










从有代码的课程开始讨论
【Pytorch深度学习实践】B站up刘二大人之LinearModel -代码理解与实现(1/9)
【Pytorch深度学习实践】B站up刘二大人之 Gradient Descend-代码理解与实现(2/9)
【Pytorch深度学习实践】B站up刘二大人之 BackPropagation-代码理解与实现(3/9)
【Pytorch深度学习实践】B站up刘二大人之LinearRegressionwithPyTorch-代码理解与实现(4/9)
【Pytorch深度学习实践】B站up刘二大人之LogisticsRegression-代码理解与实现(5/9)
【Pytorch深度学习实践】B站up刘二大人之MultipleDimensionLogisticRegressionModel-代码理解与实现(6/9)
【Pytorch深度学习实践】B站up刘二大人之Dataset&DataLoader-代码理解与实现(7/9)
【Pytorch深度学习实践】B站up刘二大人之SoftmaxClassifier-代码理解与实现(8/9)
【Pytorch深度学习实践】B站up刘二大人之BasicCNN & Advanced CNN -代码理解与实现(9/9)
Lecture02——Linear Model
详细过程:
- 本课程的主要任务是构建一个完整的线性模型:
- 导入
numpy和matplotlib库; - 导入数据
x_data和y_data; - 定义前向传播函数:
forward:输出是预测值y_hat
- 定义损失函数:
loss:损失函数定义为MSE:均方根误差
- 创建两个空列表,因为后面绘图的时候要用:
- 分别是横轴的
w_list和纵轴的mse_list
- 分别是横轴的
- 开始计算(我觉得这里没有训练的概念,只是单纯的计算每一个数据对应的预测值,然后让预测值跟真是y值根据MSE求损失):
- 外层循环,创建40个横坐标自变量:
- 用
w表示; - 在0.0~4.0之间均匀取点,步长0.1;
- 用
- 内层循环:核心计算内容
- 从数据集中,按数据对儿取出自变量
x_val和真实值y_val; - 先调用
forward函数,计算预测值w*x(y_hat) - 调用
loss函数,计算单个数据的损失数值; - 累加损失,并记下来(此处要提前初始化一个值为0的变量,后面才能不报错);
- 随意打印想要看到的内容,一般是打印
x_val、y_val、loss_val; - 在外层循环中(也就是每一个数据对儿计算的时候),都要把计算的结果,放进之前的空列表,用于绘图;
- 从数据集中,按数据对儿取出自变量
- 外层循环,创建40个横坐标自变量:
- 导入
- 在获得了打印所需的数据列表只有,模式化地打印图像:
plt.plot(w_list, mse_list)
plt.xlabel(‘w’)
plt.ylabel('Loss)
plt.show()
备注:本例中,只有计算的过程,并没有训练一说,我想我写到这,线性模型这个代码,我才算是全懂了。
详情请看:
【Pytorch深度学习实践】B站up刘二大人之LinearModel -代码理解与实现(1/9)
Lecture03——Gradient Descent 梯度下降(cost function)
说在前面:这部分分两块,一个是基于cost function的,也就是全数据集上的代价函数,另一个是从中随机抽取一个数据,基于loss function的,也就是损失函数,二者在forward、loss的函数构建、训练过程中的数据加载环节都有所区别,要注意区分,搞清搞透;
详细过程:
- 本课程的主要任务是构建第一个带有初始权重和训练过程的梯度下降模型:
- 导入
numpy和matplotlib库; - 导入数据
x_data和y_data; - 定义前向传播函数:
forward:输出是预测值y_hat
- 定义代价函数:
cost:损失函数定义为MSE:均方根误差- 此处要使用循环,把数据集中的数据对儿,一组一组地取出来,再做计算;
