







 本文通过分析上海市餐饮数据,包括不同菜系的评分、消费、性价比等,探究了餐饮品类竞争力、地区竞争力以及甜品店在各行政区的分布情况。使用Pyecharts进行了数据可视化和统计分析。
本文通过分析上海市餐饮数据,包括不同菜系的评分、消费、性价比等,探究了餐饮品类竞争力、地区竞争力以及甜品店在各行政区的分布情况。使用Pyecharts进行了数据可视化和统计分析。
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
1、项目背景与目标
针对上海市餐饮类,不同菜系在各个区的,口味,服务,环境等的评分以及人均消费的数据分析。从而得出一些餐饮品类的竞争分析,地区竞争力分析,以及甜品店在上海各行政区的分布情况。
2、导入模块
安装BI工具的Echars
#!pip install pyecharts
#!pip install echarts-china-cities-pypkg
导包代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
plt.rcParams['font.sans-serif'] = ['SimHei'] #设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
pd.set_option('display.float_format',lambda x : '%.2f' % x)#pandas禁用科学计数法
#忽略警告
import warnings
warnings.filterwarnings('ignore')
from pyecharts.charts import Bar,Grid,Scatter,Pie,Geo
from pyecharts import options as opts
3、导入数据
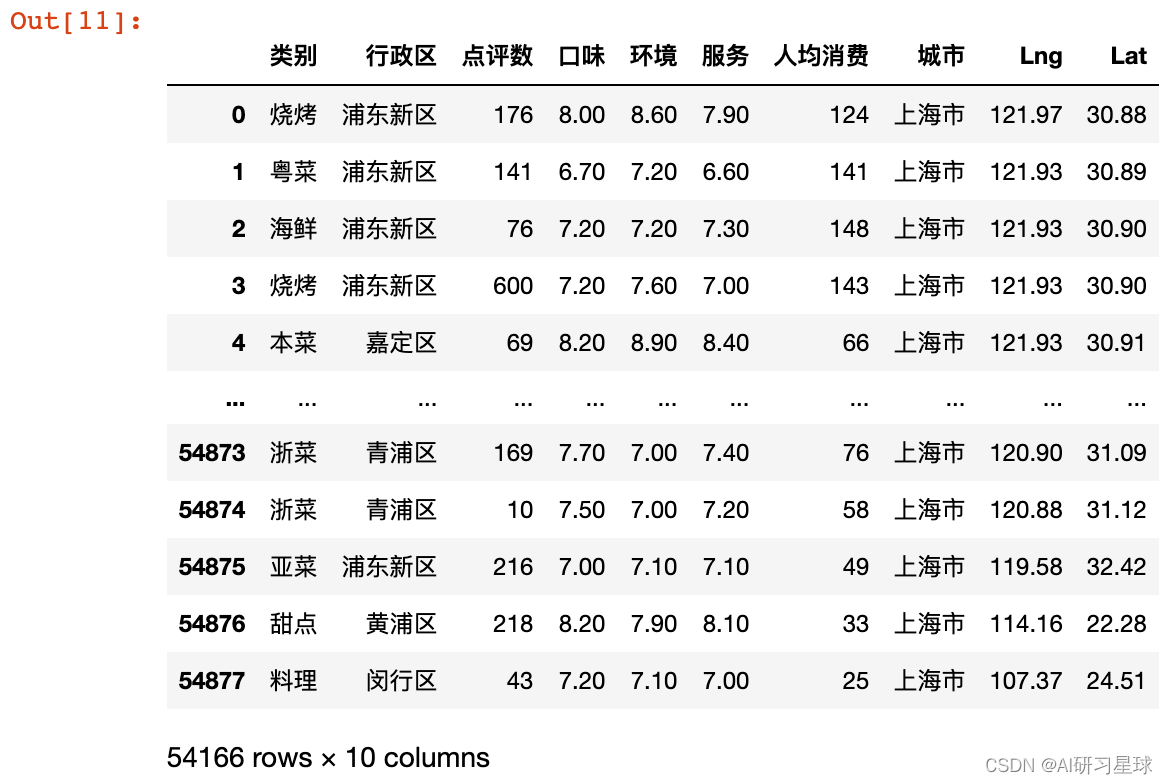
data = pd.read_csv("上海餐饮数据.csv")
data.head()
4、数据处理
# 去除最后两行无用的列
data = data.iloc[:,:-2]
