







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
项目背景
来自京东平台上的数据,万代奥特曼与万代高达以及乐高三大类型玩具的数据对比分析,消费者更爱哪一类?
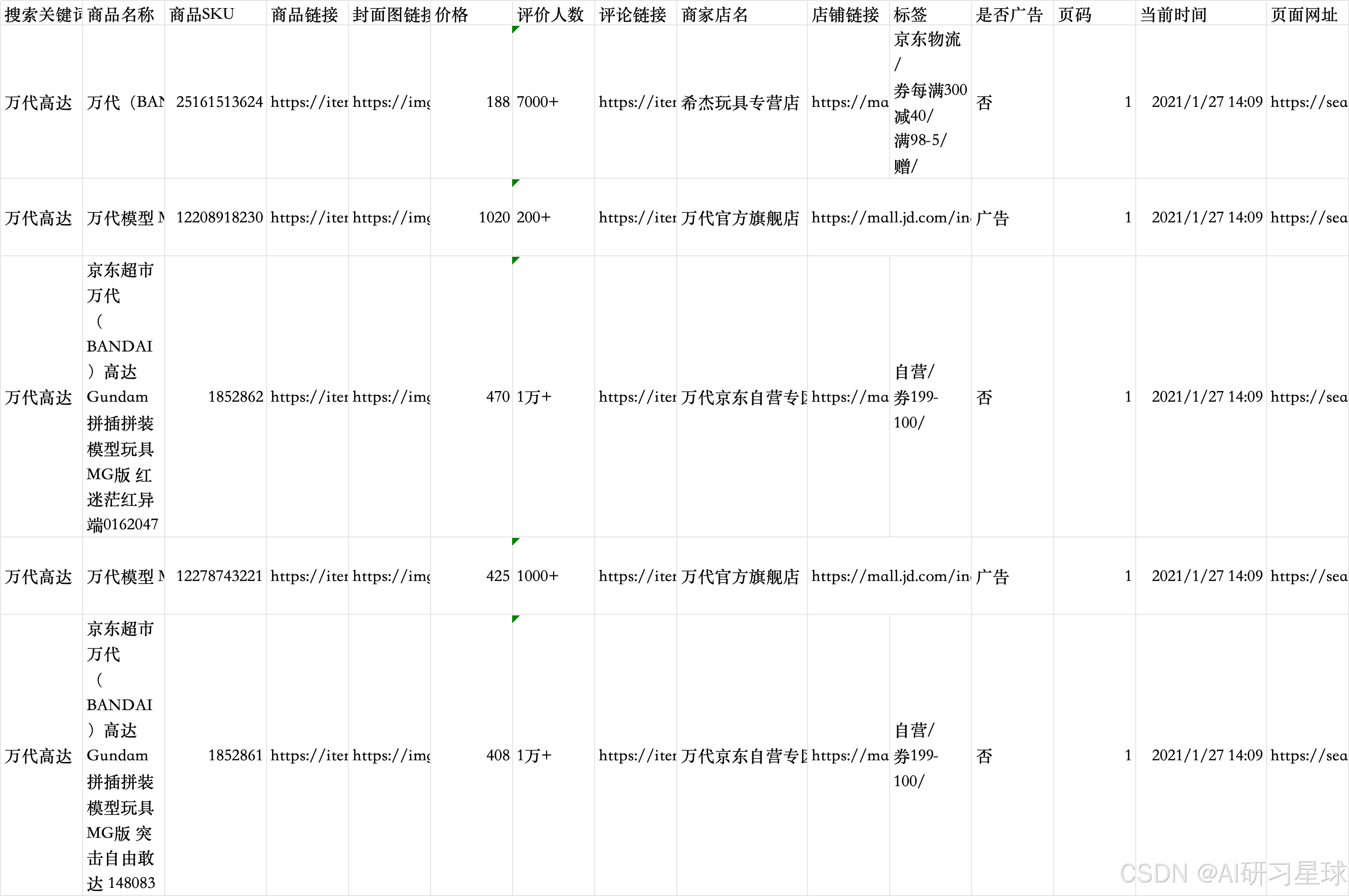
数据描述
该数据共三份,分类是高达.csv、奥特曼.csv、乐高.csv。
字段共15个。
- 搜索关键词
- 商品名称
- 商品SKU
- 商品链接
- 封面图链接
- 价格
- 评价人数
- 评论链接
- 商家店名
- 店铺链接
- 标签
- 是否广告
- 页码
- 当前时间
- 页面网址
以下是表的部分数据
一、分析数据
1、读取数据
# 导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
import plotly.io as pio
import plotly.graph_objects as go
import plotly.express as px
# 导入数据
gundam = pd.read_csv('高达.csv')
legao = pd.read_csv('乐高.csv')
atm = pd.read_csv('奥特曼.csv')
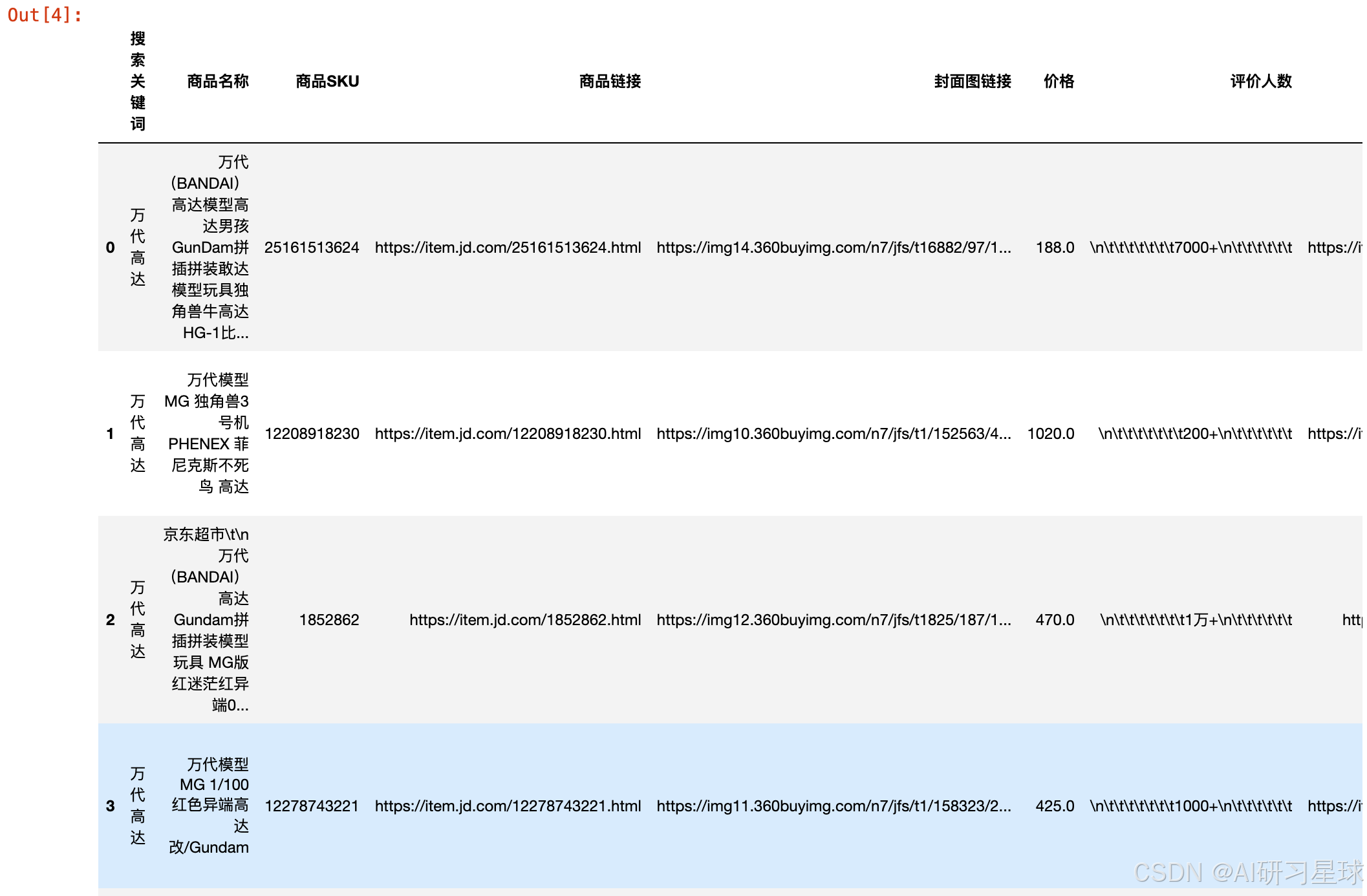
# 合并数据
toys = pd.concat([gundam,legao,atm],axis=0)
toys = toys.reset_index(drop=True)
toys.head()
toys = toys.drop(['商品链接','封面图链接','评论链接','店铺链接','页面网址','标签'],axis=1)
