







PIR格式
http://biopython.org/DIST/docs/api/Bio.SeqIO.PirIO-module.html
This format was introduced for the Protein Information Resource (PIR), a project of the National Biomedical Research Foundation (NBRF). The PIR database itself is now part of UniProt.
As with the FASTA format, each record starts with a line beginning with “>” character. There is then a two letter sequence type (P1, F1, DL, DC, RL, RC, or XX), a semi colon, and the identification code. The second like is free text description. The remaining lines contain the sequence itself, terminating in an asterisk. Space separated blocks of ten letters as shown above are typical.
Sequence codes and their meanings:
P1 - Protein (complete)
F1 - Protein (fragment)
D1 - DNA (e.g. EMBOSS seqret output)
DL - DNA (linear)
DC - DNA (circular)
RL - RNA (linear)
RC - RNA (circular)
N3 - tRNA
N1 - Other functional RNA
XX - Unknown
例如
>P1;CRAB_ANAPL
ALPHA CRYSTALLIN B CHAIN (ALPHA(B)-CRYSTALLIN).
MDITIHNPLI RRPLFSWLAP SRIFDQIFGE HLQESELLPA SPSLSPFLMR
SPIFRMPSWL ETGLSEMRLE KDKFSVNLDV KHFSPEELKV KVLGDMVEIH
GKHEERQDEH GFIAREFNRK YRIPADVDPL TITSSLSLDG VLTVSAPRKQ
SDVPERSIPI TREEKPAIAG AQRK*
>P1;CRAB_BOVIN
ALPHA CRYSTALLIN B CHAIN (ALPHA(B)-CRYSTALLIN).
MDIAIHHPWI RRPFFPFHSP SRLFDQFFGE HLLESDLFPA STSLSPFYLR
PPSFLRAPSW IDTGLSEMRL EKDRFSVNLD VKHFSPEELK VKVLGDVIEV
HGKHEERQDE HGFISREFHR KYRIPADVDP LAITSSLSSD GVLTVNGPRK
QASGPERTIP ITREEKPAVT AAPKK*
1. 获取KC750908.1的序列

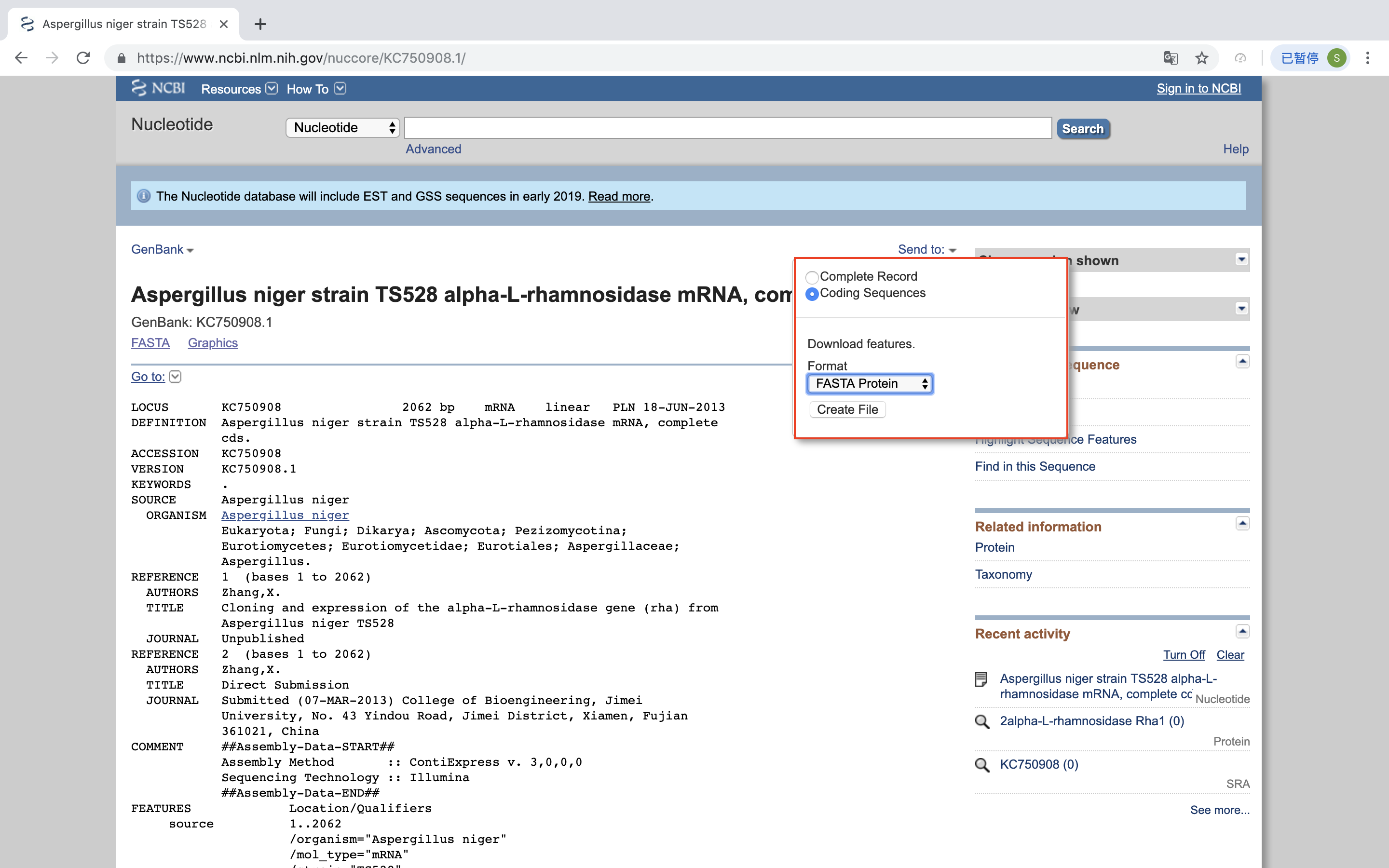
下载的sequence.txt:
>lcl|KC750908.1_prot_AGN92963.1_1 [protein=alpha-L-rhamnosidase] [protein_id=AGN92963.1] [location=1..1968] [gbkey=CDS]
MWSSWLLSALLATEALAVPYEEYILAPSSRDLAPASVRQVNGSVTNAAALTGAGGQATFNGVSSVTYDFG
INVAGIVSVDVASASSESAFIGVTFTESSMWISNEACDATQDAGLDTPLWFAVGQGAGVYSVGKKYTRGA
