






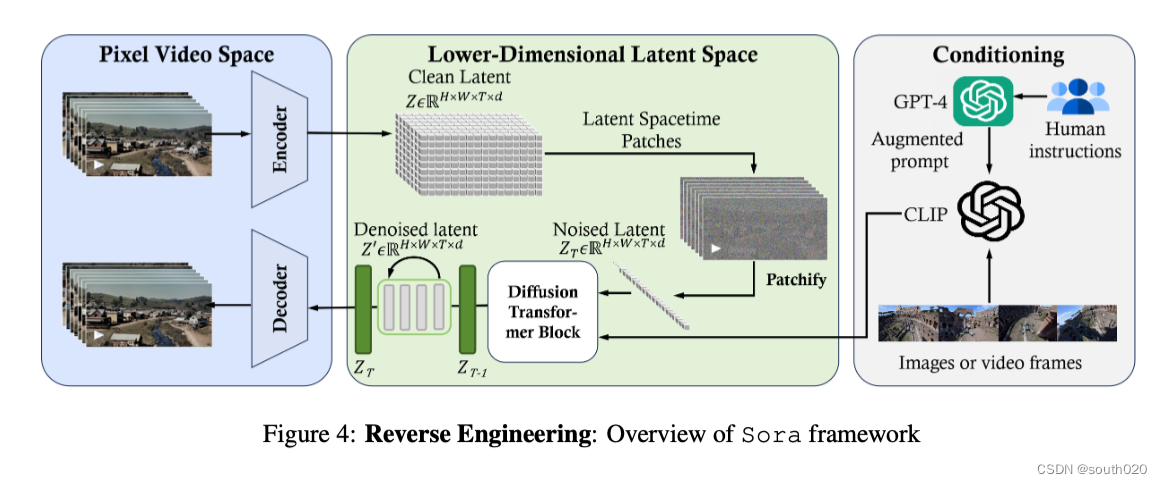
sora的核心框架如上图所示,一共有3个部分
(1)时空压缩将原始视频压缩到latent space
(2)ViT处理标记化的潜在表示并输出去噪的潜在表示。
(3)CLIP-like调节机制接收llm增强的用户指令和潜在的视觉扣提示,以指导扩散模型生成样式或主题化视频。经过多次去噪步骤,得到生成视频的latent表示,然后用相应的解码器映射回像素空间。
持续更新中。。。。。
核心技术Scalable Diffusion Models with Transformers
扩散模型大部分是采用UNet架构来进行建模,UNet可以实现输出和输入一样维度,所以天然适合扩散模型。扩散模型使用的UNet除了包含基于残差的卷积模块,同时也往往采用self-attention。自从ViT之后,transformer架构已经大量应用在图像任务上,随着扩散模型的流行,也已经有工作尝试采用transformer架构来对扩散模型建模,核心技术基于DiT:Scalable Diffusion Models with Transformers,它是完全基于transformer架构的扩散模型,这个工作不仅将transformer成功应用在扩散模型,还探究了transformer架构在扩散模型上的scalability能力,其中最大的模型DiT-XL/2在ImageNet 256x256的类别条件生成上达到了SOTA(FID为2.27)。
DiT并没有采用常规的pixel diffusion,而是采用了latent diffusion架构,这也是Stable Diffusion所采用的架构。latent diffusion采用一个autoencoder来将图像压缩为低维度的latent,扩散模型用来生成latent,然后再采用autoencoder来重建出图像。DiT采用的autoencoder是SD所使用的KL-f8,对于256x256x3的图像,其压缩得到的latent大小为32x32x4,这就降低了扩散模型的计算量(后面我们会看到这将减少transformer的token数量)。