










P30 GPU加速
- 调用 GPU的两种方法:
- 1、调用 .cuda()
- 在这三个内容后面,加上 .cuda()方法
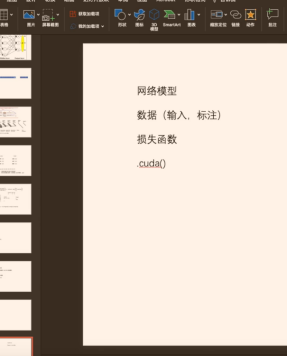
下图中,在原来的三种内容上,分别加上.cuda( ),就可以了:让他们的返回值,继续等于原来的变量名,就可以不用管框架中的其他内容了:



-
还有个loss function,不截图了。
-
还有更规范的写法,这样的写法,可以避免没有gpu的电脑上跑不通的弊端:

-
在视频中,还比较了cup和gpu的计算时间:
-
注意在哪里添加start_time和end_time,以及做差:
Cpu:

Gpu:

-
后面说了Google的GPU加速方法:
-
需要登录google账号,再访问:Google.colaboratory.com

-
具体操作:
-
新建笔记本:

print(torch.version)
print(torch.cuda.is_avaiable( )):应该是报错的:按图中位置,找到笔记本设置,选择gpu:

- 选择好了之后,重新载入import torch等环境:

-
!nvidia-smi 查看硬件版本(上面的代码都是python代码,直接 + 代码,点击三角运行就行;想要在terminal中运行命令,在最前面加上!就可以)

-
修改 笔记本设置 找到 硬件加速器 设为 GPU


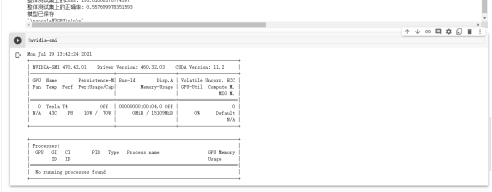

- 还是挺好用的,不过,我最近登录之后被分配的GPU不是T4了,也没有16Gb显存:

可以运行的代码
# !usr/bin/env python3
# -*- coding:utf-8 -*-
"""
author :24nemo
date :2021年07月12日
"""
import time
import torch
import torchvision
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 这是GPU加速训练的第一部分
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 这是GPU加速训练的第二部分
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
# 添加开始时间
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 这两行是GPU加速的第三部分(未完)
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # 这两行也是必不可少的,GPU加速训练的部分
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的 Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
两种GPU训练方式
方式一:
网络模型、损失函数、数据(输入、标注)
调用 .cuda
以上三者有cuda方法,能够实现
'''
"""
google的GPU
"""
















 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