data
4.1异常值和空值处理
# 检查各字段是否存在是否存在空值
data.isnull().sum()
#清除空值
df = data.dropna()
# 检查各字段是否存在是否存在0值并清除
df.drop(df[(df ==0).T.any()].index,inplace=True)
df = df.reset_index(drop=True)
df.head()
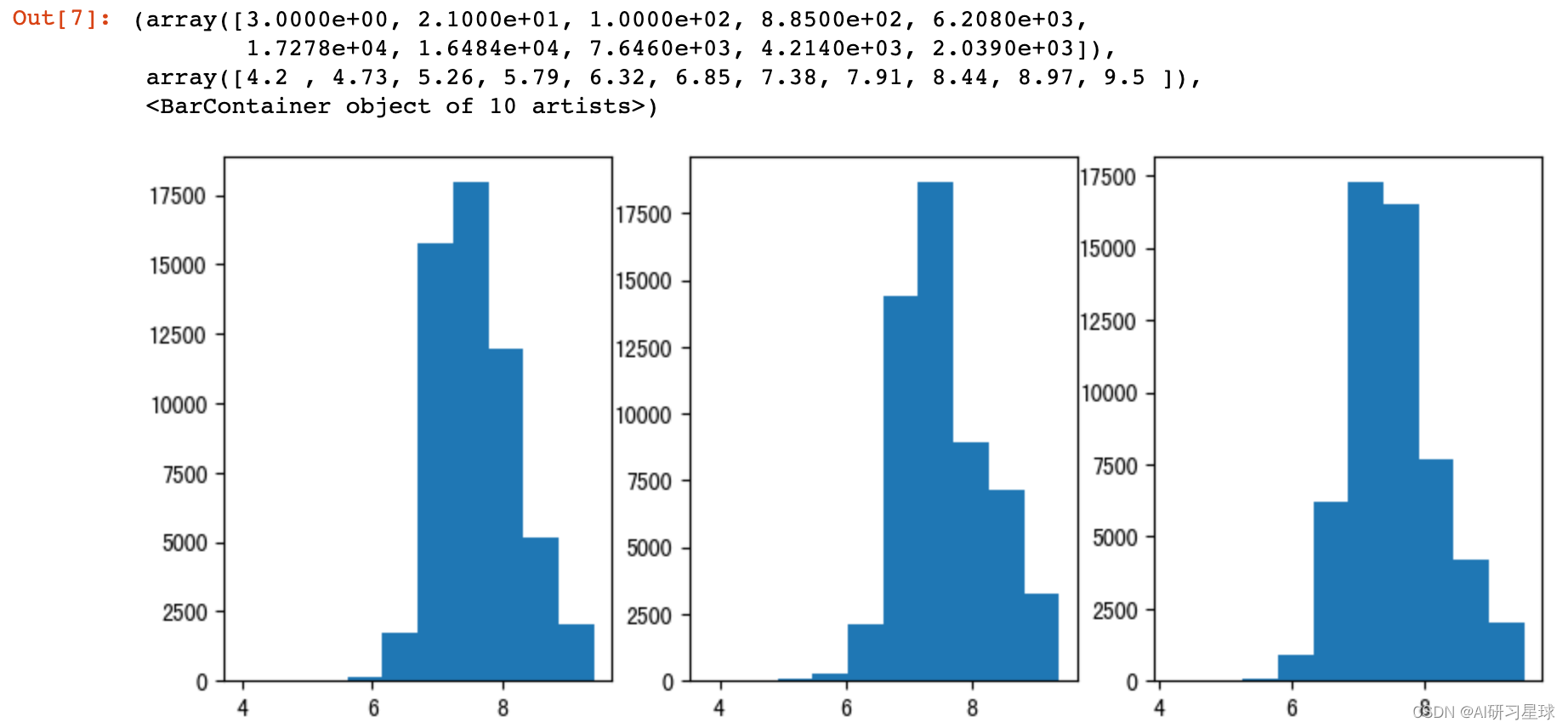
# 查看评分字段数据分布情况
fig,axes = plt.subplots(1,3,figsize = (10,4))
ax1 = axes[0]
ax1.hist(df["口味"])
ax2 = axes[1]
ax2.hist(df["环境"])
ax3 = axes[2]
ax3.hist(df["服务"])
df["人均消费"].plot.box()
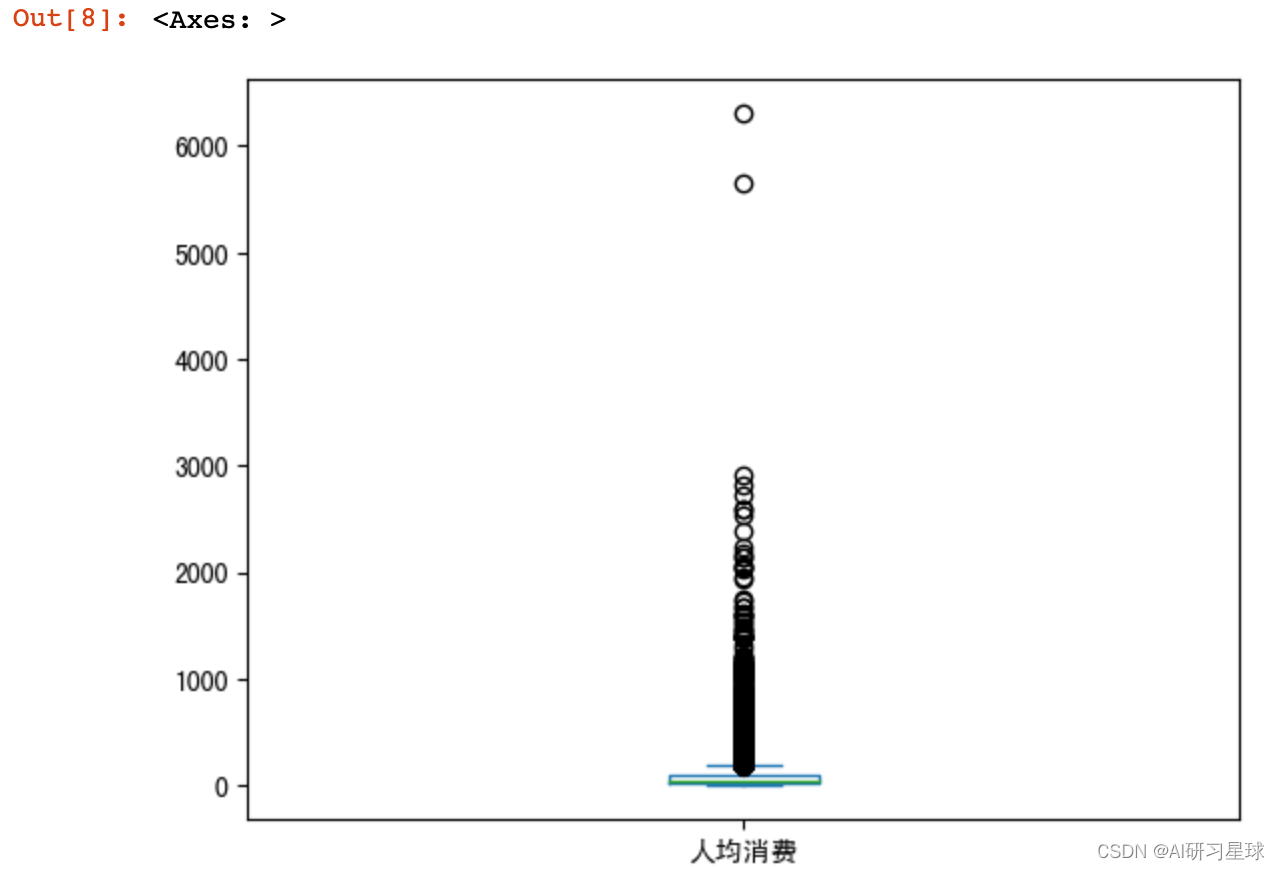
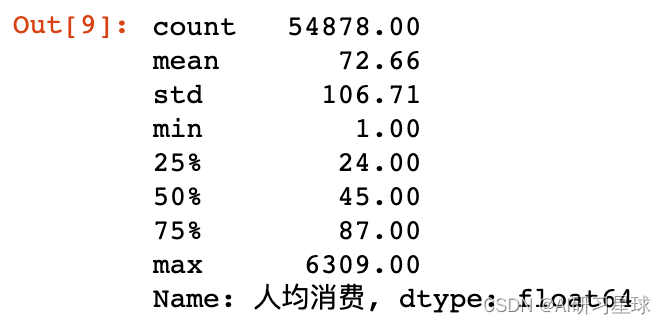
df["人均消费"].describe()
# 对人均消费过高的记录进行剔除
def f(data,col):
q1 = data[col].quantile(q = 0.25)
q3 = data[col].quantile(q = 0.75)
iqr = q3 - q1
t1 = q1 - 5*iqr
t2 = q3 + 5*iqr
return data[(data[col]>t1)&(data[col]<t2)]
df = f(df,"人均消费")
df
5、餐饮品类竞争力分析
#计算性价比
df['性价比'] = (df['口味'] + df['环境'] + df['服务'])/ df['人均消费']
df.head(3)

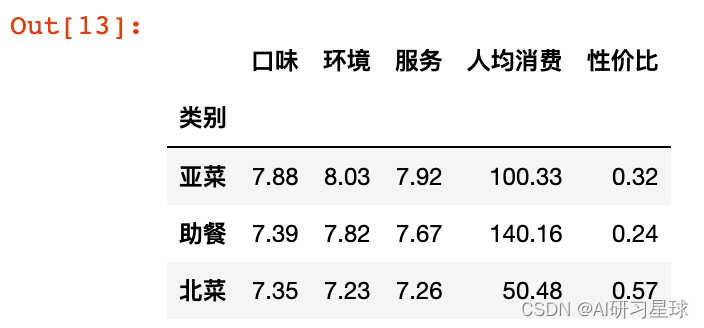
# 分类别计算
df_groupby = df.groupby('类别')['口味','环境','服务','人均消费','性价比'].mean()