- 返回值需要归一化至单个数据的损失值;
- 定义梯度计算函数:
- 这个函数
gradient很有意思,也不简单:需要根据反向传播,计算出代价函数对于权重的梯度,计算结果为grad += 2 * x * (x * w - y); - 返回值同样需要归一化至单个数据的梯度;
- 这个函数
- 创建两个空列表,因为后面绘图的时候要用:
- 分别是横轴的
w_list和纵轴的mse_list
- 分别是横轴的
- 开始训练:
- 循环的次数
epoch可以自定义:- 首先调用代价函数
cost计算数据集的代价值,注意,这里要传入所有数据,而不是再去用·zip·函数配合·for·循环每次取一个,因为在`cost·函数当中,已经写过单个数据对儿从数据集调出的过程; - 再调用梯度计算函数
grad,与上个函数相同; - 核心来了——更新权重:
- 就是最经典的权重更新公式,用现有权重,减去学习率乘以梯度的乘积,每轮(epoch)训练都要循环更新;
- 此处尚不涉及权重清零的问题,这个问题后面也要详细记录,务必搞得非常透彻,因为它涉及到计算图的是否构建,以及tensor数据类型具有data和grad两个属性的问题(TBD);
- 随意打印想要看到的内容,一般是打印
x_val、y_val、loss_val; - 在循环中要把计算的结果,放进之前的空列表,用于绘图;
- 首先调用代价函数
- 循环的次数
- 导入
- 在获得了打印所需的数据列表只有,模式化地打印图像:
-略
Lecture03——Gradient Descent 梯度下降(loss function)
【Pytorch深度学习实践】B站up刘二大人之 Gradient Descend-代码理解与实现(2/9)
详细过程:
- 回头仔细看了看代码,其实区别并不大;
- 之前没理解的原因,不在于
cost和loss的区别,而在于权重更新那里我没有懂透; - 区别:
forward函数没有变化;loss、gradient函数有变化,把cost当中,原本需要把数据对儿从数据集中取出的过程,全部转移到训练过程中,这个过程不是难点,不过刚动手写的时候,就会很困惑,尤其是别的地方也有困惑,就觉得难度很大,应付不过来;
详情请看:
【Pytorch深度学习实践】B站up刘二大人之 Gradient Descend-代码理解与实现(2/9)
Lecture04——BackPropagation 反向传播
【Pytorch深度学习实践】B站up刘二大人之 BackPropagation-代码理解与实现(3/9)
- 本课程的主要任务是利用
torch包的requires_grad自动求导,构建反向传播模型:-
导入
numpy和matplotlib库; -
导入数据
x_data和y_data; -
初始化一个
w数值,这里要用torch.Tensor构建; -
把
w的requires_grad参数打开;(重点) -
定义前向传播函数:
forward:输出是预测值y_hat
-
定义损失函数:
loss:损失函数定义为MSE:均方根误差
-
定义梯度计算函数:
gradient: 需要根据反向传播,计算出代价函数对于权重的梯度,计算结果为grad += 2 * x * (x * w - y);
-
创建两个空列表,因为后面绘图的时候要用:
-
开始训练:
- 外层循环,循环的次数
epoch可以自定义: - 内层循环:核心计算内容
- 从数据集中,按数据对儿取出自变量
x_val和真实值y_val; - 直接调用
loss函数,计算单个数据的损失数值; - 用
backward函数直接对损失值做反向传播; - 核心来了——更新权重:
- 对
w的grad.data做更新,这是重要一步,也是内容非常丰富的地方,不仅是更新了权重,里面还有关于tensor的其他基础知识,data和grad的关系,data是不会构建计算图的,而grad是在构建计算图模型;
- 对
- 此处仍不涉及权重清零的问题(TBD);
