






Repvgg也是第二回了,这次是重参数化对YOLO工业落地的实验和思考
借鉴repvgg重参化的思想,将原有的3×3conv替换成Repvgg Block,为原有的YOLO模型涨点。
之前做了一次shufflenetv2与yolov5的组合,目的是为了适配arm系列芯片,让yolov5在端侧设备上也能达到实时。但在gpu或者npu方面也一直在尝试着实验,对此类实验的目的很明确,要求也不高,主要还是希望yolov5在保持原有精度的同时能够提速。这一次的实验主要借鉴repvgg重参化的思想,将原有的3×3conv替换成Repvgg Block,为原有的YOLO模型涨点。
实验
这一次的模型主要还是借鉴repvgg重参化的思想,将原有的3×3conv替换成repvgg block,在训练过程中,使用的是一个多分支模型,而在部署和推理的时候,用的是多分支转化为单路的模型。
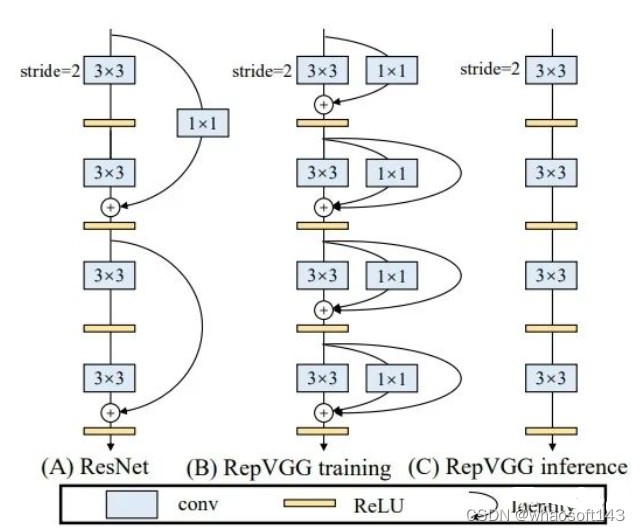
类比repvgg在论文中阐述的观点,这里的baseline选定的是yolov5s,对yolov5s的3×3conv进行重构,分出一条1×1conv的旁支。
在推理时,将旁支融合到3×3的卷积中,此时的模型和原先的yolov5s模型无二致
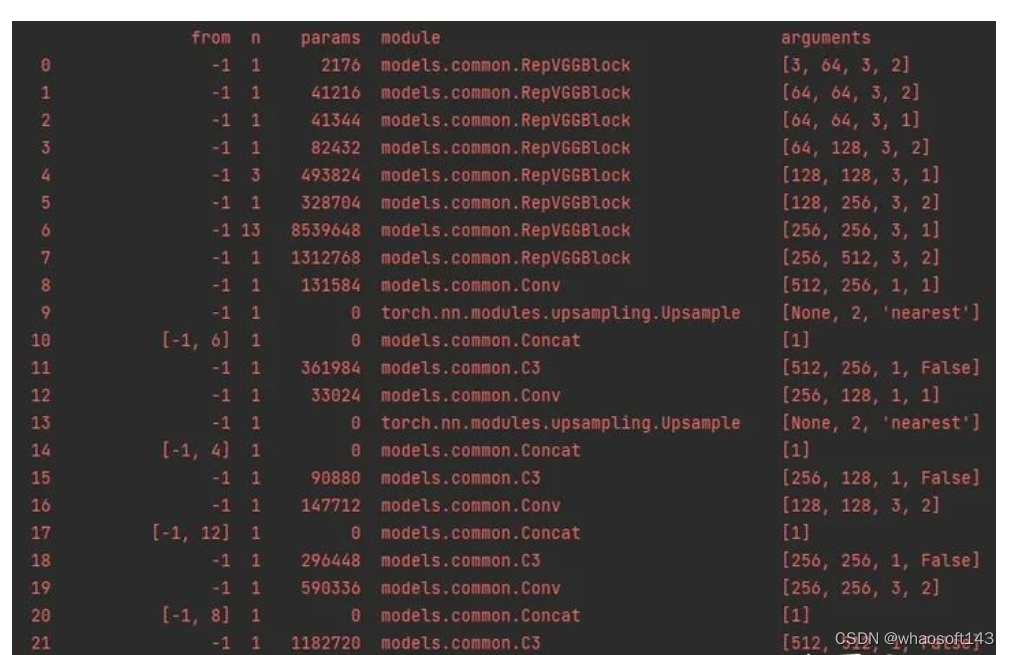
在次之前,采用的是最直接的方式对yolov5s进行魔改,也就是直接替换backbone的方式,但发现参数量和FLOPs较高,复现精度最接近yolov5s的是repvgg-A1,如下backbone替换为A1的yolov5s:
而后,为了抑制Flops和参数的增加,采取使用repvgg block替换yolov5s的3×3conv的方式。
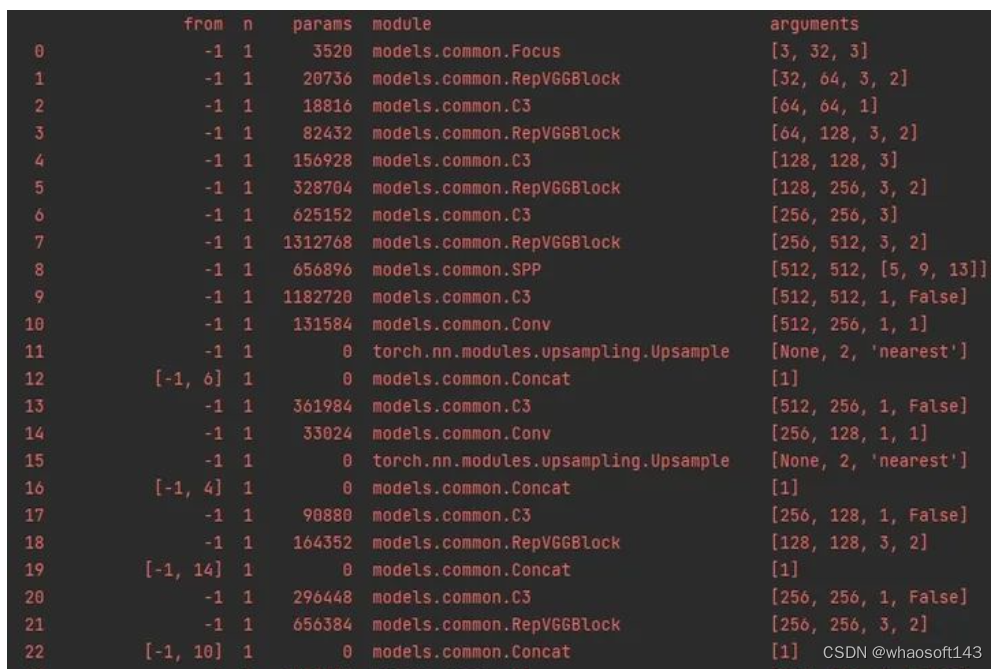
两者之间相差的Flops比和参数比约为2.75和1.85.
性能
通过消融实验,得出的yolov5s和融合repvgg block的yolov5s性能差异如下:
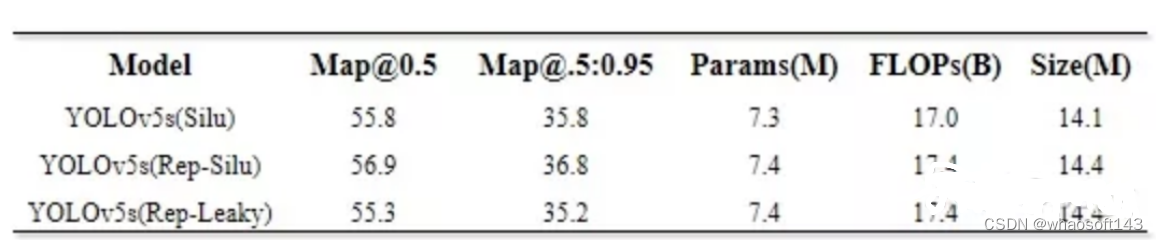
Rep指植入repvgg block模块,Silu和leaky指使用的激活函数
这里评估的yolov5s在map指标上和官网有所出入,测试两次后均为55.8和35.8,不过这个测试结果和GitHub - midasklr/yolov5prune (https://github.com/midasklr/yolov5prune)以及Issue #3168 · ultralytics/yolov5(https://github.com/ultralytics/yolov5/issues/3168)大致相同。使用repvgg block重构yolov5s的3×3卷积,在map@0.5和@.5:.95指标上均能至少提升一个点。
训练结束后的repyolov5s需要进行convert,将旁支的1×1conv进行融合,否则在推理时会比原yolov5s慢20%。
使用convert.py对repvgg block进行重参化,主要代码如下,参考https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py:
我们可以通过调用onnx模型对convert前后的模型进行可视化:
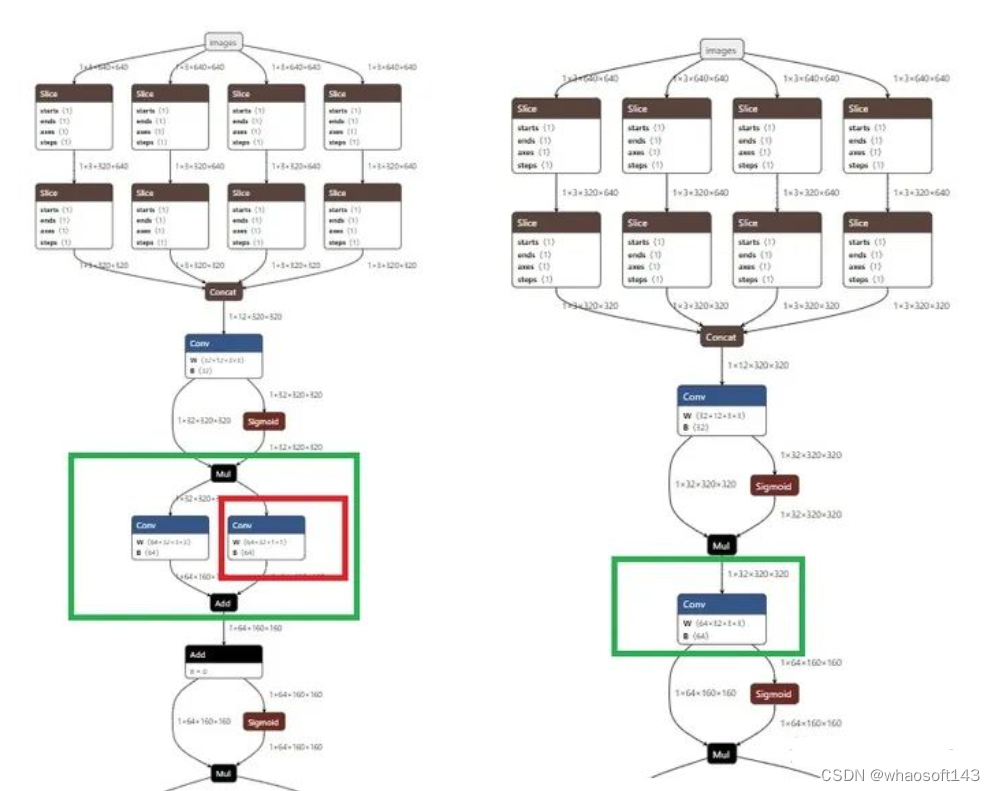
推理
map指标只是参考的一部分,还有一部分是关于reparam和fuse后的yolov5s会不会因为repvgg block的植入而变慢。在理论上,reparam后的repvgg block等价于3×3卷积,不过该卷积因为融合比普通3×3卷积更加紧凑。
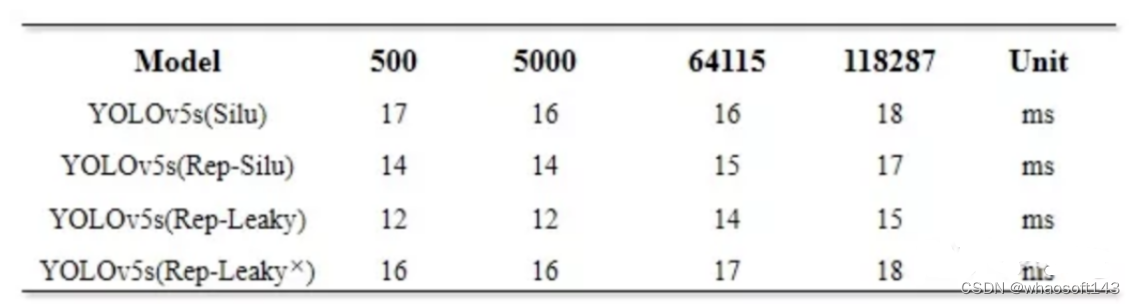
在测试三次coco val2017数据集后(5000张并进行单张推理),得出repyolov5s的单张推测时间为14/14/14(ms)、yolov5s为16/16/16(ms),这里和白神讨论了一下,白神认为两者极度接近的推理时间可能存在着测试误差,无任何说服性。