df_groupby.head(3)
# 计算餐饮行业评价综合评分
df_groupby["综合评分"] = (df_groupby['口味'] + df_groupby['环境']+ df_groupby['服务'])/3
bar1 = (
Bar()
.add_xaxis(df_groupby["综合评分"].index.tolist())
.add_yaxis("综合评分",df_groupby["综合评分"].values.round(2).tolist())
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-90)),
legend_opts=opts.LegendOpts(pos_left="40%")
).set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
bar2 = (
Bar()
.add_xaxis(df_groupby["人均消费"].index.tolist())
.add_yaxis("人均消费",df_groupby["人均消费"].values.round(2).tolist())
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-90)),
legend_opts=opts.LegendOpts(pos_left="50%")
).set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
bar3 = (
Bar()
.add_xaxis(df_groupby["性价比"].index.tolist())
.add_yaxis("性价比",df_groupby["性价比"].values.round(2).tolist())
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-90)),
legend_opts=opts.LegendOpts(pos_left="60%")
).set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
grid = (
Grid()
.add(bar1, grid_opts=opts.GridOpts(pos_bottom="70%",))
.add(bar2, grid_opts=opts.GridOpts(pos_top='40%',pos_bottom="40%"))
.add(bar3, grid_opts=opts.GridOpts(pos_top='70%'))
)
grid.render_notebook()

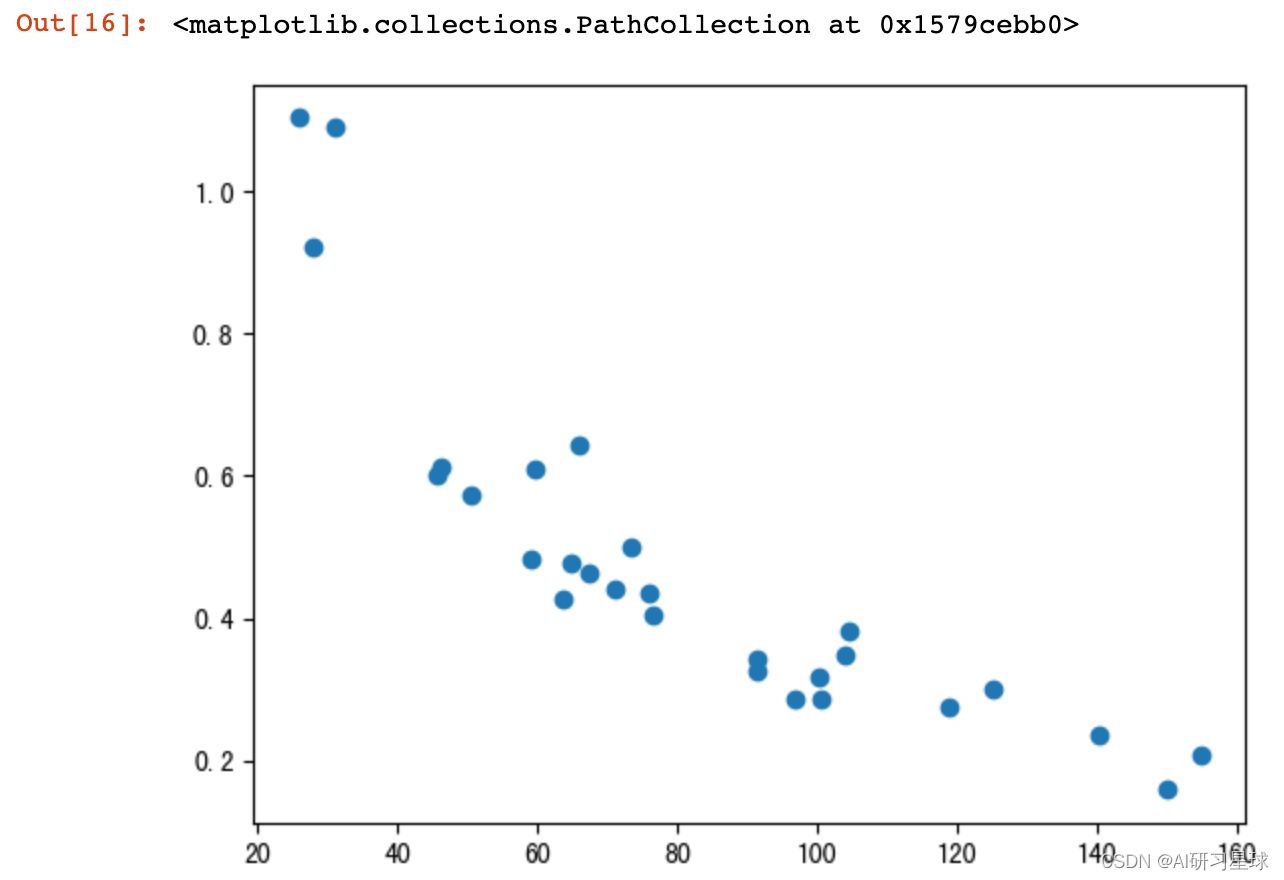
# 人均消费与性价比的得分之间的关系,x轴为“人均消费”,y轴为“性价比得分”
plt.scatter(df_groupby["人均消费"],df_groupby["性价比"])
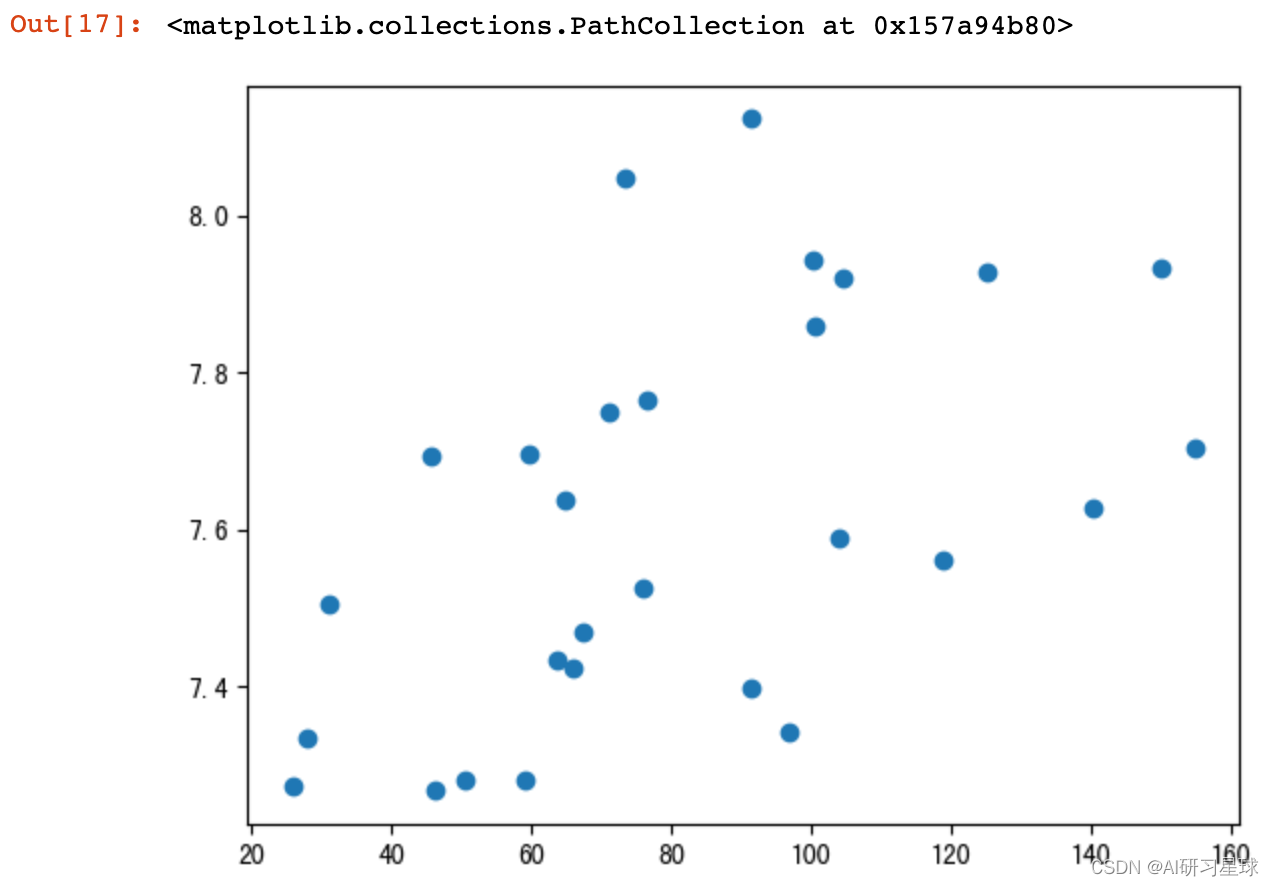
# 人均消费与行业得分之间的关系,x轴为“人均消费”,y轴为“综合评分”
plt.scatter(df_groupby["人均消费"],df_groupby["综合评分"])
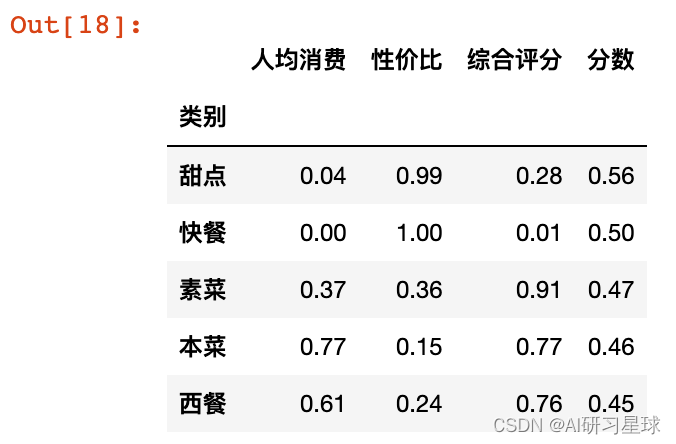
# 按照 口味:人均消费:性价比 = 2:3:5 的比例去计算
df_groupby = df_groupby[["人均消费","性价比","综合评分"]]
df_groupby = (df_groupby-df_groupby.min())/(df_groupby.max()-df_groupby.min()) # 将数据进行标转化处理
df_groupby['分数'] = 0.2*df_groupby['综合评分'] + 0.3*df_groupby['人均消费']+0.5*df_groupby['性价比']
df_groupby.sort_values('分数',ascending=False)[:5]
6、地区竞争力分析
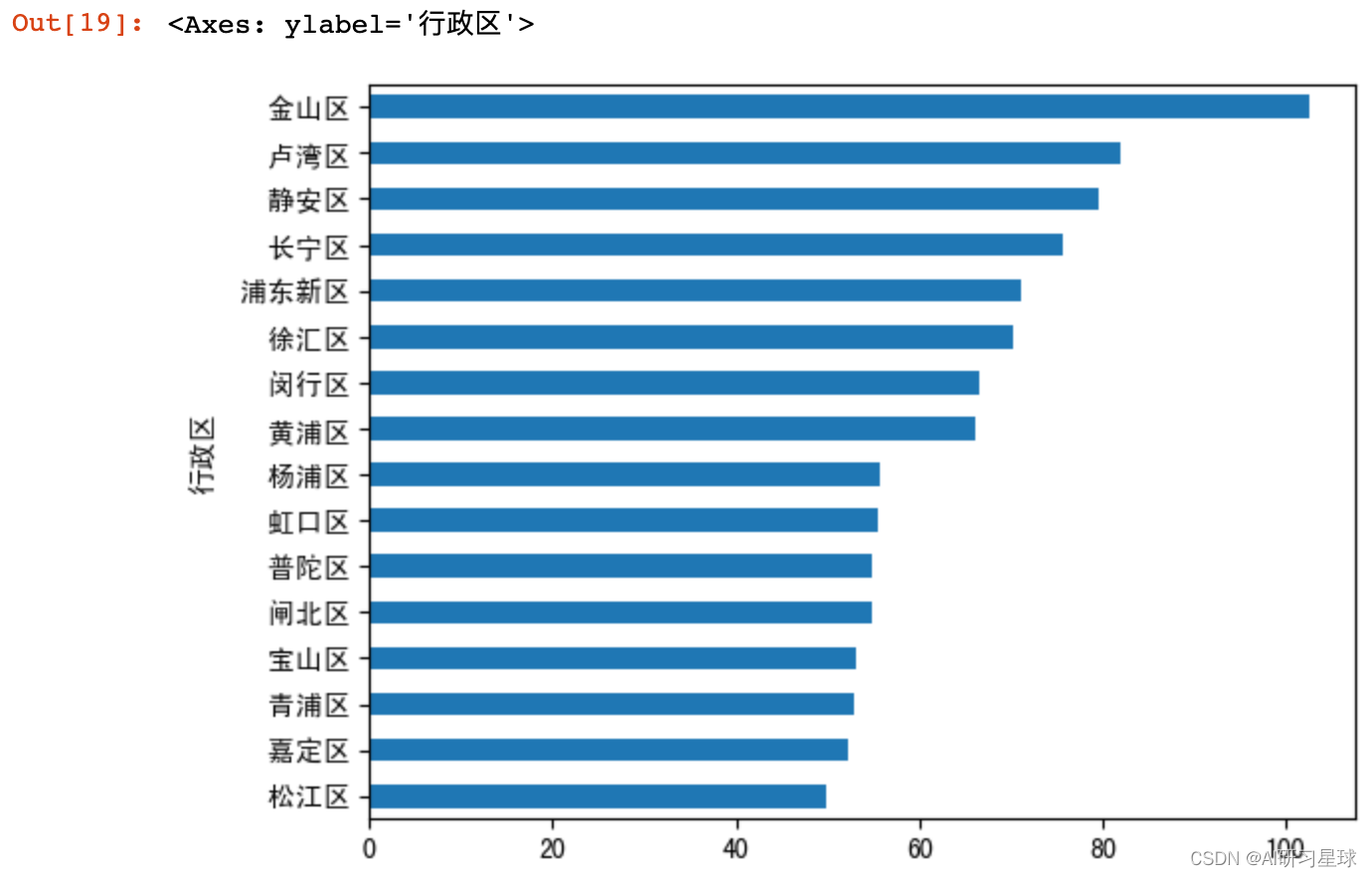