2、去掉数据中的特殊符号、处理空值、缺失值等
a、处理评价人数字段中的特殊符号
a = toys['评价人数'].astype('str')
ls=[]
for i in a:
content = re.sub(r'\d+','',i)
ls.append(content)
unique_ls=list(set(ls))
print(unique_ls)
[‘\n\t\t\t\t\t\t\t+\n\t\t\t\t\t\t’, ‘\n\t\t\t\t\t\t\t万+\n\t\t\t\t\t\t’, ‘\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t’]
toys['评价人数']=toys['评价人数'].apply(lambda x:x.replace('\n','').replace('\t',''))
def r_comment(x):
x=x.replace('+','')
if '万' in x:
x=x.replace(r'万','')
x=float(x)*10000
return x
else:
return x
toys['comments'] = toys['评价人数'].apply(lambda x:r_comment(x)).astype('int')
b、处理商品名称字段中的特殊字符
toys['商品名称'] = toys['商品名称'].apply(lambda x:x.replace('\n',' ').replace('\t',' '))
c、查看数据形状
toys.shape
(17991, 10)
d、重复值
toys.duplicated().sum()
4
e、删除重复值
toys.drop_duplicates(inplace=True)
f、查看空值
toys.isnull().sum()

g、删除空值
toys.dropna(inplace=True)
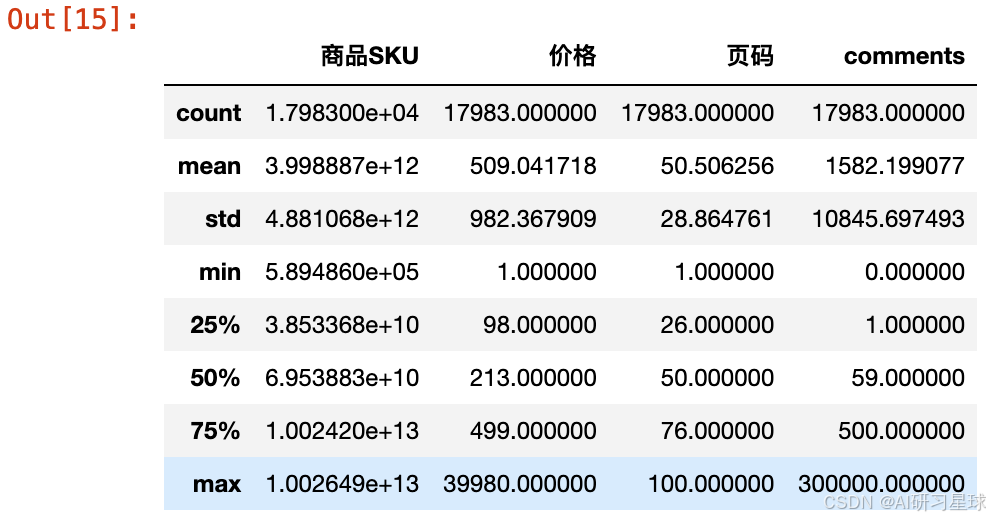
h、描述统计
toys.describe()
toys.info()

i、增加店铺分类
def shop_group(frame):
shop_group=[]
for i in range(len(frame)):
if '京东自营' in frame.iloc[[i,5]]:
shop_group.append('京东自营')
elif '旗舰店' in frame.iloc[[i,5]]:
shop_group.append('旗舰店')
elif '专营店' in frame.iloc[[i,5]]:
shop_group.append('专营店')
elif '京东国际' in frame.iloc[[i,5]]:
shop_group.append('京东国际')
else:
shop_group.append('其它')
frame['店铺分类']=shop_group
shop_group(toys)
二、数据分析可视化部分
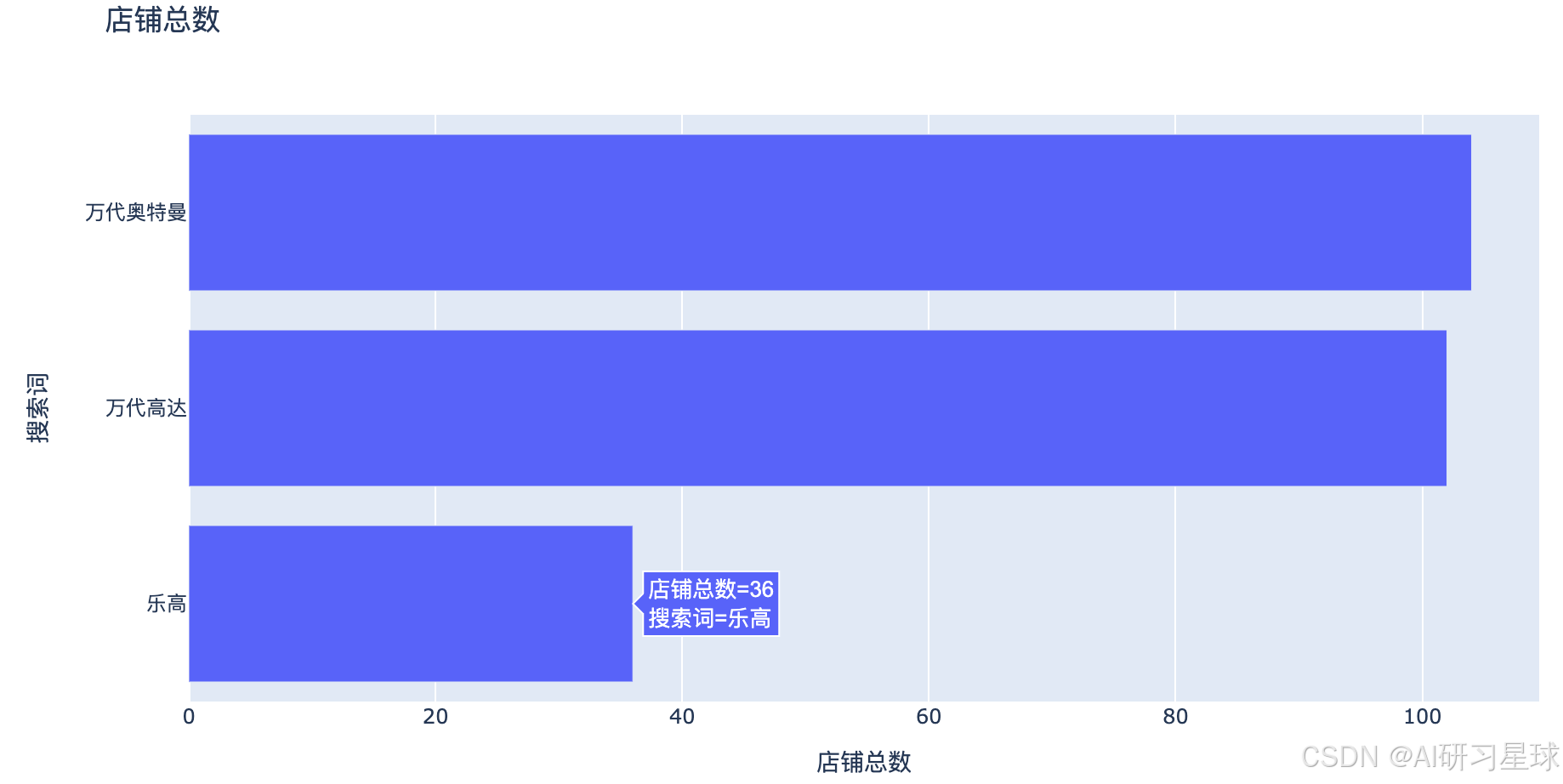
1、店铺数量
result = toys.groupby('搜索关键词')['商家店名'].nunique()
result.sort_values(inplace=True)
fig = px.bar(y=result.index,x=result.values,labels={"y":"搜索词","x":"店铺总数"},title='店铺总数')
