






1 摘要
本综述报告全面概述了将大型语言模型应用于音频信号处理领域的最新进展和挑战。音频处理具有多种信号表示形式和广泛的信号源(从人声到乐器和环境声音),因此面临着与传统自然语言处理不同的挑战。然而,以基于transformer的架构为代表的大型音频模型已在这一领域显示出显著的功效。通过利用海量数据,这些模型已在从自动语音识别和文本到语音到音乐生成等各种音频任务中展现出了卓越的性能。值得注意的是,最近这些基础音频模型(如 SeamlessM4T)已开始显示出作为通用翻译器的能力,可支持多达 100 种语言的多种语音任务,而无需依赖单独的特定任务系统。本文深入分析了有关基础大型音频模型的最新方法、性能基准及其在现实世界场景中的适用性。我们还强调了当前的局限性,并对大型音频模型领域未来潜在的研究方向提出了见解,旨在引发进一步的讨论,从而促进下一代音频处理系统的创新。
2 background
顺序模型在音频处理中的应用最初,深度学习在语音处理领域主要使用了卷积神经网络(CNNs)。但CNNs不能很好地处理语音数据的顺序性,这导致了序列到序列(seq2seq)架构(如循环神经网络RNNs和长短时记忆网络LSTMs)的出现
transformer使用自注意力机制来捕获顺序数据中的时间相关性。与传统的RNNs相比,变换器能更有效地捕获输入序列中远距离的关系,并且允许更大的并行化
2.4 Popular Large Audio Models