- 随意打印想要看到的内容,一般是打印
x_val、y_val、loss_val; - 在循环中要把计算的结果,放进之前的空列表,用于绘图;
- 从数据集中,按数据对儿取出自变量
- 外层循环,循环的次数
-
- 在获得了打印所需的数据列表只有,模式化地打印图像:
- 略
详情请看:
【Pytorch深度学习实践】B站up刘二大人之 BackPropagation-代码理解与实现(3/9)
Lecture05 —— LinearRegressionWithPyTorch 利用PyTorch实现线性回归模型
【Pytorch深度学习实践】B站up刘二大人之LinearRegressionwithPyTorch-代码理解与实现(4/9)
说在前面:
- 这部分内容有不少更新指出:
(1)构建数据集用到了torch中的Tensor;
(2)通过创建python中的线性模型类,并实例化它,来构建模型;
(3)损失函数通过torch.nn库调用其中的MSELoss;
(4)优化器通过调用torch.optim库中的SGD实现;
(5)训练过程稍有变化,这里面第一次出现了梯度清零这个问题,用到的是优化库optim中的zero_grad()方法;
详细过程:
- 本课程的主要任务是利用
torch包的requires_grad自动求导,构建反向传播模型:-
导入
numpy、matplotlib、os、torch库; -
导入数据
x_data和y_data,注意这里有变化,用到了torch中的Tensor格式,与04课程相同,所以才会出现data和grad的重要区别; -
创建LinearModel类模型:
- 初始化
init中,只有一个linear函数;注意要提前继承(这一步直接写,不深究); - 前向传播
forward方法,这是把之前的前向传播函数,拿进来做了类中的一个方法,返回预测值;
- 初始化
-
实例化一个模型
model; -
创建损失函数:通过调用
torch.nn库中的MSELoss实现; -
创建优化器:通过调用
torch.optim库中的SGD实现; -
创建两个空列表,因为后面绘图的时候要用:
-
创建循环,开始训练:循环的次数
epoch可以自定义y_hat用模型model计算;- 损失
loss用创建好的损失函数计算; - 先用优化器对梯度清零(重要,要清楚什么时候该清零,为什么清零,原理是什么);
- 令损失反向传播
loss.backward; - 执行一步权重更新操作,用到的函数
optimizer.step( )很奇特,这里非常关键,理解起来不容易,见下面的链接;
-
在循环中要把计算的结果,放进之前的空列表,用于绘图;
-
在获得了打印所需的数据列表只有,模式化地打印图像:
- 略
-
详情请看:
【Pytorch深度学习实践】B站up刘二大人之LinearRegressionwithPyTorch-代码理解与实现(4/9)
本节重要参考:
理解optimizer.zero_grad(), loss.backward(), optimizer.step()的作用及原理
Lecture06 —— LogisticsRegression 逻辑回归模型
说在前面:
- 虽然这叫回归模型,但是它分两种:能用于回归,也能用于分类;
- 本节是讲的二分类,背景是:学习多少小时能够考试通过;
- 训练好模型以后,直接用来预测,4小时的学习,能够通过的概率是多大?
详细过程(本节开始,只说与之前代码的不同之处):
- 在加载工具包的时候,由于要使用
sigmoid的函数,而这个函数,是在torch.nn.functional当中的,所以,先设置一个句柄等待使用:torch.nn.functional as F; - 导入的数据中,
y_data的值,不再是原来的预测:学习多久,得多少分?而是:x_data个小时,是否会通过考试,把原本的预测回归问题,转为预测分类问题,而且此处是二分类,最终预测结果只有0和1,要么通过,要么不通过; - 在用于创建模型的类中,需要把原本的前向传播,计算结果转为概率,那么就需要用到