fig.show()
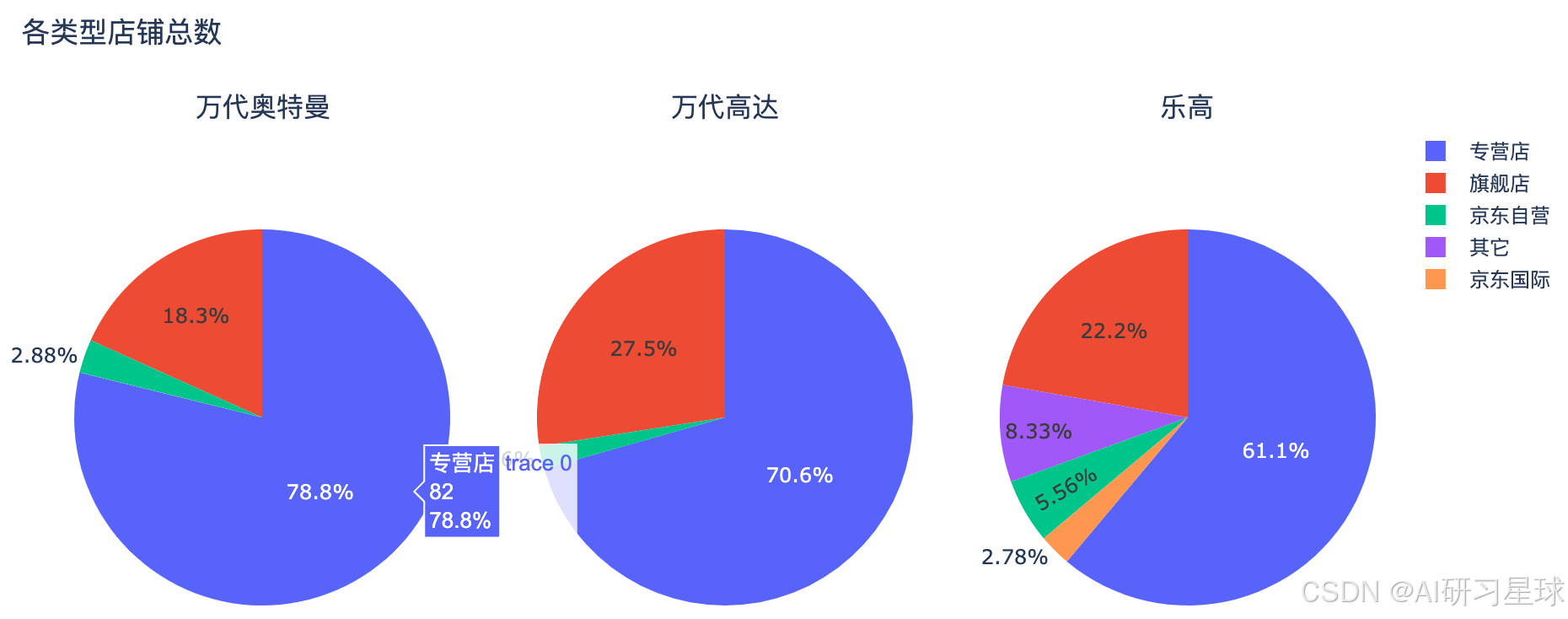
2、不同类型的店铺总数
result1 = toys[toys['搜索关键词']=='万代奥特曼'].groupby('店铺分类')['商家店名'].nunique()
result2 = toys[toys['搜索关键词']=='万代高达'].groupby('店铺分类')['商家店名'].nunique()
result3 = toys[toys['搜索关键词']=='乐高'].groupby('店铺分类')['商家店名'].nunique()
from plotly.subplots import make_subplots
fig = make_subplots(rows = 1,cols = 3,specs=[[{'type':'domain'},{'type':'domain'},{'type':'domain'}]],
subplot_titles=('万代奥特曼','万代高达','乐高'))
fig.add_trace(go.Pie(labels=result1.index,values=result1.values),1,1)
fig.add_trace(go.Pie(labels=result2.index,values=result2.values),1,2)
fig.add_trace(go.Pie(labels=result3.index,values=result3.values),1,3)
fig.update_layout(title_text='各类型店铺总数')
