







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
一、项目背景
本项目主要针对快餐店订单数据进行分析,有助于帮助快餐店分析哪类产品畅销,以及通过时间序列对未来一个月的销售额、销售量进行了预测,有助于餐厅进行资源规划。
二、数据说明
该数据共1000行,字段共10个。
| 字段 | 说明 |
|---|---|
| order_id | 每个订单的唯一标识符 |
| date | 交易日期 |
| item_name | 食物名称 |
| item_type | 物品类别(快餐或饮料) |
| item_price | 每个物品的单价 |
| Quantity | 客户订购的数量 |
| transaction_amount | 客户支付的总金额 |
| transaction_type | 支付方式(现金、在线支付、其他) |
| received_by | 处理订单的人的性别 |
| time_of_sale | 订单交易时间(早上、晚上、下午、夜间、午夜) |
三、数据分析
a、Python库导入及数据读取
导入包
# 导入需要的库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.statespace.sarimax import SARIMAX
from pmdarima import auto_arima # 自动选择参数
import statsmodels.api as sm
import warnings
warnings.filterwarnings('ignore')
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体 宋体
mpl.rcParams["axes.unicode_minus"] = False #字体更改后,会导致坐标轴中的部分字符无法正常显示,此时需要设置正常显示负号
数据读取
# 读取数据
data = pd.read_csv("Balaji Fast Food Sales.csv")
b、数据预览及数据处理
i、数据预览
# 查看数据维度
data.shape
(1000, 10)
# 查看数据信息
data.info()
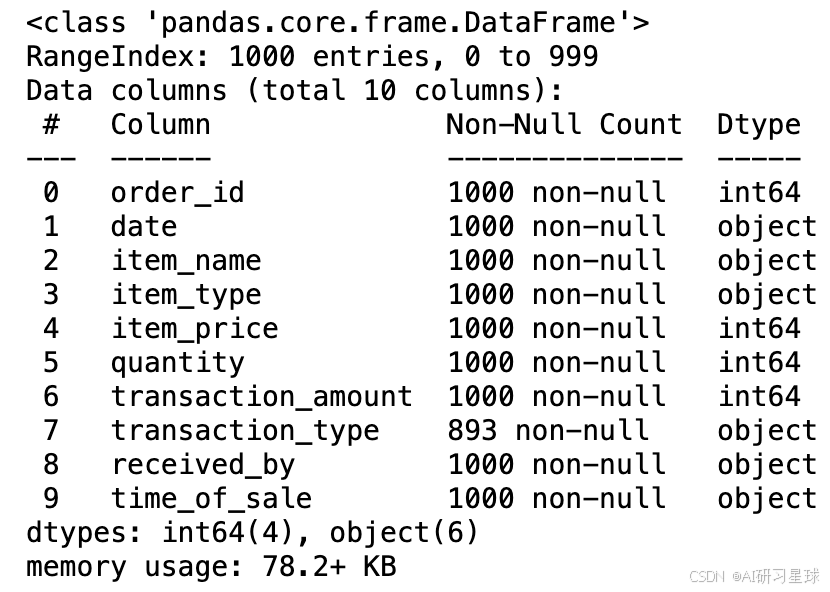
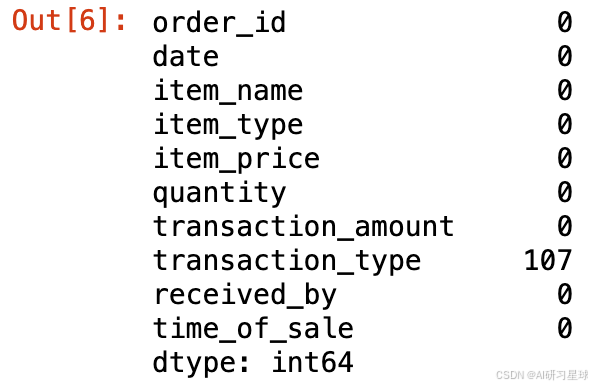
# 查看各列缺失值
data.isna().sum()
# 查看重复值
data.duplicated().sum()
0
ii、数据预处理
# 处理数据之前,先查看一下数据
data.head()

# 修改order_id格式
data['order_id'] = data['order_id'].astype(str)
# 将date列转换为日期格式
data['date'] = pd.to_datetime(data['date'])
# 用'Others'填充transaction_type列的缺失值
data['transaction_type'].fillna('Others', inplace=True)
c、数据探索
i、描述性统计
data.describe(include=[np.number]) # 只包括数值型字段
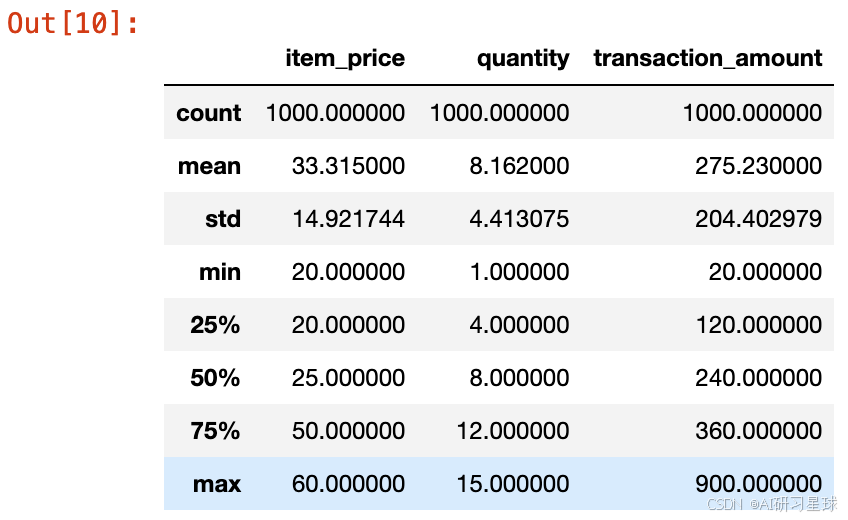