sigmoid函数,这个函数,值域是(0,1),把原本输出的得分数值转为能够通过考试的概率,就是在这里用到了F这个函数句柄,F.sigmoid; - 另一个变化是损失函数,这里不在使用原本的
MSE函数,而是使用分类任务常用的交叉熵损失函数,这个里面的原理,需要懂,刘老师讲完一下子就理解了,用到了torch,nn,BCELoss函数; - 由于是分类任务,那么最后的预测,与之前的回归任务就不一样了,测试的时候,直接把一个需要预测的值传入模型当中:
x_test = torch.Tensor([[4.0]]) y_test = model(x_test)
详情请看:
【Pytorch深度学习实践】B站up刘二大人之LogisticsRegression-代码理解与实现(5/9)
Lecture07 —— MultipleDimensionLogisticRegressionModel 多维输入的逻辑回归模型
【Pytorch深度学习实践】B站up刘二大人之MultipleDimensionLogisticRegressionModel-代码理解与实现(6/9)
说在前面:
- 这部分内容有不少更新指出:
(1)这节课的内容跟上一节的递进关系,在于输入数据的维度,不再是原本的一维数值(标量);
(2)而是升级为多维向量,这更符合多个自变量共同影响输出的实际应用场景;
(3)想起了吴恩达课程中的房价预测模型,卧室数量、厨房数量等,可以绑定在一起构成向量的形式,作为输入。
详细过程:
- 本课程的主要任务是通过将原本简单的标量输入,升级为向量输入,构建线性传播模型:
- 在导入数据阶段就有很大不同:
- 由于课程中导入的数据是
anaconda安装工具包中的自带的压缩文本数据,所以直接采用numpy中的loadtxt读取,这个函数可以直接读取Linux下压缩的格式,此处是.gz; - 后面还有两个参数,一个是分隔的字符类型,此处是逗号,另一个是数据的类型,刘老师在课程中讲,只有高端的显卡,才会读取
double类型的数据,而普通的显卡读取float32;
- 由于课程中导入的数据是
- 将导入的数据,分成自变量和
label,这是在文本文件中已经确定好了的,最后一列为y_data,其余为x_data; - 创建Model类模型(有巨大变化,非常重要):
- 初始化
init中,不再只有一个linear函数;- 要根据线性层的输入和输出要求,自定义不同的
self.linear,此处是8 → 6 → 4 → 1;其中两个参数分别为in_channel数量和out_channel数量; - 接着,要跟一个
Sigmoid函数,将最终的输出值,转为0-1区间上的概率值,这个内容是上一节中通过函数句柄F.sigmoid实现的,但此处的函数名称要大写,容易出错;
- 要根据线性层的输入和输出要求,自定义不同的
- 前向传播
forward中,直接调用init中定义好的各层,此处要注意,输入为x,返回值也定义为x吧:x = self.sigmoid(self.linear1(x)),否则出错了不好排除问题,并且sigmoid是小写开头,因为在init中,定义的时候,是以小写开头定义的,注意逻辑;
- 初始化
- 在导入数据阶段就有很大不同:
- 此处跟后续修改内容有很强的联系,刘老师在本节课中没有做运行和输出训练损失曲线等,在其他笔记中找到了相关的内容,做了一个输出显示,在详情中可以查看;
详情请看:
【Pytorch深度学习实践】B站up刘二大人之MultipleDimensionLogisticRegressionModel-代码理解与实现(6/9)
Lecture08 —— Dataset&DataLoader 加载数据集
【Pytorch深度学习实践】B站up刘二大人之Dataset&DataLoader-代码理解与实现(7/9)
说在前面:
-
本节内容,主要是把数据集写成了一个类,这个类要继承
Dataset类,有点像DIY一个数据集的感觉,只有自定义了之后,才能实例化,然后把之前直接在文件夹中读取数据的方式进行了修改; -
