







导包
import os
import six.moves.urllib.request as request
import tensorflow as tf
from matplotlib import pyplot as plt
# Check that we have correct TensorFlow version installed
tf_version = tf.__version__
print("TensorFlow version: {}".format(tf_version))
TensorFlow version: 2.8.0
导入数据
获取数据文件目录
# 获取当前工作目录
PATH = os.getcwd()
# Fetch and store Training and Test dataset files
PATH_DATASET = PATH + os.sep + "dataset"
FILE_TRAIN = PATH_DATASET + os.sep + "iris_training.csv"
FILE_TEST = PATH_DATASET + os.sep + "iris_test.csv"
URL_TRAIN = "https://download.tensorflow.org/data/iris_training.csv"
URL_TEST = "https://download.tensorflow.org/data/iris_test.csv"
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
csv文件转为dataset
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=12, # 为了示例更容易展示,手动设置较小的值
column_names=column_names,
label_name=label_name,
na_value="?",
num_epochs=1,
ignore_errors=True)
return dataset
train_file_path = FILE_TRAIN
test_file_path = FILE_TEST
train_dataset = get_dataset(train_file_path)
test_dataset = get_dataset(test_file_path)
list(train_dataset.take(1).as_numpy_iterator())
# for i in raw_train_data.take(1):
# print(i)
[(OrderedDict([('sepal_length',
array([6.3, 6.7, 6.3, 6.4, 5.2, 5.6, 7.7, 5. , 6.9, 5.6, 4.7, 7.2],
dtype=float32)),
('sepal_width',
array([3.3, 3. , 3.4, 3.1, 2.7, 2.5, 3. , 3. , 3.1, 2.7, 3.2, 3. ],
dtype=float32)),
('petal_length',
array([4.7, 5.2, 5.6, 5.5, 3.9, 3.9, 6.1, 1.6, 4.9, 4.2, 1.6, 5.8],
dtype=float32)),
('petal_width',
array([1.6, 2.3, 2.4, 1.8, 1.4, 1.1, 2.3, 0.2, 1.5, 1.3, 0.2, 1.6],
dtype=float32))]),
array([1, 2, 2, 2, 1, 1, 2, 0, 1, 1, 0, 2])),
特征,标签分割
features, labels = next(iter(train_dataset)) # 第一个批次
print("EXAMPLES: \n", examples, "\n")
print("LABELS: \n", labels)
EXAMPLES:
OrderedDict([('120', <tf.Tensor: shape=(12,), dtype=float32, numpy=
array([6.1, 6.2, 5.8, 5.6, 5.8, 6.4, 6.1, 5.7, 5.7, 4.6, 5.2, 6.3],
dtype=float32)>), ('4', <tf.Tensor: shape=(12,), dtype=float32, numpy=
array([2.8, 2.8, 4. , 2.7, 2.7, 2.8, 2.9, 3.8, 2.8, 3.1, 2.7, 2.3],
dtype=float32)>), ('setosa', <tf.Tensor: shape=(12,), dtype=float32, numpy=
array([4.7, 4.8, 1.2, 4.2, 4.1, 5.6, 4.7, 1.7, 4.5, 1.5, 3.9, 4.4],
dtype=float32)>), ('versicolor', <tf.Tensor: shape=(12,), dtype=float32, numpy=
array([1.2, 1.8, 0.2, 1.3, 1. , 2.1, 1.4, 0.3, 1.3, 0.2, 1.4, 1.3],
dtype=float32)>)])
LABELS:
tf.Tensor([2 0 0 1 0 2 1 0 0 1 1 0], shape=(12,), dtype=int32)
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()

dataset打包成二维数组
def pack_features_vector(features, labels):
features = tf.stack(list(features.values()), axis=1)
return features, labels
train_dataset = train_dataset.map(pack_features_vector)
train_dataset
list(train_dataset.take(1).as_numpy_iterator())
<MapDataset element_spec=(TensorSpec(shape=(None, 4), dtype=tf.float32, name=None), TensorSpec(shape=(None,), dtype=tf.int32, name=None))>
features, labels = next(iter(train_dataset))
print(features)
print(labels)
tf.Tensor(
[[6.5 3. 5.8 2.2]
[4.6 3.2 1.4 0.2]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[4.8 3.1 1.6 0.2]
[5.8 2.7 4.1 1. ]
[5. 3. 1.6 0.2]
[5.7 3. 4.2 1.2]
[5.8 2.7 5.1 1.9]
[6. 2.9 4.5 1.5]
[4.8 3.4 1.6 0.2]
[5.5 3.5 1.3 0.2]], shape=(12, 4), dtype=float32)
tf.Tensor([2 0 0 1 0 2 1 0 0 1 1 0], shape=(12,), dtype=int32)
建立模型----三层感知机模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.34744287, 0.23620045, 0.41635668],
[0.36335322, 0.21712378, 0.419523 ],
[0.30681884, 0.23011816, 0.46306297],
[0.46609837, 0.13207382, 0.40182784],
[0.28325418, 0.28049824, 0.43624762]], dtype=float32)>
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [2 2 2 0 2 2 2 2 2 0 2 2]
Labels: [1 1 2 0 2 1 2 2 1 0 1 1]
模型训练
损失函数和梯度函数
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
Loss test: 1.1089719533920288
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
模型过程
## Note: Rerunning this cell uses the same model variables
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
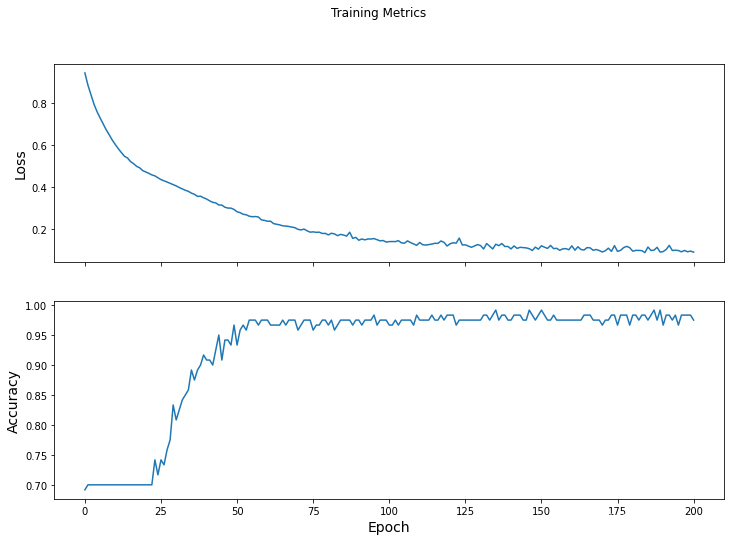
Epoch 000: Loss: 0.946, Accuracy: 69.167%
Epoch 050: Loss: 0.283, Accuracy: 93.333%
Epoch 100: Loss: 0.141, Accuracy: 96.667%
Epoch 150: Loss: 0.121, Accuracy: 99.167%
Epoch 200: Loss: 0.091, Accuracy: 97.500%
Acc-epoch曲线
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()

验证集评估模型
test_dataset = test_dataset.map(pack_features_vector)
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
查看下预测值和标签
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(6, 2), dtype=int32, numpy=
array([[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1],
[1, 1]])>
测试
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (99.3%)
Example 1 prediction: Iris versicolor (97.9%)
Example 2 prediction: Iris virginica (82.2%)
















 3634
3634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