fig.show()
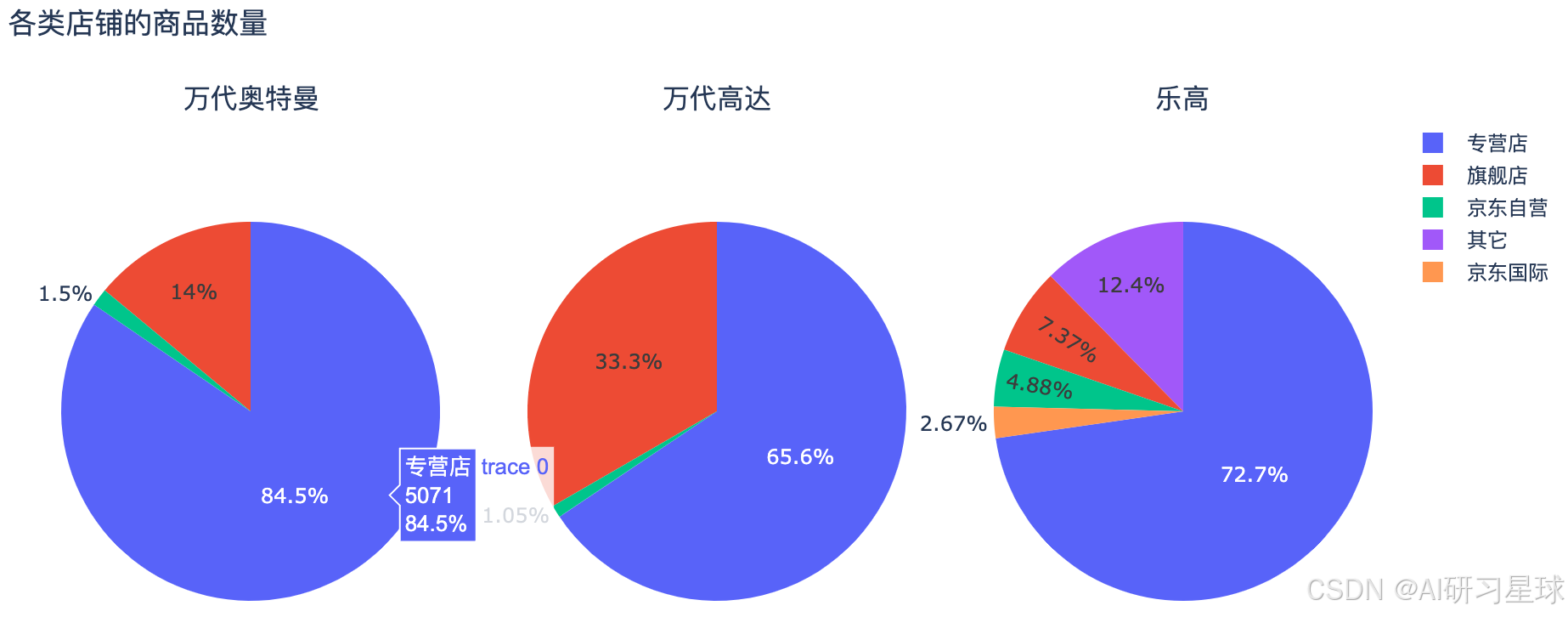
3、不同店铺类型的商品数量
result1 = toys[toys['搜索关键词']=='万代奥特曼'].groupby('店铺分类')['商品名称'].count()
result2 = toys[toys['搜索关键词']=='万代高达'].groupby('店铺分类')['商品名称'].count()
result3 = toys[toys['搜索关键词']=='乐高'].groupby('店铺分类')['商品名称'].count()
from plotly.subplots import make_subplots
fig = make_subplots(rows = 1,cols = 3,specs=[[{'type':'domain'},{'type':'domain'},{'type':'domain'}]],
subplot_titles=('万代奥特曼','万代高达','乐高'))
fig.add_trace(go.Pie(labels=result1.index,values=result1.values),1,1)
fig.add_trace(go.Pie(labels=result2.index,values=result2.values),1,2)
fig.add_trace(go.Pie(labels=result3.index,values=result3.values),1,3)
fig.update_layout(title_text='各类店铺的商品数量')
fig.show()
4、价格分布
