







RepVGG网络结构解读
简介
论文连接:https://arxiv.org/pdf/2101.03697v1.pdf
论文代码:https://github.com/DingXiaoH/RepVGG
作者单位:清华大学(丁贵广团队), 旷视科技(孙剑等人), 港科大, 阿伯里斯特威斯大学
提出了一种简单而强大的卷积神经网络结构,其推理阶段是仅由3*3卷积和RELU组成VGG风格的结构,训练阶段则具有多分支结构。这种训练-推理的解耦是利用一种叫做“重参数化(re-parameterization)”的技术实现的,因此,该网络被称为RepVGG。在ImageNet上能够达到超过80%的top-1准确率,这是直通式网络第一次达到如此高的性能。在 NVIDIA 1080Ti GPU上,RepVGG比ResNet-50快83%,比ResNet-101快101%,同时具有更高的精度。相比当前的SOTA模型,如EfficientNet、ResNet,RepVGG可以实现精度-速度之间的平衡。
VGG是一种简单的plain网络,没有复杂结构,只需要堆叠CNN层、RELU层即可达到较高的性能。后来的网络,如Inception、ResNet、DenseNet等设计的越来越复杂,虽然网络性能提高了,但缺点也很明显:
- 复杂的分支设计(如ResNet和Inception)使其难以应用和自定义,降低了推理的速度并且内存占用率较高
- 一些组件(如Xception和MobileNets中的depthwise卷积、ShuffleNets中的通道shuffle模块)增加了内存访问成本且缺乏适用的硬件;
