







- ResilientFL '21: Proceedings of the First Workshop on Systems Challenges in Reliable and Secure Federated Learning, Virtual Event / Koblenz, Germany, 25 October 2021. ACM 2021, ISBN 978-1-4503-8708-8
- FedScale: Benchmarking Model and System Performance of Federated Learning.
- FedScale:联邦学习的基准模型和系统性能
- Redundancy in cost functions for Byzantine fault-tolerant federated learning.
- 拜占庭容错联邦学习的成本函数的冗余性。
- 了解拜占庭
- Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent
- 面对反对者的机器学习:拜占庭容忍度的梯度下降
- Towards an Efficient System for Differentially-private, Cross-device Federated Learning.
- 争取建立?(对于)一个高效的差异化私有、跨设备联邦学习的系统。
- 新想法:该系统旨在即使在一小部分设备是恶意的并且没有可信核心的情况下也能有效地提供差异隐私
- 使用DP增强FedAvg
- 加法同态加密AHE + 中央DP(CDP) 组合起来
- Orchard
- 特点和缺点
- 特点
- 基于CDP(中央差分隐私)最先进的系统
- 混合使用 MPC [11]、AHE 和 Merkle 树 [14] 等加密原语来保证大规模 DP
- 聚合器偶尔是拜占庭式的,一小部分设备是恶意的
- 还通过使用 ZK-proofs [4]提高了训练的可靠性
- 缺点
- 参数的下载量太大了和每台设备的训练时间太久了
- 特点
- Orchard 遵循收集和验证方法
- 在收集阶段,聚合器从设备收集加密的梯度和 ZK 证明
- 设备的计算时间主要由生成ZK 证明的时间决定
ZK 证明表明梯度在指定范围内并且它们的加密已正确执行
- 计算!!!!,和本地CPU有关系
- 设备的计算时间主要由生成ZK 证明的时间决定
- 在验证阶段,设备验证聚合器的工作,它正确地执行了求和
- 在验证期间,设备的成本主要由网络下载决定
- 上传和下载!!!,和网络有关系
- 本方法高成本的核心原因是因为全批(非随机)梯度下降
- 在收集阶段,聚合器从设备收集加密的梯度和 ZK 证明
- 特点和缺点
- 本文讨论的Atom系统
- 随机FedAvg,精准度与Orchard的全批梯度下降近乎一样
即使一小部分设备在一轮中贡献梯度,训练精度也可以具有竞争力
- 随机FedAvg,精准度与Orchard的全批梯度下降近乎一样
- GradSec: a TEE-based Scheme Against Federated Learning Inference Attacks.
- GradSec: 一个基于TEE的方案,对抗联邦学习推理攻击。
- Community-Structured Decentralized Learning for Resilient EI.
- 社区结构化的分散学习,促进有弹性的EI(边缘智能)。
- 向去中心化EI演变的不同范式

- 人们研究了许多完全去中心化的方法、改进和实现
- 完全去中心化的学习范式的现状却有两个问题需要考虑
- 虽然在集中式分布式学习方案( centralized distributed learning schemes)和流言学习(gossip learning)中已经引入了通过选择性协作的通信效率,但在完全去中心化的学习中还没有充分考虑到这一点
Gossip Learning as a Decentralized Alternative to Federated Learning
- 虽然在其他分布式学习方案中已经引入了特定应用的个性化方法[14, 18],但现有的关于完全分散学习的工作并没有考虑利用数据和特征的亲和力来实现个性化应用的模型的本地化的潜力。
- 虽然在集中式分布式学习方案( centralized distributed learning schemes)和流言学习(gossip learning)中已经引入了通过选择性协作的通信效率,但在完全去中心化的学习中还没有充分考虑到这一点
- 完全去中心化的学习范式的现状却有两个问题需要考虑
- 人们研究了许多完全去中心化的方法、改进和实现
- 分散的社区识别(Decentralized Community Identification)
- 运行下一个单词预测的手机可以根据相似的地理和人口特征合并成社区,从而提供更相关的预测。
- 分散学习算法(Decentralized Learning Algorithms)(感兴趣的)
- 内容
- Decentralized Learning Algorithms. Decentralized learning algorithms are necessary for decentralized model training, local aggregation, model sharing, and local or collaborative inference. Reinventing these algorithms may not be necessary and so far, several decentralized learning paradigms [2, 4 , 10 , 11 , 15 ] have been studied and improved [ 11 , 12 , 27 ]. The selection of these algorithms per application is a well-acknowledged problem generally in EI [6 , 39 ], and, in pursuing community-structured decentralized learning specifically, needs to consider the more consistent exposure to fewer data sources when compared to general decentralized learning. Furthermore, work must also be done in adapting existing algorithms to the specific needs of edge applications, especially to facilitate personalization and localization. For example, many works on consensus strategies in decentralized paradigms [13, 17 ] are aimed at singular global convergence among the entire network, which is useful in some applications but not all. Many applications favor differentiated and more localized outcomes, such as predictive text in the NLP domain [ 14], and thus decentralized learning algorithms should be adapted to accommodate differentiated behavior among communities to produce useful differentiation of models.(去中心化学习算法。去中心化学习算法是去中心化模型训练、局部聚合、模型共享以及局部或协作推理所必需的。重新发明这些算法可能没有必要,到目前为止,已经研究和改进了几个分散学习范式[2,4,10,11,15][11,12,27]。每个应用程序选择这些算法通常是EI中公认的问题[6,39],并且,在追求社区结构的去中心化学习时,与一般的去中心化学习相比,需要考虑更一致地暴露于更少的数据源。此外,还必须使现有算法适应边缘应用程序的特定需求,特别是促进个性化和本地化。例如,许多关于去中心化范式中的共识策略的工作[13,17]都是针对整个网络的单一全局收敛,这在某些应用中是有用的,但不是所有应用。许多应用程序倾向于差异化和更本地化的结果,例如NLP域[14]中的预测文本,因此去中心化学习算法应该适应社区之间的差异化行为,以产生有用的模型差异化。)
- 引用文献
- 2 Gossip training for deep learning
我们解决了加快卷积网络的训练速度的问题。在这里,我们研究了一种适应随机梯度下降(SGD)的分布式方法。并行优化设置使用了几个线程,每个线程在一个局部变量上应用单独的梯度下降法。我们提出了一种在不同线程之间分享信息的新方法,其灵感来自于八卦算法,并显示出良好的共识收敛特性。我们的方法称为GoSGD,具有完全异步和去中心化的优势。我们将我们的方法与最近在CIFAR-10上的EASGD进行比较,结果令人鼓舞。
- 2 Gossip training for deep learning
- 内容
- 基本构建模块(Basic Building Blocks.)
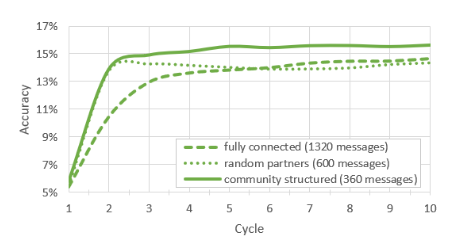
- 实验结果(社区结构的去中心化边缘学习可以提供更高的准确性和更低的通信开销。)
- Separation of Powers in Federated Learning (Poster Paper).
- 联邦学习中的权力分离(海报论文)。
- 本文介绍了 Truda,这是一种新的跨筒仓 FL系统,它采用值得信赖的去中心化聚合架构来打破与单个聚合器相关的信息集中。















10-15
 1689
1689
1689
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