# 各行政区人均消费水平
df_groupby1 = df.groupby("行政区")["人均消费"].mean().sort_values(ascending=True)
df_groupby1.plot.barh()
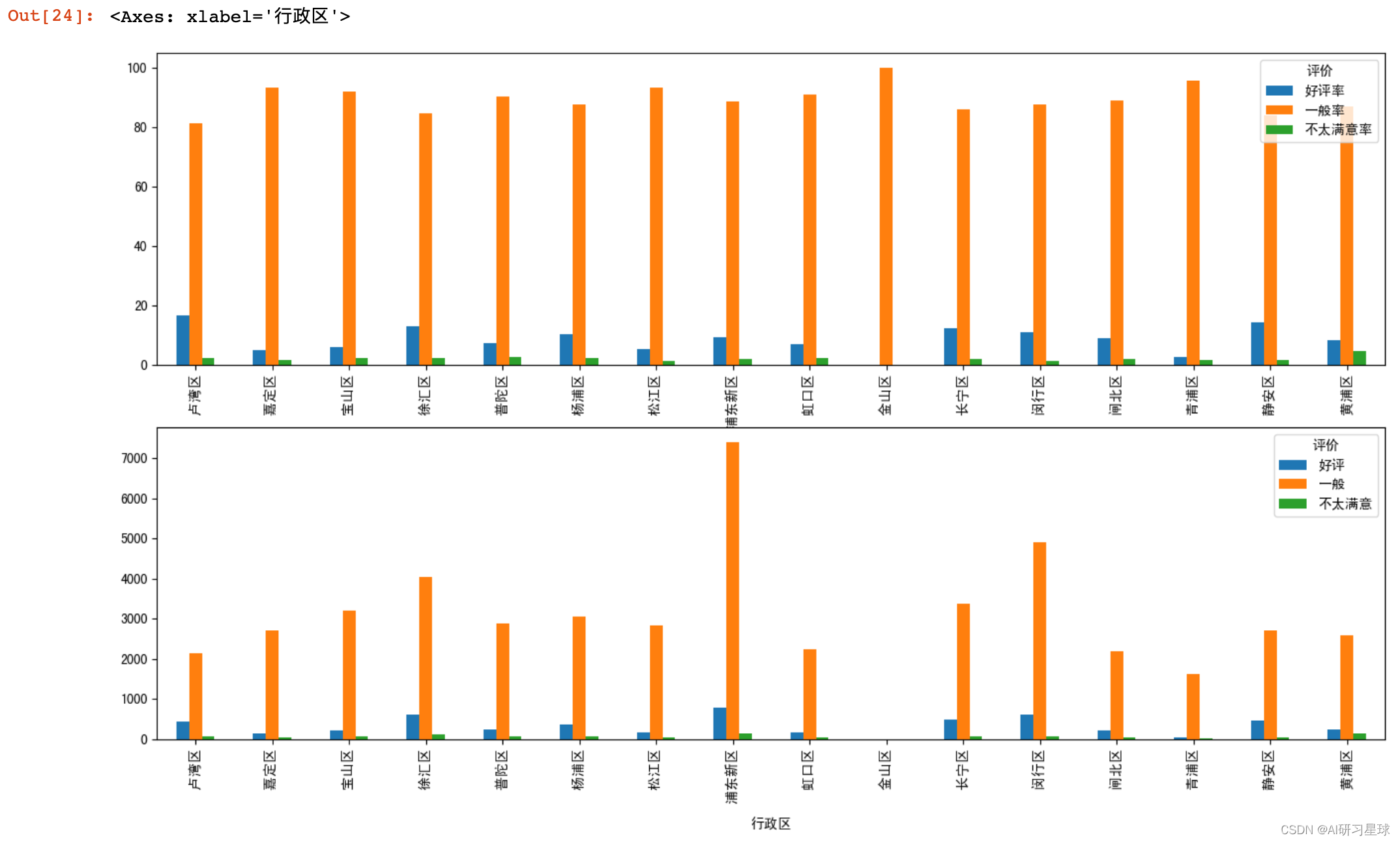
# 这里认为口味、环境,服务的平均大于8.5认为是受到好评的店铺
def bins(score):
if score >=8.5:
pinjia = '好评'
elif score >=6.5:
pinjia = '一般'
else:
pinjia = '不太满意'
return pinjia
df["综合评分"] = (df['口味'] + df['环境']+ df['服务'])/3
df['评价'] = df["综合评分"].apply(lambda s:bins(s))
df_pivot = pd.pivot_table(df,values="口味",index="行政区",columns="评价",aggfunc='count',fill_value=0)
df_pivot["总和"] = df_pivot.sum(axis=1)
df_pivot["好评率"] = round(df_pivot["好评"]/df_pivot["总和"],3)*100
df_pivot["一般率"] = round(df_pivot["一般"]/df_pivot["总和"],3)*100
df_pivot["不太满意率"] = round(df_pivot["不太满意"]/df_pivot["总和"],3)*100
fig,axes = plt.subplots(2,1,figsize = (16,9))
df_pivot[["好评率","一般率","不太满意率"]].plot(kind = 'bar',ax=axes[0])
df_pivot[["好评","一般","不太满意"]].plot(kind = 'bar',ax=axes[1])
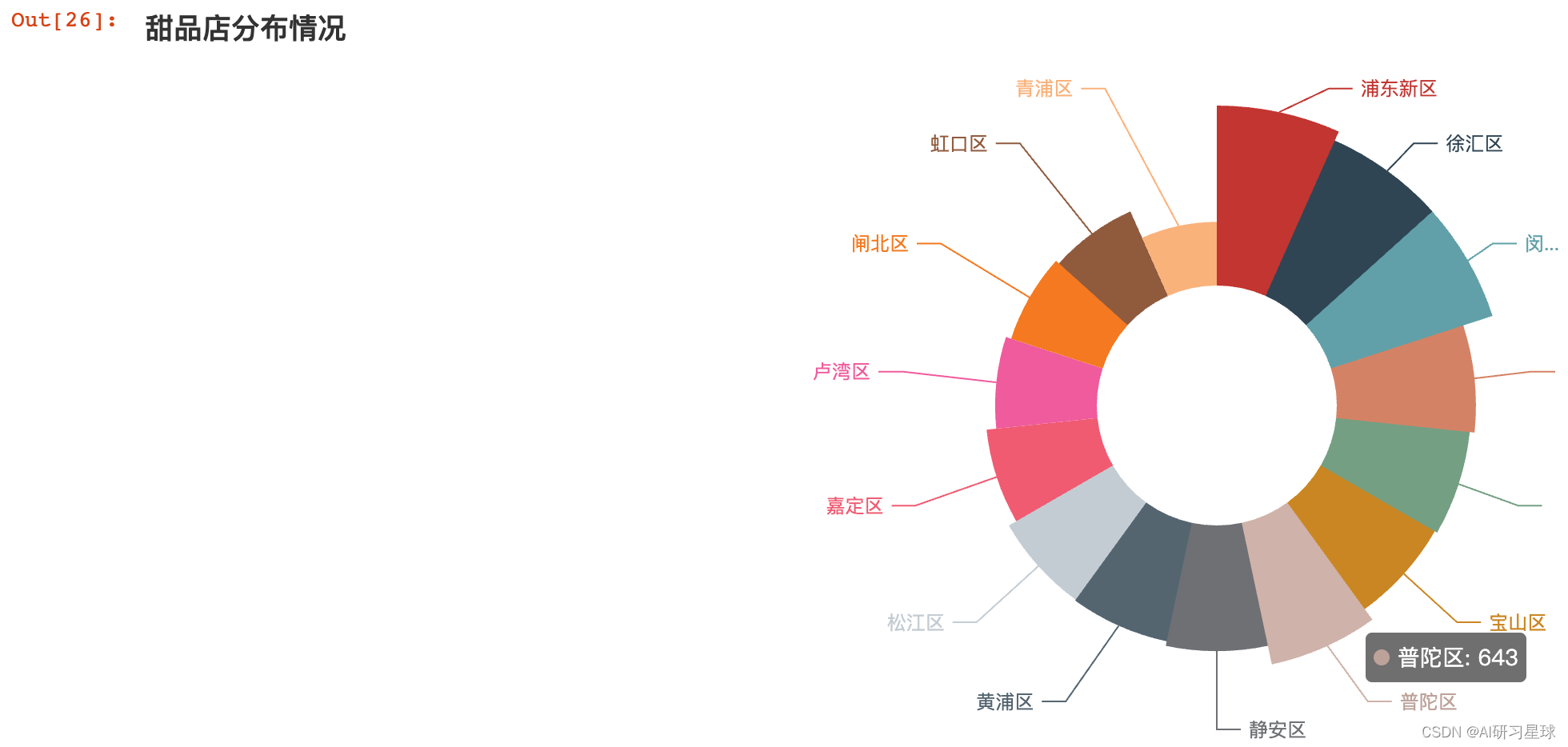
7、甜品店在上海各行政区的分布情况
df_group_tianpin = df[df["类别"] == '甜点']["行政区"].value_counts()
