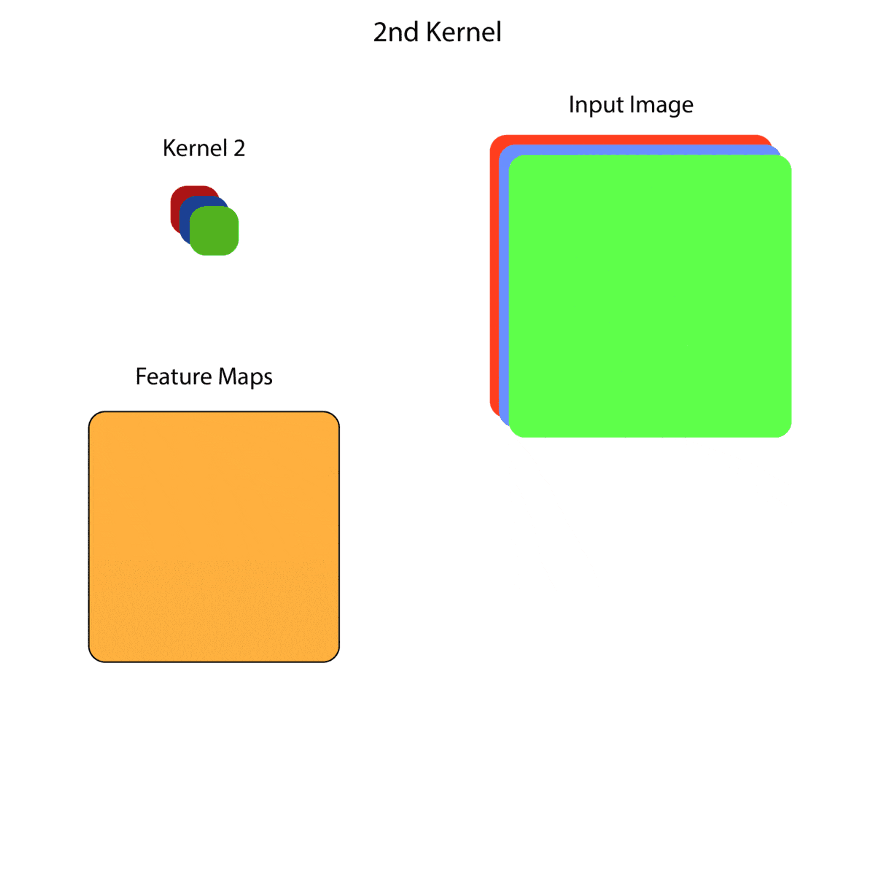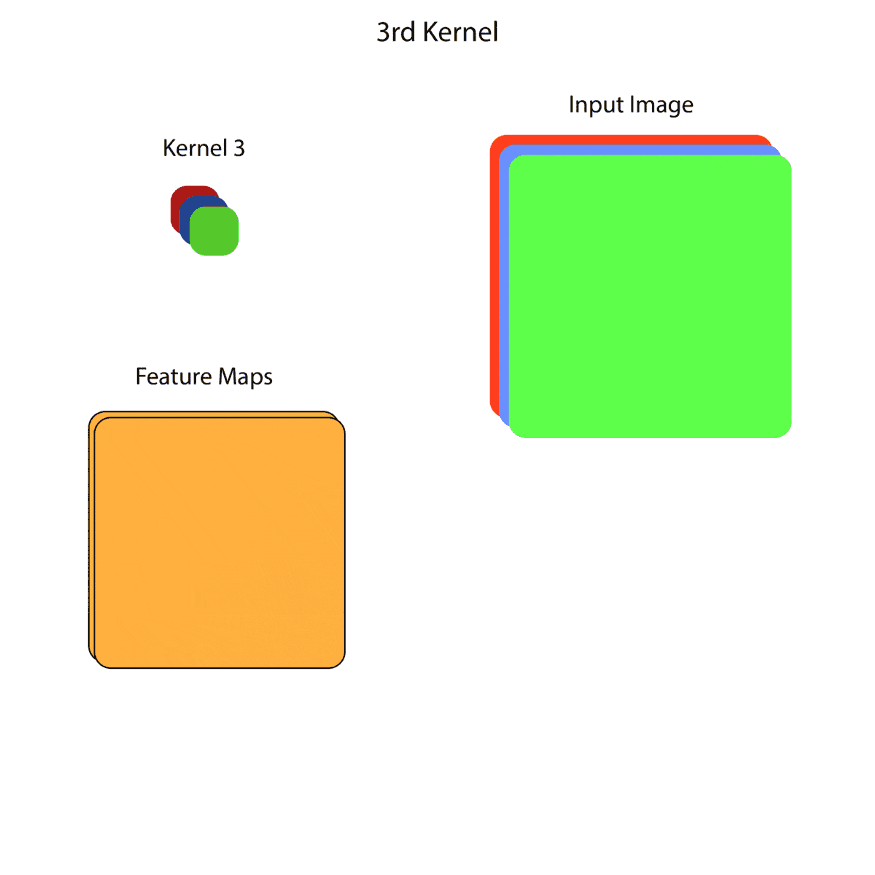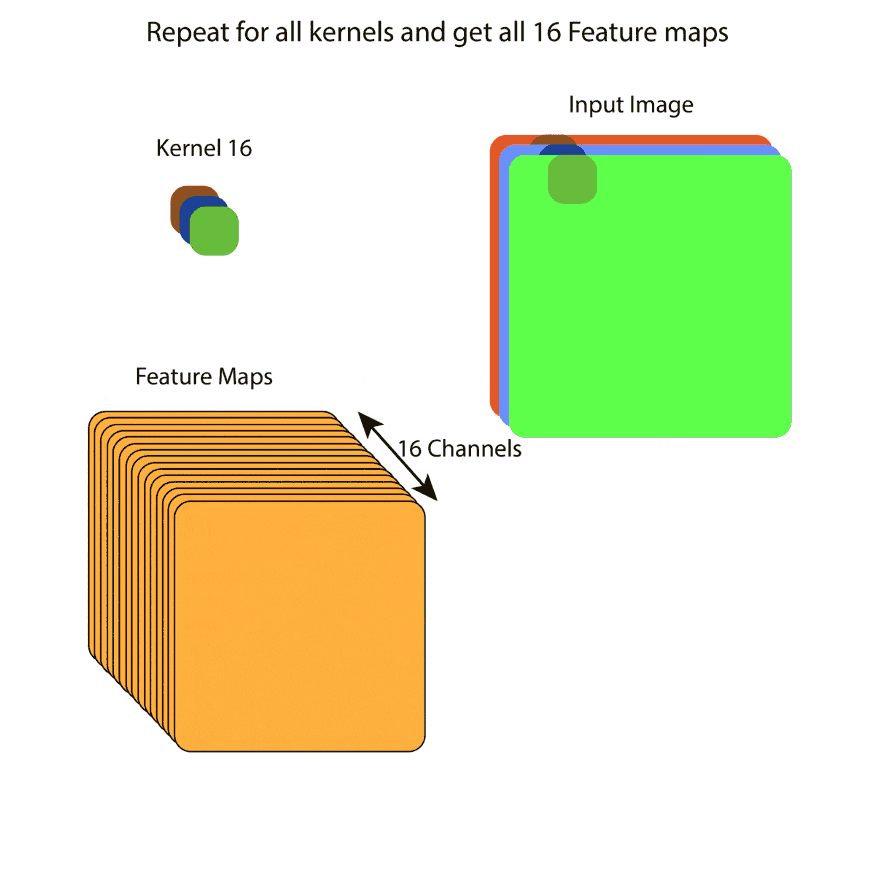
在本例中,输入有3个通道,输出有16个通道。因此在这一层共有16个内核,每个内核的形状是(wxhx3)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1443
1443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