SpeechGPT
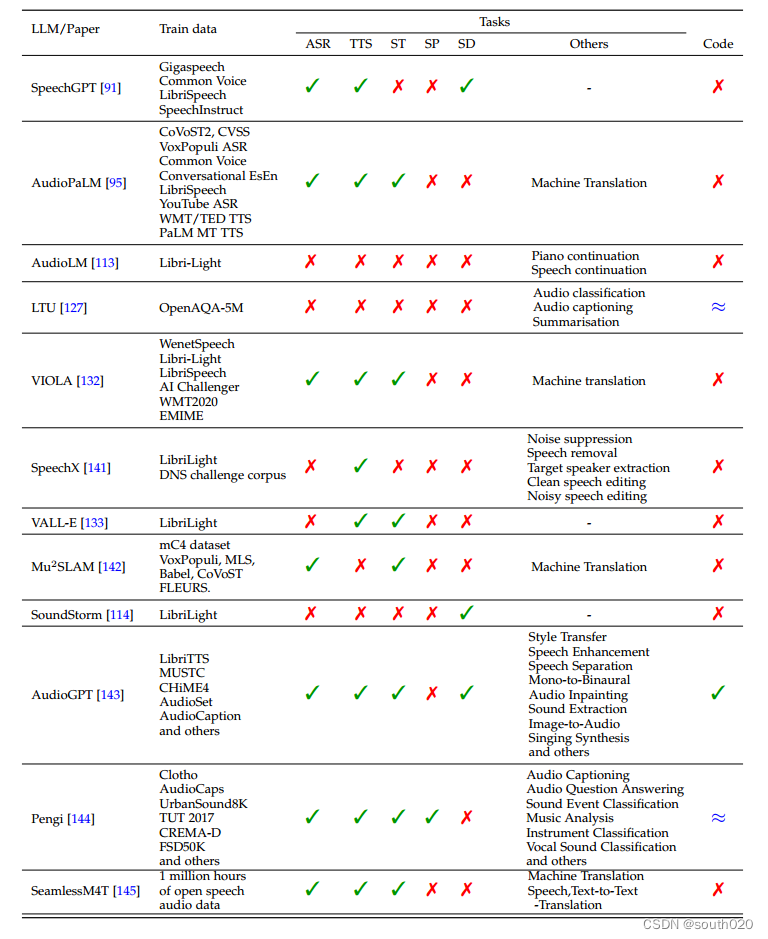
SpeechGPT,这是一种大型语言模型,具有内在的跨模态会话能力,可以生成多模态内容。该模式基于三个重要要素:离散单元提取器、大语言模型和单元声码器。他们利用隐藏单元BERT(HuBERT)[92]作为离散单元提取器,用于将连续语音转换为离散单元,Meta AI LLaMA [93]模型作为LLM,HiFi-GAN作为单元声码器。公开可用的语音数据的低可用性迫使他们构建SpeechInstruct,这是一个语音-文本跨模态指令遵循数据集,由跨模态指令和模态指令链两部分组成。该模型的训练过程分为三个步骤,非成对语音数据的模态适应预训练,跨模态指令微调和模态链指令微调。 他们采用一个未标记的语音语料库来训练LLM在下一个令牌预测任务,使大型语言模型(LLM)有效地处理离散单元的模态。在跨模态指令微调中,他们利用配对数据来对齐语音和文本。 随后,他们应用参数有效的低秩自适应(LoRA)技术[94]来执行微调。 因此,他们发现该模型可以在不同的指令上执行各种任务并具有正确的输出。虽然该模型具有显著的跨模态教学识别和语音对话能力,但它也有一些局限性,如副语言信息,顺序响应生成和上下文长度限制。
AudioPaLM
语音和文本引入了一种称为AudioPaLM的多模式生成模型,该模型能够理解和生成语音该模型的训练包括三个主要阶段:文本和音频的标记化,预先训练的文本解码器的修改,以及将模型的输出转换为音频。他们采用了从原始音频中提取令牌的技术[112113]。在令牌处理之后,令牌被馈送到转换器解码器,转换器解码器随后通过音频解码过程。他们采用了AudioLM[113]中的自回归技术,以及类似于[114]的非自回归方法,将解码令牌转换为音频。他们的研究结果表明,LLM大小提高了ASR/AST性能,并且单个模型可以有效地跨多个任务进行训练。
AudioLM
AudioLM框架,旨在促进高质量的音频合成,同时优先考虑在延长的时间跨度内保持长期一致性、连贯性和一致性。该框架由三个整体组件组成:标记器模型、仅解码器转换器和去标记器模型。
根据w2v BERT嵌入的kmeans量化器和解码转换器,所有这些都是在包含60000小时语音数据的广泛Libri Light[117]英语数据集上训练的,作者组装了这些组件。这种融合融合了对抗性神经音频压缩、自监督表示学习和语言建模技术。他们展示了SoundStream中的声学标记和从语音数据集上预训练的w2v BERT模型中提取的语义标记之间的比较,以表明这两种类型的标记相互补充
AudioGen
Meta最近推出了AudioCraft,这是一个广泛的框架,旨在促进各种生成音频任务,包括音乐生成、音效创建和使用原始音频信号的训练后压缩。该综合框架由三个重要组成部分组成:MusicGen[118]、AudioGen和EnCodec。MusicGen和AudioGen都包含了独立的自回归语言模型(LM),专门用于以令牌形式的离散音频表示操作。相比之下,EnCodec是建立在神经网络之上的。
AudioLDM and AudioLDM 2
AudioLDM 是一个文本到音频的生成框架,其编码器建立在对比语言音频预训练(CLAP)模型和用于声音生成的潜在扩散模型(LDM)之上,音频嵌入作为输入,文本嵌入作为条件。CLAP 模型通过 LAION-Audio-630K、AudioSet、AudioCaps 和 Clotho 等数据集进行预训练。有了 CLAP 编码器,LDM 的训练不再需要音频-文本对,这与之前的 AudioGen [118] 和 DiffSound [125] 等方法大不相同。因此,大量的音频片段(没有成对的文本)都可以用来训练 LDM 模型,这使得生成的模型与 AudioGen 和 DiffSound 相比,能够生成更多样化的声音,质量可能更好。此外,与 AudioGen 和 DiffSound 相比,由于在潜空间进行操作,AudioLDM 的训练效率要高得多,在 AudioCaps 数据集上进行训练只需要一个 GPU。此外,AudioLDM 模型还能以零镜头方式执行其他一些与音频相关的任务,如文本引导的超分辨率、内绘制和风格转移。在 AudioLDM 成功的基础上,作者创建了一个更先进的模型,称为 AudioLDM 2 [126],旨在开发一种通用的音频表示方法,称为 "音频语言"(LOA),适用于语音、音乐和一般声音效果。通过这种方法,可以学习到一个单一的基础模型
LTU
LTU(Listen, Think, and Understand)的音频模型,该模型设计用于执行基于 OpenAQA5M 数据集的音频分类和字幕任务,OpenAQA5M 数据集包含 560 万个不同的音频样本。LTU 的训练包括通过合并包含音频、问题和答案的八个数据集,创建一个新的数据集 OpenAQA-5M。LTU 模型的架构借鉴了多个组件,包括音频谱图转换器(AST)[128] 作为音频编码器、LLaMA[93] 作为使用 Vicuna[129] 指令增强的大型语言模型(LLM)、低秩适配器[94] 和特定的生成设置。为了使嵌入维度与 LLaMA 保持一致,在 CAV-MAE [130] 的基础上使用了预先训练好的音频谱图变换器,并在 AudioSet-2M [119] 上对音频编码进行了微调。在训练过程中,作者保持 LLaMA 不变,以尽量减少灾难性遗忘 [131]。他们只专注于训练 AST 音频编码器、音频投影层和 LoRA 适配器。LLaMA 在自然语言和编程语言数据集上进行了自监督预训练,而 Vicuna 则使用 GPT 模型生成的指令进行了微调。音频投影层的任意初始化使得该组件的训练与封闭式分类和声学特征描述任务相结合,同时保持 AST 和 LoRA 适配器不变。














 2875
2875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