districts = df_group_tianpin.index.str.strip() # 由于行政区字段含有空格字符,避免下面图形没有数值
number = [int(i) for i in df_group_tianpin.values] #numpy.int64转成int类型,pyecharts只支持class'int'
pie_1 = (
Pie()
.add(
"",
[list(z) for z in zip(districts,number)],
radius=["30%","75%"],
center=["75%","50%"],
rosetype="area",
)
.set_global_opts(title_opts=opts.TitleOpts(title="甜品店分布情况")
,legend_opts=opts.LegendOpts(is_show = False))
)
pie_1.render_notebook()
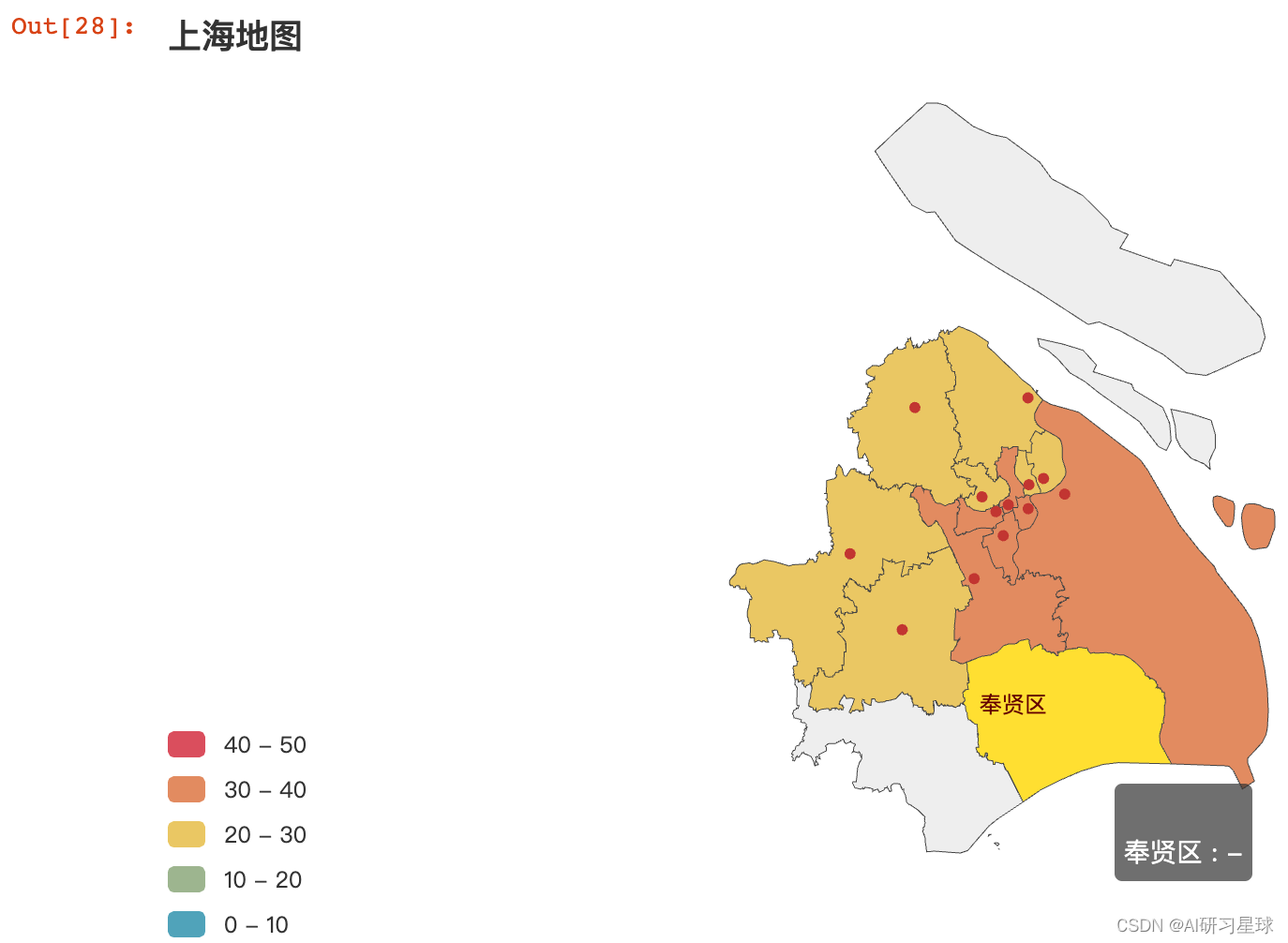
df_group_tianpin1 = df[df["类别"] == '甜点'].groupby("行政区")["人均消费"].mean()
from pyecharts.charts import Map
districts = df_group_tianpin1.index.str.strip() # 由于行政区字段含有空格字符,避免下面图形没有数值
values = df_group_tianpin1.values.round(2)
map_1 = (Map().add("",[list(z) for z in zip(districts,values)]
,maptype='上海',is_roam=False,label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="上海地图"), visualmap_opts=opts.VisualMapOpts(max_=50, is_piecewise=True)