后面加载数据的
DataLoader(注意L大写),直接可以调用对数据集类做了实例化的对象,即把他当做一个参数,传入DataLoader当中;
详细过程:
- 本课程的主要任务是通过将原本简单的标量输入,升级为向量输入,构建线性传播模型:
- 在导入数据阶段就有很大不同:
- 数据集类里面有三个函数,这三个函数较为固定,分别自己的作用;
- 继承
Dataset后我们必须实现三个函数:__init__()是初始化函数,之后只要提供数据集路径,就可以进行数据的加载,也就是说,传入init的参数,只要有一个文件路径就可以了;getitem__()通过索引找到某个样本;__len__()返回数据集大小;
- 在导入数据阶段就有很大不同:
详情请看:
【Pytorch深度学习实践】B站up刘二大人之Dataset&DataLoader-代码理解与实现(7/9)
Lecture09 —— SoftmaxClassifier 多分类器的实现
【Pytorch深度学习实践】B站up刘二大人之SoftmaxClassifier-代码理解与实现(8/9)
说在前面:
- 这节课的内容,主要是两个部分的修改:
- 一是数据集:直接采用了内置的
MNIST的数据集,那dataloader和dataset自然也是内置的,那也就不用自己写dataset再去继承Dataset类; - 再有是把
train和test写成了函数形式,直接在main函数当中调用即可;
- 一是数据集:直接采用了内置的
- 除了本节课想要实现的代码,刘老师在本节课前一半讲了这些内容:
- 下了很大功夫讲清楚了
softmax这个函数的机理:y_pred = np.exp(z) / np.exp(z).sum(); - 还有交叉熵损失函数是什么一回事,非常流畅简洁地给我讲懂了这个公式的意思:
loss = (- y * np.log(y_pred)).sum(); - 根据这两个函数的理论,用
numpy的计算法则把公式实现了,之后才去调用了pytorch当中写好了的函数; - 还强调了
NLL-Loss的概念,并且留了思考题,为什么会:CrossEntropyLoss <==> LogSoftmax + NLLLoss? - 到了
pytorch当中,里面有Softmax和Softmax_log两个函数版本;
- 下了很大功夫讲清楚了
详情请看:
【Pytorch深度学习实践】B站up刘二大人之SoftmaxClassifier-代码理解与实现(8/9)
Lecture10 —— Basic & Advanced CNN 基础 & 高级-卷积神经网络
【Pytorch深度学习实践】B站up刘二大人之BasicCNN & Advanced CNN -代码理解与实现(9/9)
说在前面:
这节课的有两个部分,基础卷积神经网络和高级别卷积神经网络:
Basic CNN 卷积神经网络 基础
-
对于基础知识,不写代码了,把所有讲到的知识点,和每个知识点该注意的,以及扩展知识整理记录:
- 卷积的概念:
-
从单通道卷积讲起:即
input图像是单通道,卷积核kernel也是单通道,那么输出必然也是单通道。这里还没有讲到扩充padding和滑动步长stride,所以只关注输入和输出矩阵的尺寸大小; -
讲到这,刘老师介绍了
CCD相机模型,这是一种通过光敏电阻,利用光强对电阻的阻值影响,对应地影响色彩亮度实现不同亮度等级像素采集的原件。三色图像是采用不同敏感度的光敏电阻实现的。 -
还介绍了矢量图像(也就是PPT里通过圆心、边、填充信息描述而来的图像,而非采集的图像);
-
接下来讲到三通道
input图像的卷积操作:实为将三个通道的input分别与三个通道kernel对应相乘,再将对应位置相加,最后输出单通道output图像的过程; -
此处的