fig = px.histogram(toys,x='价格',facet_col='搜索关键词',nbins=150,facet_col_wrap=3)
fig.show()
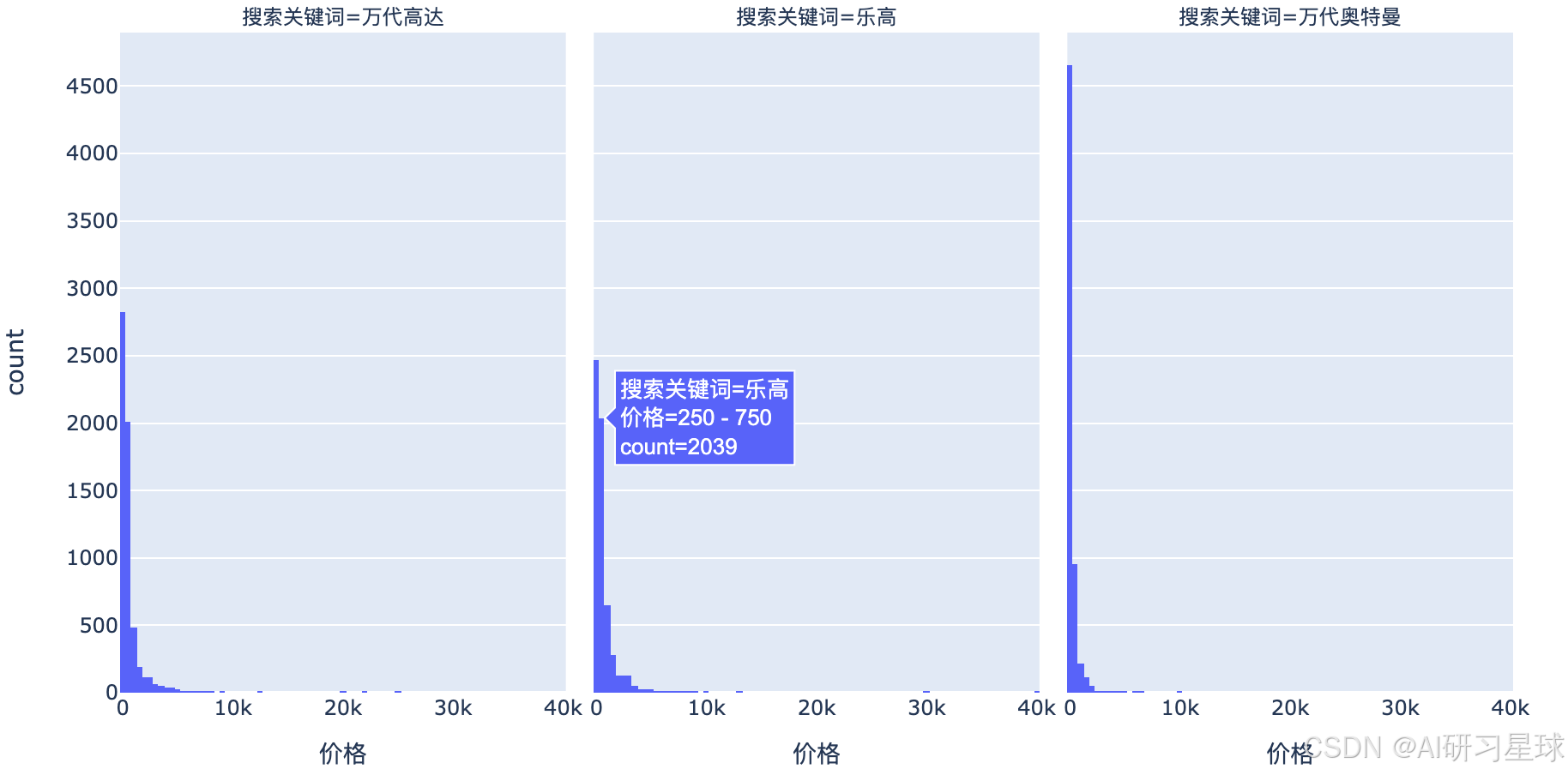
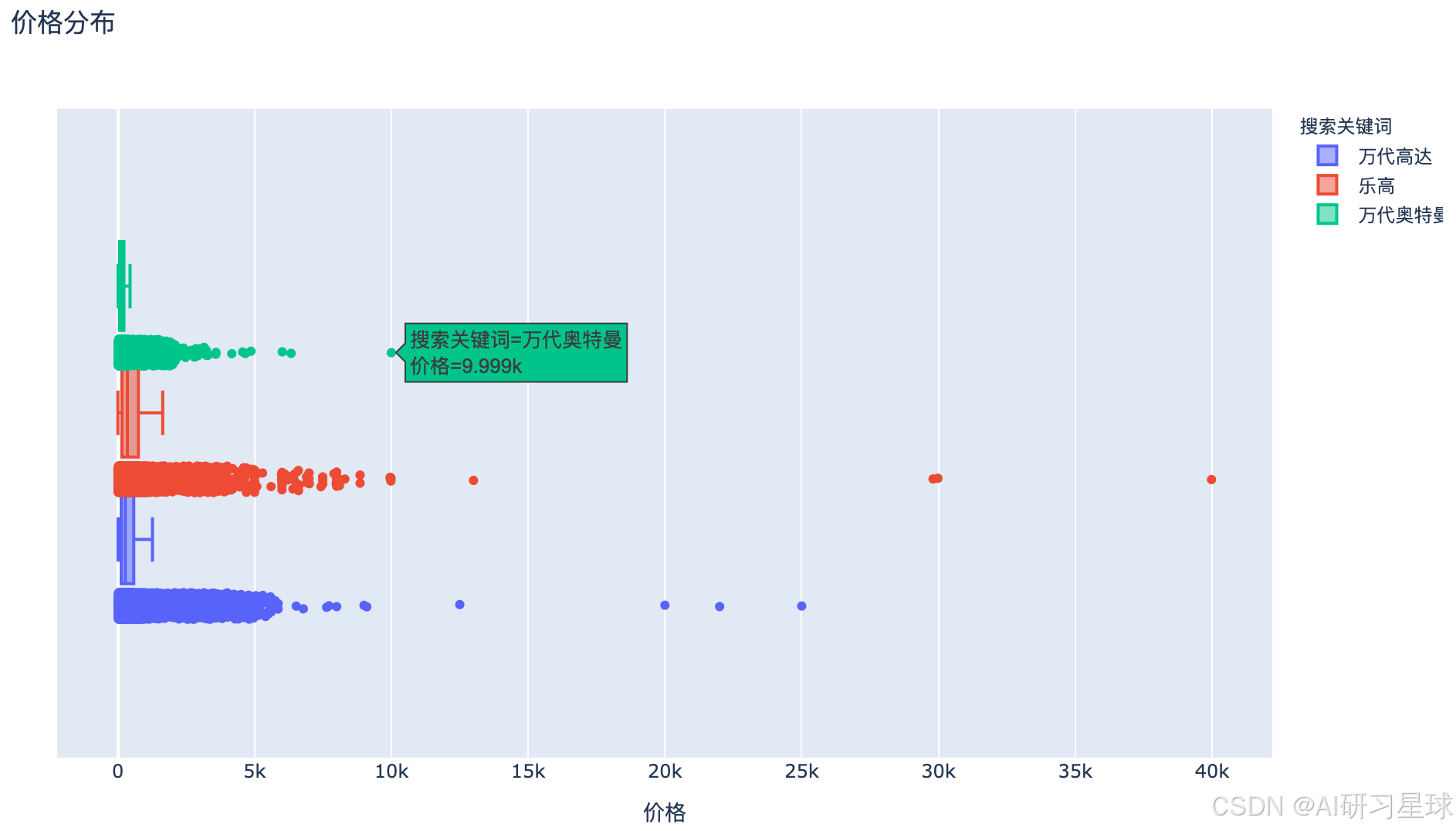
fig = px.box(toys,x=toys['价格'],color=toys['搜索关键词'],title='价格分布',points='all')
fig.update_layout(width=1000, height=600)
fig.show()
price = toys.groupby('搜索关键词').agg(mean=('价格','mean'),max=('价格','max'),min=('价格','min'))
price['mean'] = price['mean'].round(1)
price.sort_values(by='mean',ascending=False,inplace=True)
fig = go.Figure(data=[go.Table(header=dict(values=['搜索商品','平均价格','最高单价','最低单价']),
cells=dict(values=[price.index.tolist(),price['mean'].tolist(),
price['max'].tolist(),price['min'].tolist()]))])
fig.update_layout(width=800, height=300)
fig.show()

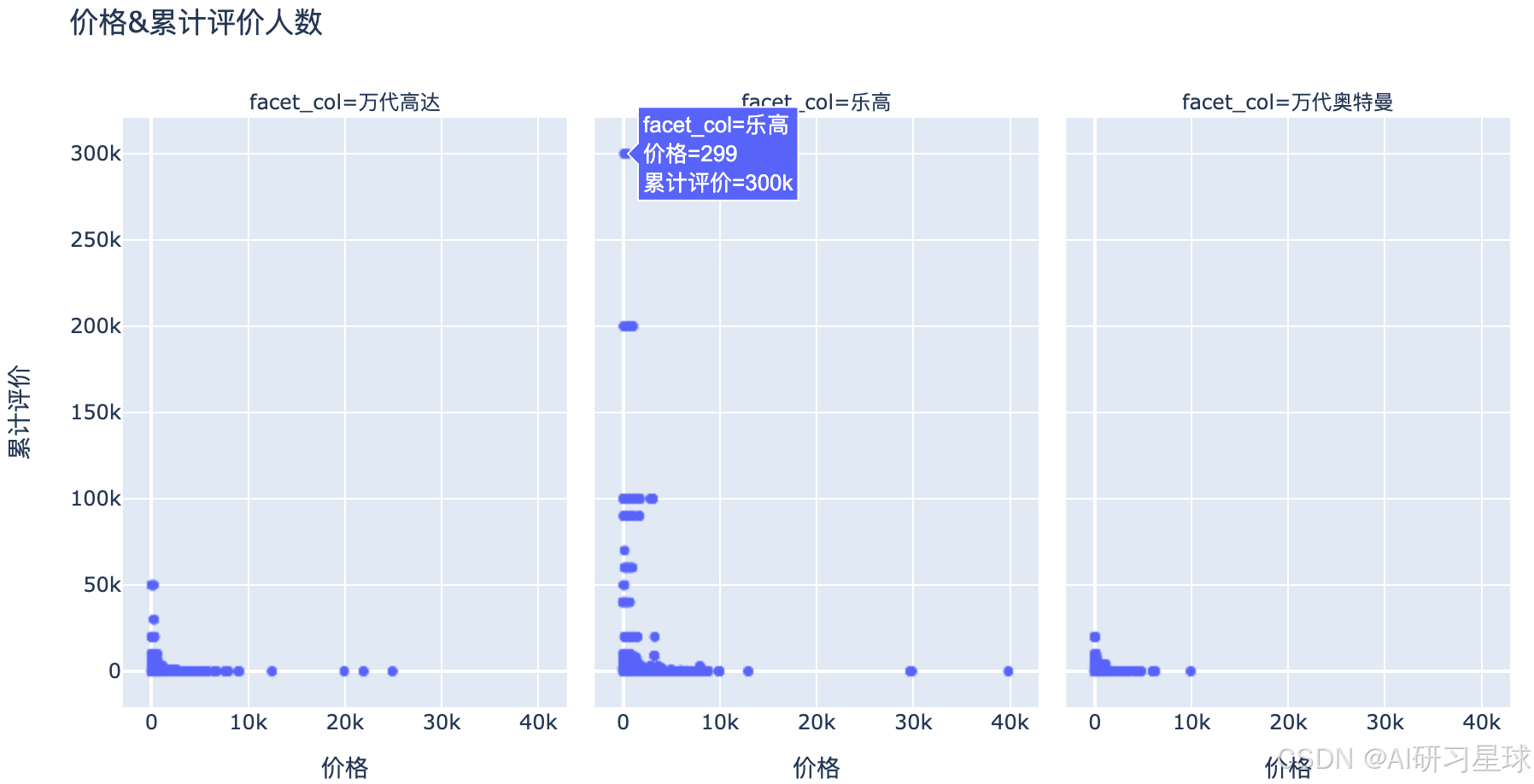
5、透过累计评价人来查看产品的受欢迎程度