FRYMTVVSNTTATVSLNSVKINYTASPIQDLRAYTGYFHSSDELLNRIWYAGAYTLQLCSIDPTTGDALV
GLGAITSSETITLPQTDKWWTNYTITNGSSTLTDGAKRDRLVWPGDMSIALESVAVSTEDLYSVRTALES
LYALQKADGQLPYAGKPFYDTVSFTYHLHSLVGAASYYQYTGDRAWLTRYWGQYKKGVQWALSGVDSTGL
ANITASADWLRFGMGAHNIEANAILYYVLNDAISLAQSLNDNAPIRNWTATAARIKTVANELLWDDKNGL
YTDNETTTLHPQDGNSWAVKANLTLSANQSAIISESLAARWGPYGAPAPEAGATVSPFIGGFELQAHYQA
GQPDRALDLLRLQWGFMLDDPRMTNSTFIEGYSTDGSLVYAPYTNRPRVSHAHGWSTGPTSALTIYTAGL
RVTGPAGATWLYKPQPGNLTQVEAGFSTRLGSFASSFSRSGGRYQELSFTTPNGTTGSVELGDVSGQLVS
EGGVKVQLVGGKASGLQGGKWRLNV
该序列为FASTA格式,Modeller输入需要PIR格式,先转格式
在线转格式
https://www.hiv.lanl.gov/content/sequence/FORMAT_CONVERSION/form.html
转出来有点问题,仅供参考
尝试在线转 | 手动转后续都崩掉后,采用python转的方式
先将sequence.txt重命名为KC750908.txt(不知道为什么KC750908.fasta打不开)
转格式python代码:
from modeller import *
e = environ()
a = alignment(e, file="KC750908.txt", alignment_format='FASTA')
a.write(file="KC750908.pir", alignment_format='PIR')
$ mod9.22 fasta2pir.py
执行后
KC750908.pir内容如下:
>P1;lcl|KC750908.1_prot_AGN92963.1_1
sequence:: : : : :::-1.00:-1.00
MWSSWLLSALLATEALAVPYEEYILAPSSRDLAPASVRQVNGSVTNAAALTGAGGQATFNGVSSVTYDFGINVAG
IVSVDVASASSESAFIGVTFTESSMWISNEACDATQDAGLDTPLWFAVGQGAGVYSVGKKYTRGAFRYMTVVSNT
TATVSLNSVKINYTASPIQDLRAYTGYFHSSDELLNRIWYAGAYTLQLCSIDPTTGDALVGLGAITSSETITLPQ
TDKWWTNYTITNGSSTLTDGAKRDRLVWPGDMSIALESVAVSTEDLYSVRTALESLYALQKADGQLPYAGKPFYD
TVSFTYHLHSLVGAASYYQYTGDRAWLTRYWGQYKKGVQWALSGVDSTGLANITASADWLRFGMGAHNIEANAIL
YYVLNDAISLAQSLNDNAPIRNWTATAARIKTVANELLWDDKNGLYTDNETTTLHPQDGNSWAVKANLTLSANQS
AIISESLAARWGPYGAPAPEAGATVSPFIGGFELQAHYQAGQPDRALDLLRLQWGFMLDDPRMTNSTFIEGYSTD
GSLVYAPYTNRPRVSHAHGWSTGPTSALTIYTAGLRVTGPAGATWLYKPQPGNLTQVEAGFSTRLGSFASSFSRS
GGRYQELSFTTPNGTTGSVELGDVSGQLVSEGGVKVQLVGGKASGLQGGKWRLNV*
2. 搜索相似序列并下载PDB文件
搜索相似序列见前文,此处省略
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