input、kernel、output的形状,以及通道数channel,是要非常注意的,我们玩卷积神经网络,其中,向的卷积层中传递的参数,与这里的参数一一对应,要非常熟悉每一个参数位置,应该是谁的channel值,后面的full connected layer也是一样,传入的是位置参数,也就是说,每一个位置必须是所需对应的参数,决不能混乱; -
这里还有个我以前搞不清的地方,在刘老师的课上听明白了:就是这种图是什么意思,长宽高分别对应的是图像的宽高通道数,分别怎么对应的,我得插一张图了(这应该是篇博客第一章图):
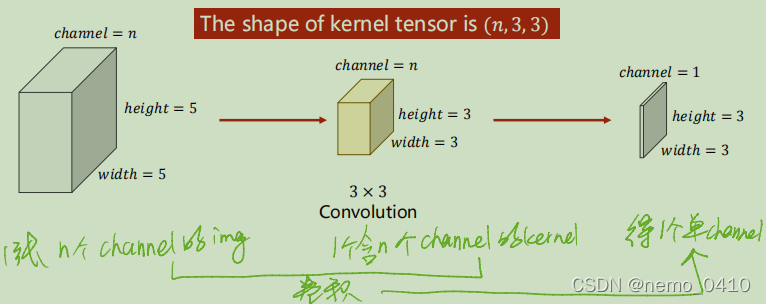
-
以上是单个卷积核的获取的结果,也就是说,上图中见
kernel的位置,仅仅是一个(组)卷积核;如果我们要提取不同的特征,就需要不同(组)的卷积核,也就是说,会出现这样一种情况:
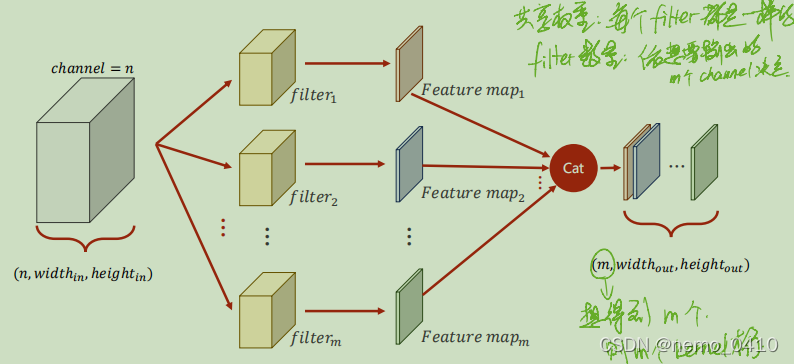
-
于是,kernel其实是一个4维的
tensor,每一个(组)filter是三维,多个这样的filters,就需要是4个dimension的概念,你,看懂了吗。 -
接下来讲了卷积层建立的方式,以及代码的简单实现,详细内容见本节插入的链接;
-
在后面讲了三个卷积的基本操作,扩充
padding、步长stride和池化pooling:padding是为了让源图像最外一圈或多圈像素(取决于kernel的尺寸),能够被卷积核中心取到。这里有个描述很重要:想要使源图像(1,1)的位置作为第一个与kernel中心重合,参与计算的像素,想想看padding需要扩充多少层,这样就很好计算了吧;stride操作指的是每次kernel窗口滑动的步长,默认值当然是1了,插句话,假设不使用扩充padding,output图像的尺寸就会缩小,想要使输出的尺寸与输入尺寸保持不变,看看上一个知识点的padding描述,就很好计算需要外圈加几圈去保证输出的尺寸了吧;
-
这里插入一段代码,这段代码中
input和kernel后面的view函数,输入的位置参数含义是不一样的,看图可知细节:

-
- 接下来讲了一个简单的卷积神经网络的例子,这个例子需要记住并会用,详见节尾链接;只有一个地方需要特别注意的地方,就是整个网络建立完以后,是不关心输入图像的宽度和高度大小的,也就是说,无论来多大尺寸的图像,我(网络)都能处理,需要改动的仅是
Fully Connected Layer(分类器)的输入,需要通过前面最后一层的计算来求得;而FCY的输出,是确定的(分10类就输出10); - 将模型送入
GPU的过程,可以参看我其他的博客,关于这个知识点,我是觉得土堆的讲解更好,整个网络,有三个内容需要传入GPU去计算:[1]网络模型、[2]数据(input和label)、[3]损失函数loss。参见【PyTorch教程】P30 GPU加速;
- 卷积的概念:
-
至此,刘老师
Basic CNN这节课的全部知识点都在这里了,代码的简单实现见节尾链接。
Advanced CNN 卷积神经网络 高级
- 进入高阶
CNN,刘老师在这节课里讲了两个网络,一个是GoogLeNet,另一个是ResNet。分别记录重点:GoogLeNet:以往无论的LinearModel还是SoftmaxClassifier,其网络结构都是一个线性且没有‘岔路’的传递形式,成为单线结构,但效果一般;GoogLeNet是一种串行结构的复杂网络;想要实现复杂网络,并且较少代码冗余和多次重写相同功能的程序,面向过程的语言使用函数,面向对象的语言python使用类,而在CNN当中,使用Module和block这种模块将具有复用价值的代码块封装成一块积木,供拼接使用;GoogLeNet为自己框架里被重复使用的Module命名为Inception,这也电影盗梦空间的英文名,意为:梦中梦、嵌套;GoogLeNet设计了四条通路支线,并要求他们保证图像的宽和高W、H必须相同,只有通道数C可以不相同,因为各支线进行过卷积和池化等操作后,要将W和H构成的面为粘合面,按照C的方向,拼接concatenate起来;GoogLeNet的设计思路是:我把各种形式的核都写进我的Block当中,至于每一个支路的权重,让网络训练的时候自己去搭配;1 * 1的卷积核:以往我只是表面上觉得,单位像素大小的卷积核,他的意义不过是调整输入和输出的通道数之间的关系;刘老师举了个例子,让我对这个卷积核有了新的认识:就是加速运算,他的作用的确是加速运算,不过其中的原理是:通过1*1的核处理过的图像,可以减少后续卷积层的输入通道数;