不同店铺类型的受欢迎程度——累计评价人数
fig = px.scatter(x=toys['价格'],y=toys['comments'],title='价格&累计评价人数',facet_col=toys['搜索关键词'],facet_col_wrap=3,labels={"x":"价格","y":"累计评价"})
fig.show()
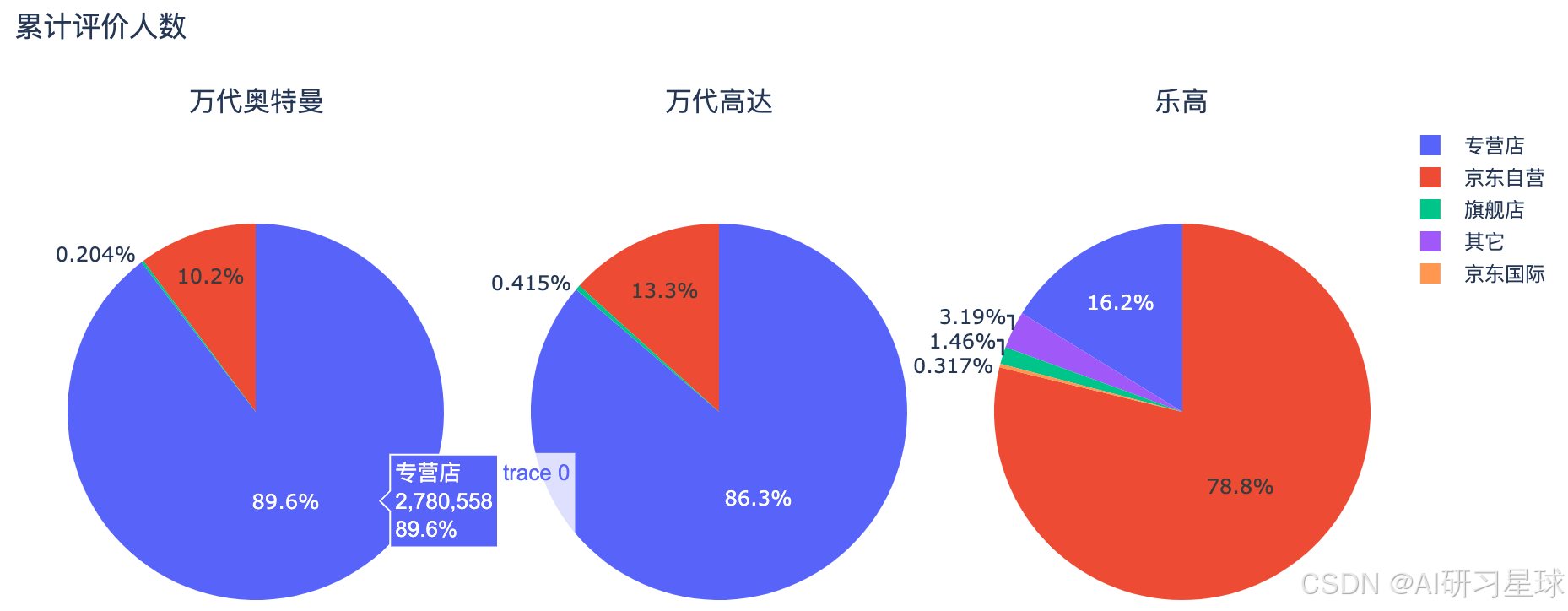
result1 = toys[toys['搜索关键词']=='万代奥特曼'].groupby('店铺分类').comments.sum()
result2 = toys[toys['搜索关键词']=='万代高达'].groupby('店铺分类').comments.sum()
result3 = toys[toys['搜索关键词']=='乐高'].groupby('店铺分类').comments.sum()
from plotly.subplots import make_subplots
fig = make_subplots(rows = 1,cols = 3,specs=[[{'type':'domain'},{'type':'domain'},{'type':'domain'}]],
subplot_titles=('万代奥特曼','万代高达','乐高'))
fig.add_trace(go.Pie(labels=result1.index,values=result1.values),1,1)
fig.add_trace(go.Pie(labels=result2.index,values=result2.values),1,2)