不过可以肯定的是convert后的yolov5s推理速度不会因为repvgg block植入而变慢。为了避免偶然性和测算误差,这里使用了500/5000/64115/118287张图片进行了推理测试:

左为植入repvgg block的yolov5s,右为原yolov5s
测试后的结果如下:
测试
检测效果应该也是大家关心的一个指标,使用以上两个模型,保证其他参数均一致,对图片进行检测,效果如下:

融合repvgg的yolov5s

原yolov5s
总结
使用repvgg block对yolov5s进行改进,通过消融实验,总结出以下几点:
- 融合repvgg block的yolov5s在大小尺度目标上均能涨点;
- 使用融合repvgg block和leakyrelu的yolov5s比原yolov5s在map上降低了0.5个百分点,但是速度可以提升15%(主要是替换了Silu函数起的作用);
- 如果不做convert,个人感觉这个融合实验毫无意义,旁生的支路会严重影响模型的运行速度;
- C3 Block和Repvgg Block在cpu上使用性价比低,在gpu和npu上使用才能带来最大增益
- 使用重参化的yolov5是有代价的,代价主要损耗均在训练方面,会多占用显卡大约5-10%的显存,训练时间也会增多
- 可以考虑使用repvgg block对yolov3-spp和yolov4的3×3卷积进行重构
参考:
https://github.com/ultralytics/yolov5/discussions/3181
Use activation function · Issue #584 · ultralytics/yolov5















 2651
2651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









