





LazyLLM旨在优化大型语言模型(LLM)在处理长文本语境下的推理效率。传统上,LLM的推理过程分为预填充和解码两个阶段,其中预填充阶段负责计算并存储输入提示的所有token的键值(KV)缓存,这一步骤在面对长提示时会显著增加首次生成token的时间消耗,成为效率瓶颈。LazyLLM通过动态剪枝策略解决了这一问题,它仅计算对下一个token预测至关重要的KV,并将剩余token的计算推迟到它们变得相关时。不同于一次性剪枝整个提示的静态方法,LazyLLM允许模型在不同生成步骤中灵活选取不同的上下文子集,即使这些子集在先前步骤中已被剪枝。LazyLLM能够大幅减少首次生成token的时间,同时几乎不牺牲性能。此外,该方法可以无缝集成到现有的基于Transformer的LLM中,无需任何微调,即可提升推理速度。
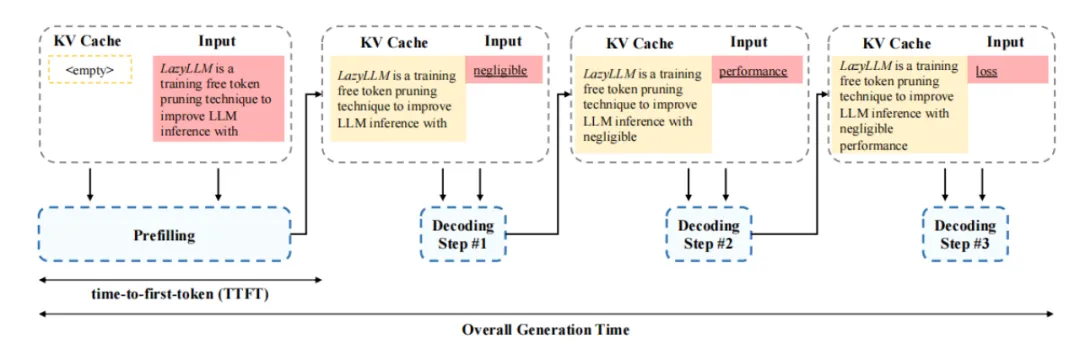
1 动态Token剪枝
推理过程分为两个阶段:预填充(Prefilling)和解码(Decoding)。预填充阶段需要计算所有提示(Prompt)token的键值(KV)缓存,这在长提示的情况下会显著增加“首次生成token时间”(Time-To-First-Token, TTFT),而成为性能瓶颈。动态token剪枝旨在选择性地计算那些对下一个token预测至关重要token的KV缓存。
- 方法: 采用渐进式token剪枝(Progressive Token Pruning),在预填充阶段而且在解码阶段动态选择重要token进行计算,允许模型在不同生成步骤中动态选择上下文的不同子集,战略性地在后期层中剪枝更多token,而在早期层中保留更多token,以平衡效率和性能。
- 实现: 在每个生成步骤中,使用注意力图确定token的重要性。具体来说,使用注意力概率来决定输入token相对于要预测的下一个token的重要性。与静态剪枝不同,动态剪枝在每个步骤优化下一个token的预测,即使某些token在先前的步骤中被剪枝过也可能再次被选中。
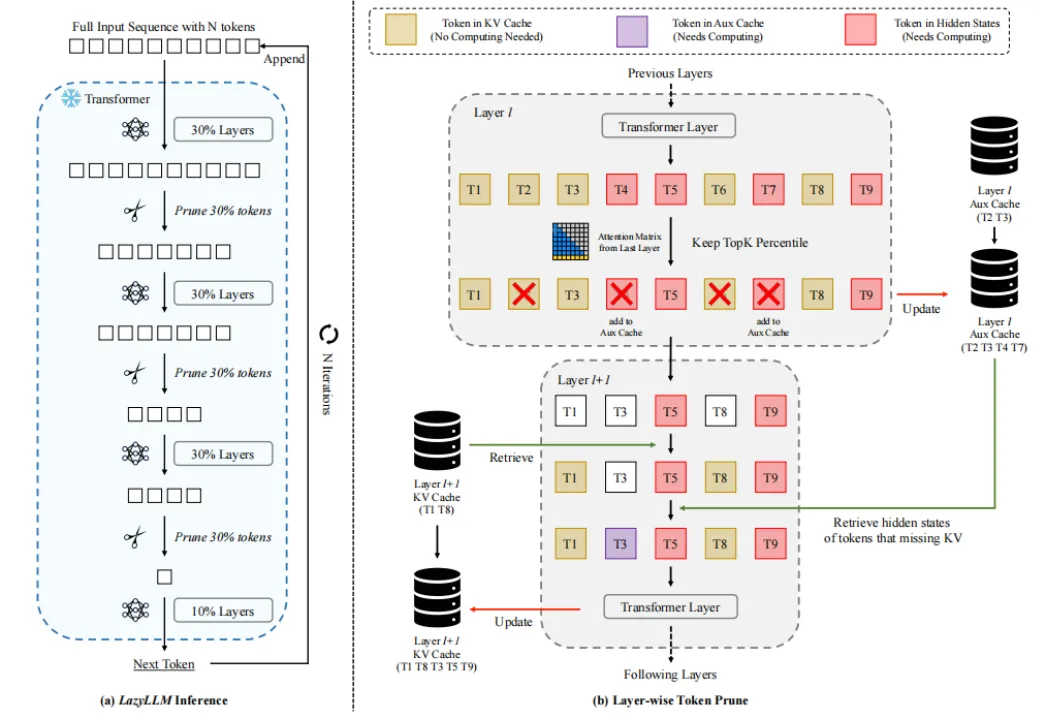
2 渐进式KV增长
传统的LLM推理过程中,预填充阶段需要计算所有输入token的KV缓存,这一步骤会显著增加生成第一个token所需的时间,成为生成过程中的瓶颈。通过分析,发现并非所有的输入token对于预测下一个token都是必要的,许多token可以被剪枝而不影响输出质量。LazyLLM采用动态token剪枝策略,只计算那些对下一个token预测重要的KV值,而“懒惰地”将剩余令牌的计算推迟到它们变得相关时。该方法允许模型在不同的生成步骤中动态地从上下文中选择不同的token子集,即使这些token在之前的步骤中被剪枝。
- 累积token使用率:累积token使用率定义为每个给定步骤的KV缓存大小,展示了在不同生成步骤中使用的token比例及其反向未使用的token比例。
- 层级敏感性:后期Transformer层相对于前期层对token剪枝更为不敏感,这意味着后期层保持更少的token也能有较好的性能。为了平衡速度和准确性,采用渐进式剪枝,早期层保留更多的token,而在后期层逐渐减少。
- 辅助缓存(Aux Cache):由于每个解码步骤依赖于预填充阶段计算的KV缓存来计算注意力,当token在后续层的KV缓存中缺失时,模型无法检索其KV值。引入辅助缓存以存储被剪枝token的隐藏状态,以便在后续迭代中潜在地检索,避免了重复计算同一token,确保每个token在每个Transformer层最多计算一次,并保证LazyLLM的最坏运行时间不会慢于基线。
3 结语
文章提出了LazyLLM技术,这是一种针对长上下文场景下提高大型语言模型(LLM)推理效率的方法,它通过动态选择性计算关键token来加速预填充阶段,同时保持推理性能,无需额外的模型微调。并且,LazyLLM可以无缝集成到现有的基于Transformer的LLM中,提高推理速度。
论文题目:LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
论文链接:https://arxiv.org/abs/2407.14057
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!
















 5557
5557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