另外,这里扩散过程的nosie scheduler采用简单的linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02),这个和SD是不同的。 其次,DiT所使用的扩散模型沿用了OpenAI的Improved DDPM,相比原始DDPM一个重要的变化是不再采用固定的方差,而是采用网络来预测方差。在DDPM中,生成过程的分布采用一个参数化的高斯分布来建模:
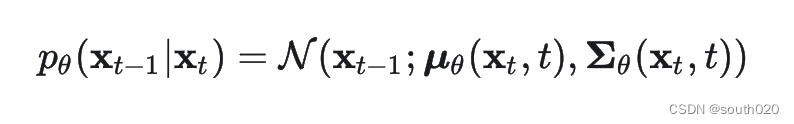
不过DDPM采用固定的方差,即采用固定值,在生成过程中设置为或者,而和其实是一个上下限。而Improved DDPM采用网络来预测方差:
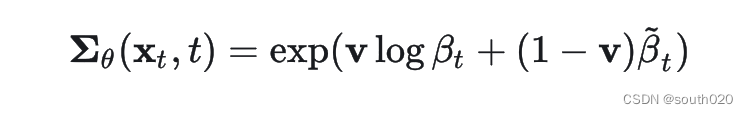
这里网络并不是直接预测方差,而是预测一个系数v,并通过在和之间插值来计算最终的方差。DDPM的通过来进行优化,但是这个损失函数并不依赖,为了优化,Improved DDPM采用了一个组合损失函数:
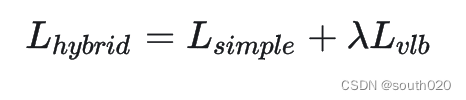
DiT所设计的transformer架构,这才是这个工作的核心。其实DiT基本沿用了ViT的设计,如下图所示,首先采用一个patch embedding来将输入进行patch化,即得到一系列的tokens。其中patch size属于一个超参数,它直接决定了tokens的数量,这会影响模型的计算量。DiT的patch size共选择了三种设置:。注意token化之后,这里还要加上positional embeddings,这里采用非学习的sin-cosine位置编码。
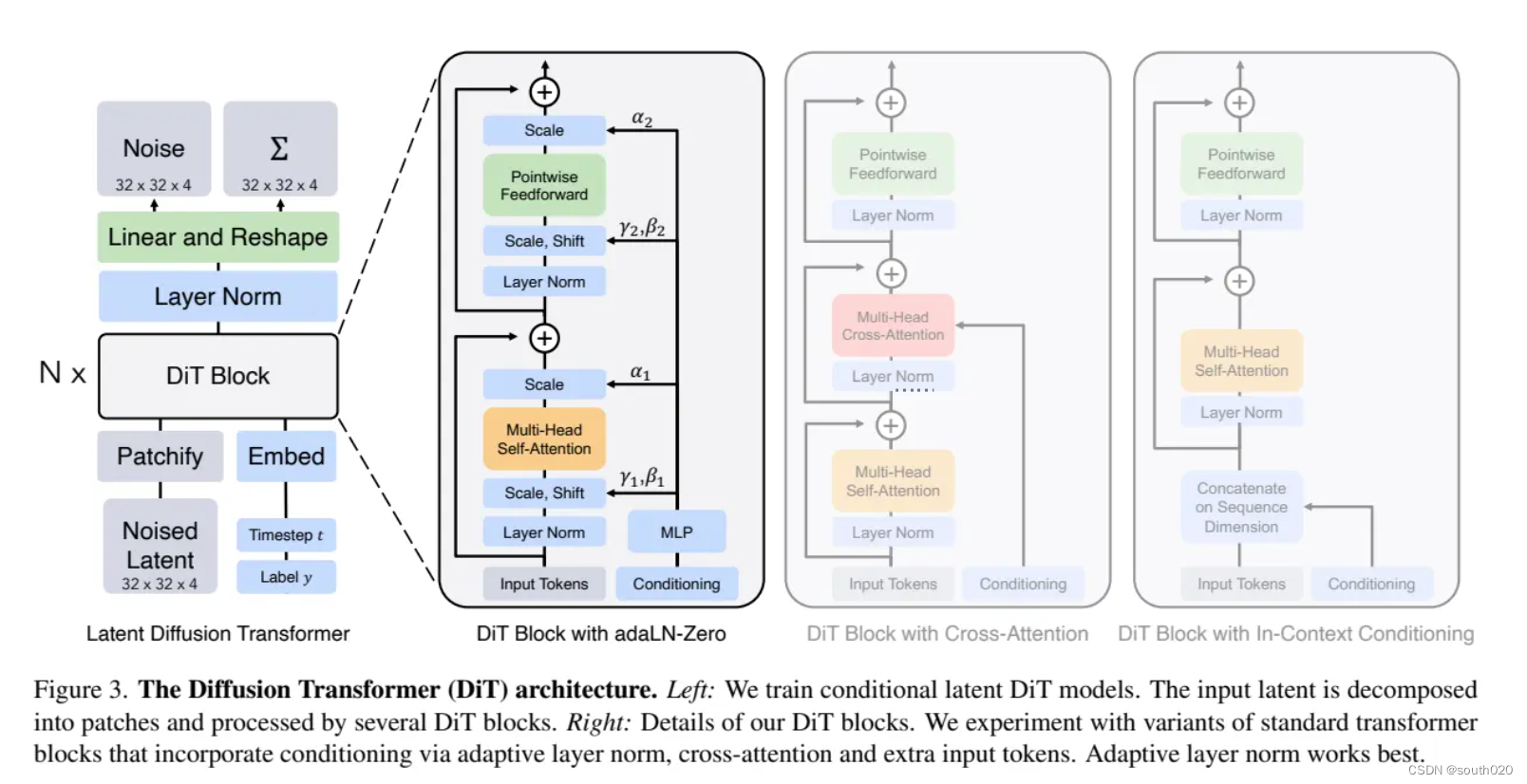
将输入token化之后,就可以像ViT那样接transformer blocks了。但是对于扩散模型来说,往往还需要在网络中嵌入额外的条件信息,这里的条件包括timesteps以及类别标签(如果是文生图就是文本,但是DiT这里并没有涉及)。要说明的一点是,无论是timesteps还是类别标签,都可以采用一个embedding来进行编码。
















 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