fig.add_trace(go.Pie(labels=result3.index,values=result3.values),1,3)
fig.update_layout(title_text='累计评价人数')
fig.show()
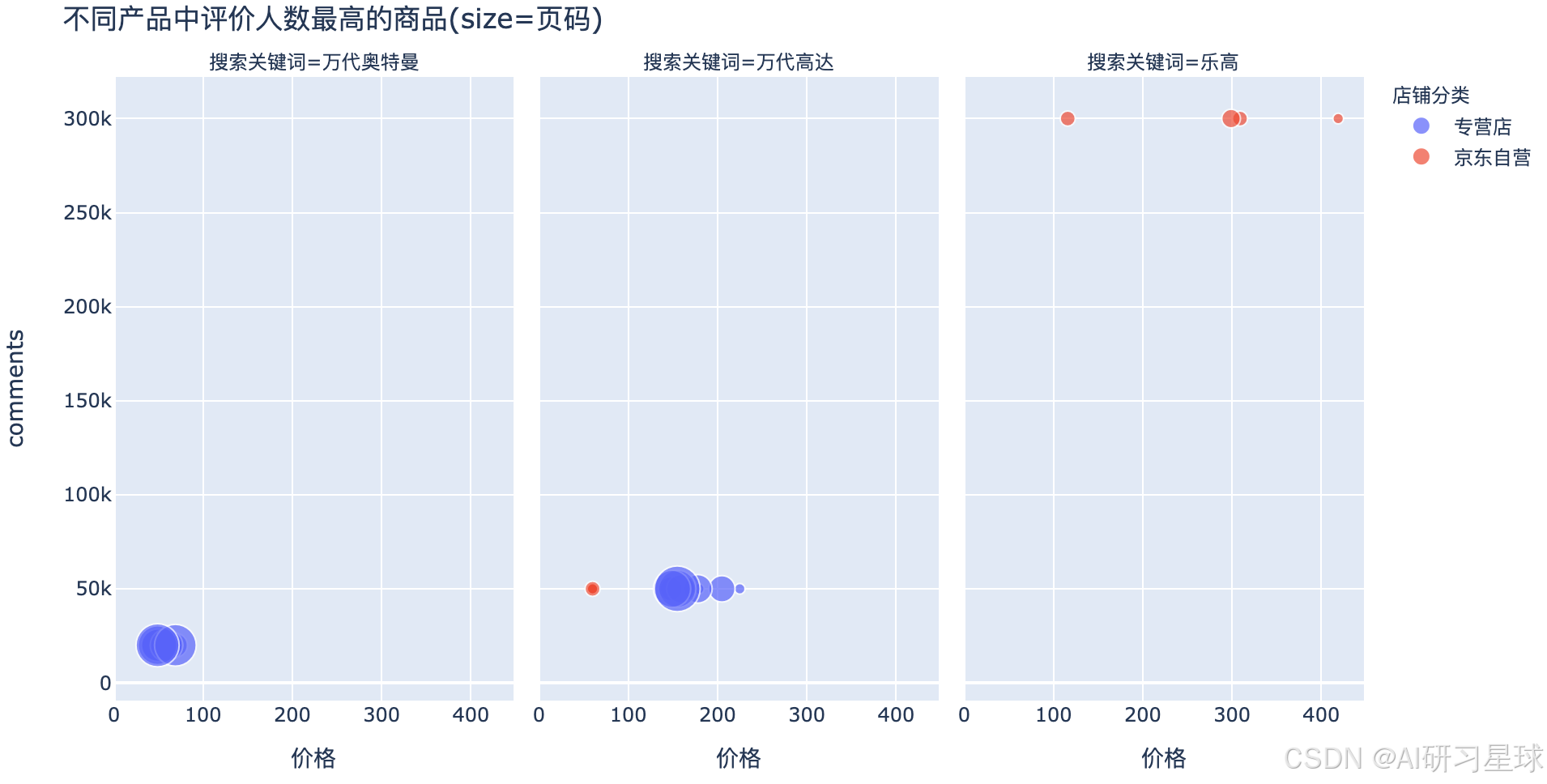
6、最受欢迎的产品——累计评价最高的产品
toys.groupby('搜索关键词').comments.max()

三种不同类型的玩具中,乐高的最大值远高于其它两类的评价人数
r1 = toys[(toys['搜索关键词']=='万代奥特曼')&(toys['comments']==20000)]
r2 = toys[(toys['搜索关键词']=='万代高达')&(toys['comments']==50000)]
r3 = toys[(toys['搜索关键词']=='乐高')&(toys['comments']==300000)]
result_r = pd.concat([r1,r2,r3],axis=0)
result_r = result_r.reset_index(drop=True)
fig = px.scatter(result_r,x='价格',y='comments',size='页码',facet_col='搜索关键词',facet_col_wrap=3,color='店铺分类',hover_name='商品名称')
fig.update_layout(title='不同产品中评价人数最高的商品(size=页码)')
fig.show()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