GoogLeNet代码当中需要注意的是卷积层的输入和输出通道数,里面涉及的细节与其他层之间的差异要特别注意;- 最后在
cancatenate的时候,有一个参数是选择按照什么方向进行组合,这里的dim=1的原理在这:(B,C,W,H)按索引来讲,C指的是通道数,索引从零开始,C的位置是1,这个问题困扰了我好久,我一直都以为要死记硬背; GoogLeNet最后留下了一个问题:通过测试,网络的层数会影响模型的精度,但当时没有意识到梯度消失的问题,所以GoogLeNet认为We Need To Go Deeper;直到何凯明大神的ResNet的出现,提出了层数越多,模型效果不一定越好的问题,并针对这个问题提出了解决方案ResNet网络结构。ResNet之前,有过对梯度消失的解决方案:逐层训练。每当网络想要训练新一层的权重,就将其他层的权重锁住,逐渐将所有层的权重都确定下来,然而神经网络层数太多不容易做到,并且这也太蠢了,失去了人工智能的该有的智能;- 于是
ResNet提出了这样一种方式,来避免深度神经网络在训练过程中出现梯度消失导致靠前面的层没有被充分训练: - 以往的网络模型是这种
Plain Net形式:输入数据x,经过Weight Layer(可以是卷积层,也可以是池化或者线性层),再通过激活函数加入非线性影响因素,最后输出结果H(x);这种方式使得H(x)对x的偏导数的值分布在(0,1)之间,这在反向传播、复合函数的偏导数逐步累乘的过程中,必然会导致损失函数L对x的偏导数的值,趋近于0,而且,网络层数越深,这种现象就会越明显,最终导致最开始的(也就是靠近输入的)层没有获得有效的权重更新,甚至模型失效; ResNet采用了一个非常巧妙的方式解决了H(x)对x的偏导数的值分布在(0,1)之间这个问题:在以往的框架中,加入一个跳跃,再原有的网络输出F(x)的基础上,将输入x累加到上面,这样一来,在最终输出H(x)对输入数据x求偏导数的时候,这个结果就会分布在(1,2)之间,这样就不怕网络在更新权重梯度累乘的过程中,出现乘积越来越趋于0而导致的梯度消失问题;- 与
GoogLeNet类似,ResNet的Residual Block在搭建时,留了一个传入参数的机会,这个参数留给了通道数channel,Residual Block的要求是输入与输出的C,W,H分别对应相同,B是一定要相同的,所以就是说,经过残差模块Residual Block处理过的图像,并不改变原有的尺寸和通道数;(TBD) - 其余就是老生常谈的参数问题,记准每一个参数的含义;
- 课程最后刘老师推荐了两篇论文:
Identity Mappings in Deep Residual Networks:其中给出了很多不同种类的Residual Block变化的构造形式;Densely Connected Convolutional Networks:大名鼎鼎的DenseNet,这个网络结构基于ResNet跳跃传递的思想,实现了多次跳跃的网络结构,以后很多通过神经网络提取多尺度、多层级的特征,都在利用这种方式,通过Encoder对不同层级的语义特征进行逐步提取,在穿插着传递到Decoder过程中不同的层级上去,旨在融合不同层级的特征,尽可能地挖掘图像全部的特征;
详情请看:
【Pytorch深度学习实践】B站up刘二大人之BasicCNN & Advanced CNN -代码理解与实现(9/9)
【PyTorch教程】P30 GPU加速

















 5353
5353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









