










卷积层使用
- 看到 CONV2D是大写的字母,就应该知道这个网页是在哪里:我之前说要回头看怎么做卷积的,就是在这里看到的:

- 上图中有一个link,里面有:

- 参数介绍:其中kernel可以选择其他形状的,在kernel_size中的tuple,可以自己设置特殊的形状:

关于channel
- 当图像是1个channel,而kernel是两个:于是,当input不止一个channel,kernel也不止一个,那么需要训练的东西就多了:

真是清清爽爽:

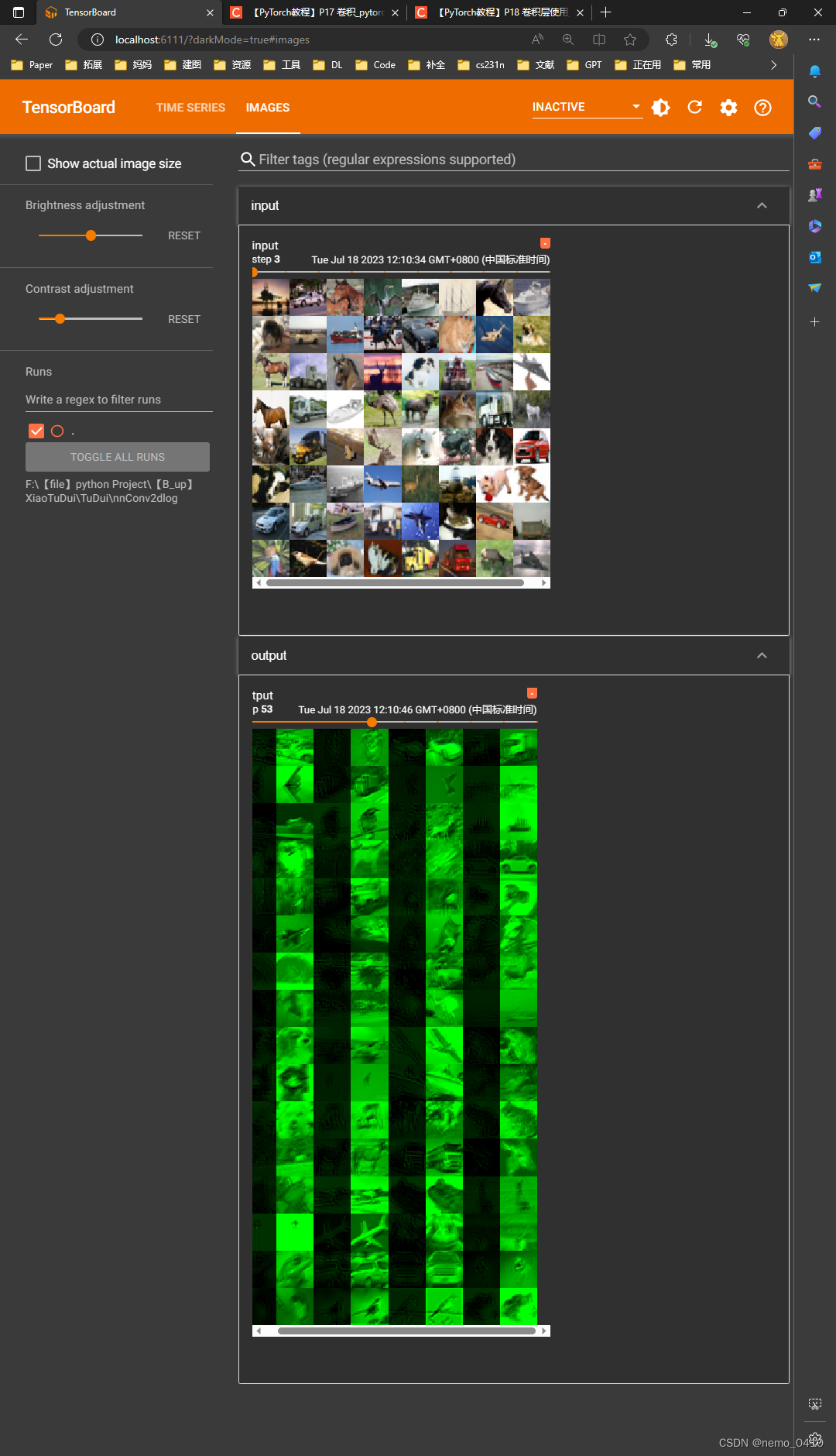
- 为了看,输入和输出的channel变化:(28-29行):batch_size都是64,没有变化,输入是3channel,输出是6channel,通道数多了,但是尺寸变小了,这就是卷积的作用和处理结果:


- 根据这个公式去计算,里面的padding和stride,以及channel和batch_size:他们之间是有一个方程关系的,能够严格计算出来:

- Vgg的框架,他的输出跟输入(前两层)是一样的大小,所以应该是做了padding来保证的:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月07日
"""
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
'''
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) # 初始化中,有一个卷积层
def forward(self, x):
x = self.conv1(x) # x 已经放到了卷积层 conv1当中了
return x
tudui = Tudui() # 初始化网络
print(tudui)
# 下面把每一张图像都进行卷积
for data in dataloader:
imgs, targets = data # data 由 imgs 和 targets 组成的,已经获得了图片,并且经过了 ToTensor的转换,已经是tensor类型,可以直接放进 网络 当中
# 疑问,targets 是什么? 为什么 data 由 imgs 和 targets 共同组成?前面有?
output = tudui(imgs)
print(imgs.shape) # 输出的结果为 torch.Size([64, 6, 30, 30]), torch.Size([64, 6, 30, 30])
print(output.shape) # 其中的 64,就是指的 DataLoader 中的 batch_size = 64
# channel 变成了 6
'''
'''
以下是加入了 logs 的版本
'''
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) # 初始化中,有了一个卷积层
def forward(self, x):
x = self.conv1(x) # x 已经放到了卷积层 conv1当中了
return x
tudui = Tudui() # 初始化网络
print(tudui)
# 下面把每一张图像都进行卷积
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data # data 由 imgs 和 targets 组成的,已经获得了图片,并且经过了 ToTensor的转换,已经是tensor类型,可以直接放进 网络 当中
# 疑问,targets 是什么? 为什么 data 由 imgs 和 targets 共同组成?前面有?
output = tudui(imgs)
print("imgs.shape:", imgs.shape) # 输出的结果为 torch.Size([64, 3, 30, 30]), torch.Size([64, 6, 30, 30])
print("output.shape:", output.shape) # 其中的 64,就是指的 DataLoader 中的 batch_size = 64, channel 由 3 变成了 6
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) 由于 6 个 channel 的图像,是无法显示的,所以,对这个图像进行处理,这里是通过batch_size来调整channel的,理论其实是有些站不住脚的
# torch.Size([xxx, 3, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30)) # 这个方法不是很严谨,目的是将 batch_size 降低,当不知道设置为多少合适时,设置为 -1 ,后面的参数会自己计算的
writer.add_images("output", output, step)
step += 1
writer.close()
2023.7.18补充:


















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