此外,FLOPS并不能代表运行速度,尽管某些模型FLOPS很低,但其速度并不快(PS:特别是EfficientNets等使用了depthwise卷积的网络)。
复杂分支的设计有利于训练过程,而其缺点又是对推理过程不利的。
因此,作者提出了RepVGG,对训练-推理阶段的网络进行解耦,训练时多分支、推理时plain。其主要有以下优点:
- 模型具有VGG风格的plain(又称前馈)网络结构,没有任何分支,也即:每一层只取其前一层的输出作为输入,而该层输出只作为下一层的输入;
- 模型的主体只用3*3卷积和RELU
为什么使用3x3卷积)在GPU上3x3卷积被封装优化,计算密度对比其他卷积高
在单一模型和多分支模型上,显然是多分支模型在训练上的效果更好并且预测结果更精确,因此作者设计网络时并没有抛弃多分支结构,而是在推理时将其融合成单一路径。
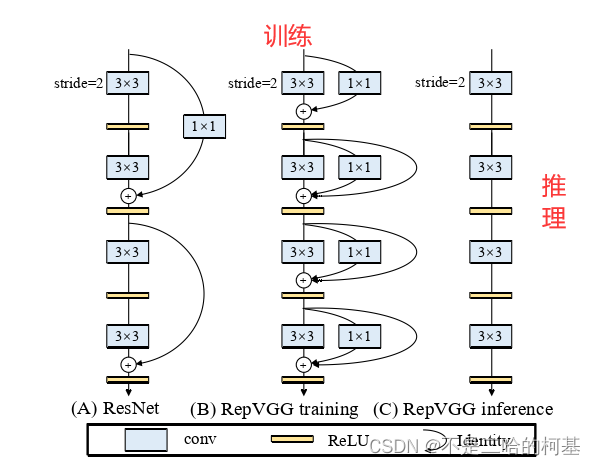
RepVGG的优点
- Fast,使用重参数化后,在推理上速度会有非常大的提升,并且有助于模型部署提高实用性。
- 节省内存,采用多分支模型,在每次计算都需要多份内存分别保存每条分支的结果,所以导致内存消耗大
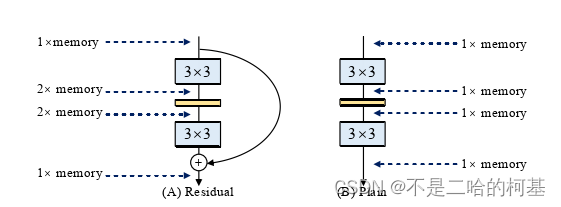
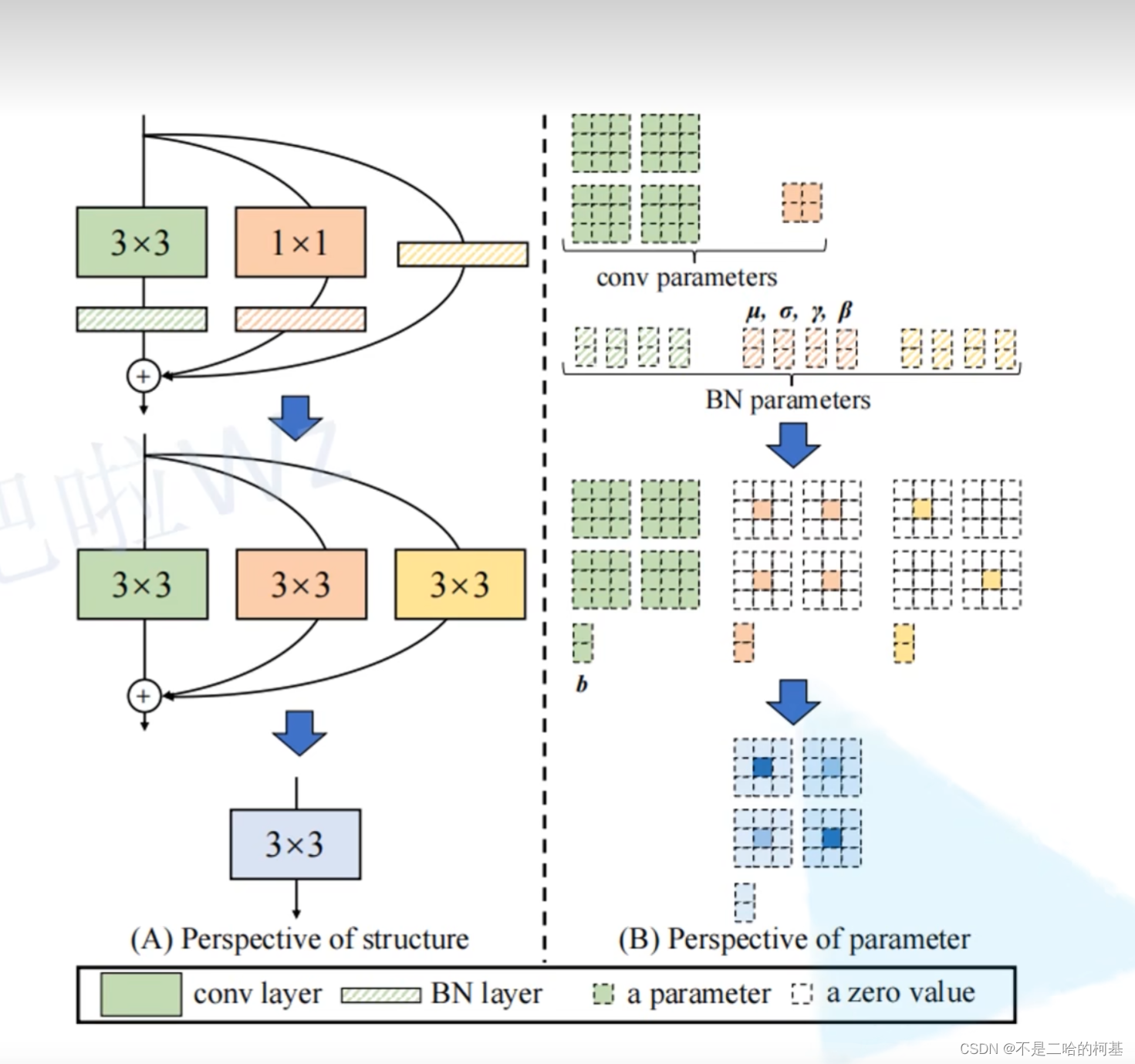
结构重参数化实现过程















 4522
4522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