)
)
map_1.render_notebook()
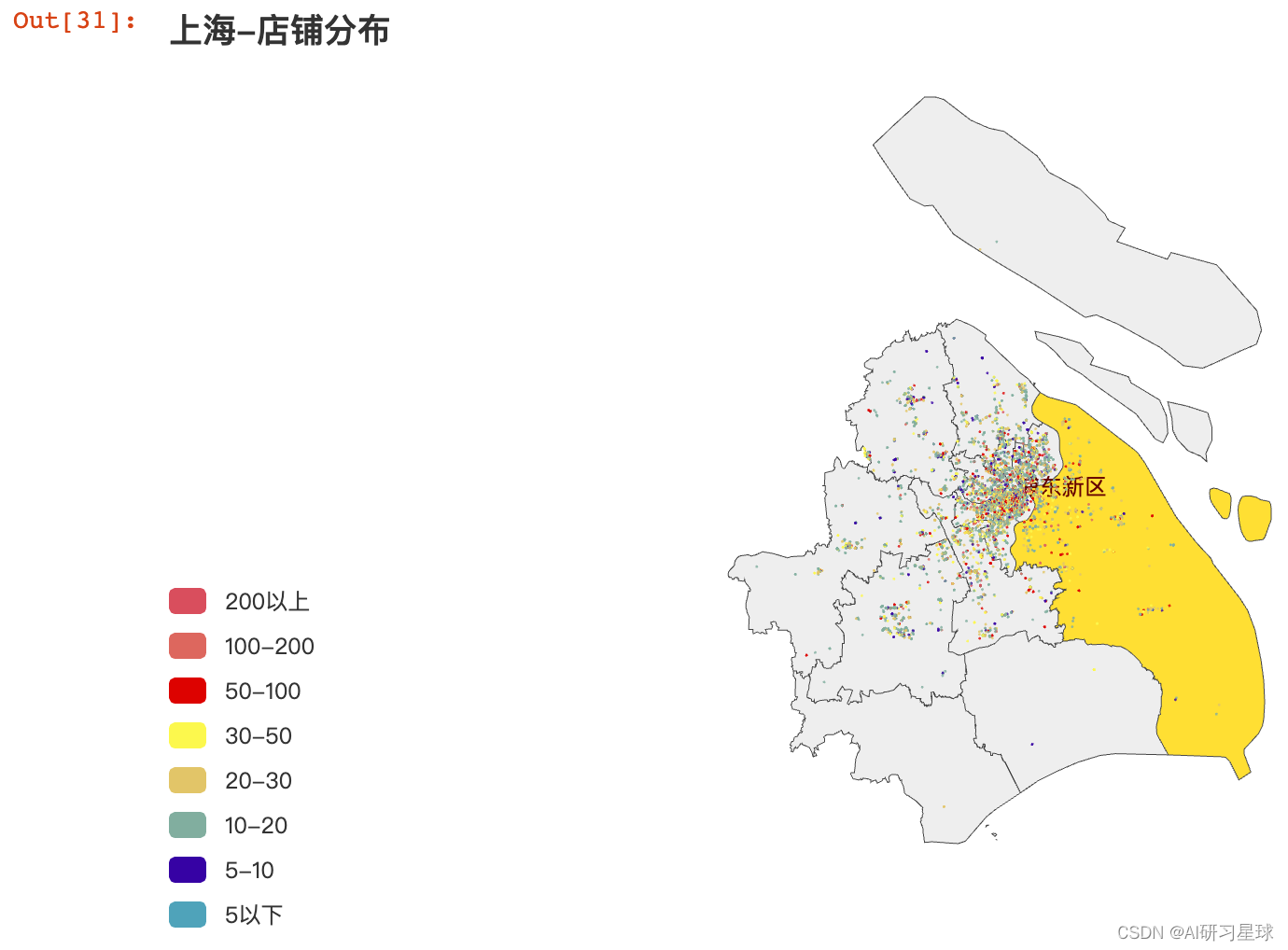
df = df[df["类别"] == '甜点'].reset_index()
df["index"] = df["index"].astype(str)
geo_sight_coord = {df["index"][i].strip():[df["Lng"][i],df["Lat"][i]] for i in range(len(df))} # 构建位置字典数据
data_pair = [(df["index"][i].strip(),int(df["人均消费"][i])) for i in range(len(df))] # 构建项目人均消费数据
from pyecharts.globals import GeoType
def test_geo(coord,data_pair):
city = '上海'
g = Geo()
g.add_schema(maptype=city,is_roam=False)
geo_sight_coord = coord
data_pair = data_pair
# 定义坐标对应的名称,添加到坐标库中 add_coordinate(name, lng, lat)
for key,value in geo_sight_coord.items():
g.add_coordinate(key,value[0],value[1]) # 追加点位置
# Geo 图类型,有 scatter, effectScatter, heatmap, lines 4 种,建议使用
# from pyecharts.globals import GeoType
# GeoType.GeoType.EFFECT_SCATTER,GeoType.HEATMAP,GeoType.LINES
# 将数据添加到地图上
g.add('',data_pair, symbol_size=1.5)
# 设置样式
g.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
# 自定义分段 color 可以用取色器取色
pieces = [
{'max': 5, 'label': '5以下', 'color': '#50A3BA'},
{'min': 5, 'max': 10, 'label': '5-10', 'color': '#3700A4'},
{'min': 10, 'max': 20, 'label': '10-20', 'color': '#81AE9F'},
{'min': 20, 'max': 30, 'label': '20-30', 'color': '#E2C568'},
{'min': 30, 'max': 50, 'label': '30-50', 'color': '#FCF84D'},
{'min': 50, 'max': 100, 'label': '50-100', 'color': '#DD0200'},
{'min': 100, 'max': 200, 'label': '100-200', 'color': '#DD675E'},
{'min': 200, 'label': '200以上', 'color': '#D94E5D'} # 有下限无上限
]
# is_piecewise 是否自定义分段, 变为true 才能生效
g.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True, pieces=pieces),
title_opts=opts.TitleOpts(title="{}-店铺分布".format(city)),
)
return g
g = test_geo(geo_sight_coord,data_pair)
# 渲染成html, 可用浏览器直接打开
# g.render()
g.render_notebook()
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我



















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











