







目录
概要
Torchserve 实现 bge-large-zh 模型工程化落地
背景
自从算法工程师这一职业诞生以来,算法技术经历了快速的发展。从最初的机器学习阶段,使用诸如 Scikit-Learn 和 XGBoost 等框架,逐步演变到深度学习时代,广泛采用 TensorFlow、PyTorch 和 Keras 等深度学习框架。同时,简单的自然语言处理(NLP)技术也逐渐发展起来,用于语义分析等应用,到现在NLP技术和人工智能的强力发展下,大模型百家争鸣,如雨后春笋,在这种百花齐放下也伴随着一些问题的出现,那就是大模型服务的应用工程话问题,到底是有谁来做,或者有没有什么统一的标准来做,即让算法同学可以将工作重心放在模型训练和参数调整上面,同时后端同学也不需要将投入大量的精力去研究大模型应用的落地工程化。
算法工程师的职责:
1. 模型训练:使用不同的算法和框架对数据进行训练,生成高质量的预测模型。
2. 模型调参:通过调整模型参数,优化模型性能,提升预测准确度。
算法交付产物:
- 模型使用文档,包括输入输出格式、参数设置和注意事项等。
- 训练完成的模型,提供已经训练好并优化过的模型文件,方便后续的部署和应用。
- 模型调用示例代码:一个完整的示例代码模块(如
main.py),其中包括以下内容:
- 导入必要的库和模块。
- 加载训练好的模型。
- 获取输入数据。
- 进行推理预测。
- 输出预测结果。
总结来说,算法同学只负责模型的训练,并不care怎么在应用中使用,以及如何将性能最大化也不并关心,所以后端同学的态度更是算法服务能用就行,更是不会care性能和使用方式
业界痛点
算法工程师主要专注于模型训练和参数调优。长期以来,业界形成了一个不成文的规定,即算法工程师负责交付模型,而后端工程师负责模型的工程化落地。这种分工类似于“开发工程师”和“运维工程师”之间的关系与矛盾。开发与运维通过“DevOps”平台及“运维开发工程师”解决了这一痛点,这得益于DevOps平台的发展和完善。随着Kubernetes(k8s)等工具的问世,各种解决方案也相继出现,行业内的这些问题得以解决。
算法和后端遇到的痛点:
- 算法服务的工程化强依赖后端:算法模型的部署和维护严重依赖于后端工程师的支持。
- 后端对算法服务的态度消极:后端工程师对算法服务的态度通常是“能跑就行”,缺乏深入优化的意愿。
- 算法服务只关注准确率,不关心性能:算法工程师往往只关心模型的准确率,对模型的运行性能和效率关注较少。
- 后端认为性能问题是算法服务的责任:后端工程师通常认为服务慢、并发低是由于算法服务的问题,而他们自己的服务速度慢、单进程、单线程、显卡显存和算力等问题,他们不了解也无力解决。
- 职责分明导致问题长期存在:长期以来,算法与后端的职责分明导致了这些问题的出现,类似于开发与运维的矛盾。
通过明确这些痛点,可以看出,解决算法和后端的协作问题需要借鉴DevOps的成功经验,采用类似的平台和工具,促进两者的协同工作,提高整体效率和服务质量。
解决方案
在上述痛点的背景压力下,各大厂商开始探索新的解决方案,涌现出许多优秀的工具和平台。例如,PyTorch 提供了 TorchServe,PaddlePaddle 提供了 PaddleServe。此外,业界主流并广泛采用的解决方案是 LangChain,它被视为算法服务工程化领域的“k8s”。LangChain 站在更高层面和维度,提供了全面统一的算法服务工程化解决方案。
尽管 LangChain 功能强大,但其资源需求和成本较高,学习曲线也较陡峭,因此更适合规模较大的公司。对于中小型公司,PaddleServe 和 TorchServe 则是更好的选择,它们能够以更低的成本和较少的资源需求,提供高效的算法服务部署和管理方案。
通过这些解决方案,各公司可以更有效地解决算法与后端之间的协作问题,实现算法服务的高效工程化落地。
TorchServe VS 传统方式(Django)
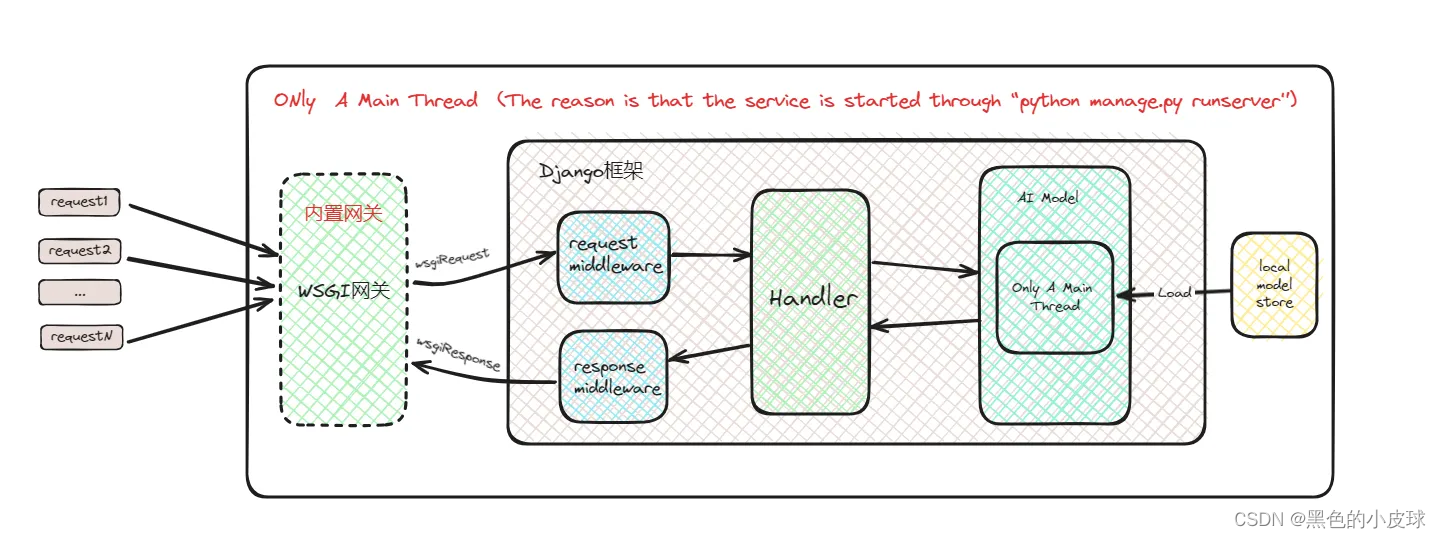
传统方式(Django)
说明:由于Django服务启动是通过“python mange.py runserver”启动,使用的是一个Django内置的用于开发测试的WSGI服务网关,因此它是单进程单线程的。性能极差,不足以满足生产使用,GPU资源完全没有利用起来
TorchServe(新方案)
TorchServe 框架搭载了业界公认的 Web 标准——Java,并使用 Netty 库进行 IO 操作,结合多路复用和事件驱动,是一个业界标准的解决方案。其卓越之处主要体现在以下两点:
- 卓越一:线程组分配和批量处理:对于每个模型,Java 会为其分配一个单独的线程组,并引入批量处理特性,以高效利用 GPU 性能。这种设计结合了天时地利,堪称大成之作。
- 卓越二:Python 模型交互与进程池:模型交互模块通过 Python 实现,提供了可配置的 worker 数量。设计者使用了进程池方案,服务启动时会根据配置的
default_work
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5587
5587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