总结:
- 单价在20到60美元之间,平均单价约33.315美元,标准差约为14.92。
- 客户订购数量的平均值约为8.16,中位数为8,最小值为1,最大值为15,四分位数范围表明大多数订单的数量在4到12之间。
- 客户支付的总金额平均为275.23美元,中位数为240美元,最小值为20美元,最大值为900美元,标准差为204.4,表明交易金额的分布范围较广。
ii、可视化分析
sns.set_style("darkgrid")
# 调整画布大小和子图排列
fig = plt.figure(figsize=(15,15))
# 创建2x2的图布局
# 添加前四个小图
ax1 = fig.add_subplot(3, 2, 1)
ax2 = fig.add_subplot(3, 2, 2)
ax3 = fig.add_subplot(3, 2, 3)
ax4 = fig.add_subplot(3, 2, 4)
# 添加第三行的大图,这个大图跨越了两列
ax5 = fig.add_subplot(3, 1, 3)
# Item_type分布图
sns.countplot(x='item_type', data=data, ax=ax1)
ax1.set_title('Item Type Distribution')
ax1.set_xlabel('Item Type')
ax1.set_ylabel('Count')
# Transaction_type分布图
sns.countplot(x='transaction_type', data=data, ax=ax2)
ax2.set_title('Transaction Type Distribution')
ax2.set_xlabel('Transaction Type')
ax2.set_ylabel('Count')
# Received_by分布图
sns.countplot(x='received_by', data=data, ax=ax3)
ax3.set_title('Received By Gender Distribution')
ax3.set_xlabel('Received By')
ax3.set_ylabel('Count')
# Time_of_sale分布图
sns.countplot(x='time_of_sale', data=data, ax=ax4, order=['Morning', 'Afternoon', 'Evening', 'Night', 'Midnight'])
ax4.set_title('Time of Sale Distribution')
ax4.set_xlabel('Time of Sale')
ax4.set_ylabel('Count')
# Item_name的分布图
item_name_counts = data['item_name'].value_counts()
sns.barplot(y=item_name_counts.index, x=item_name_counts, ax=ax5)
ax5.set_title('Item Name Distribution')
ax5.set_xlabel('Frequency')
ax5.set_ylabel('Item Name')
plt.tight_layout()
plt.show()
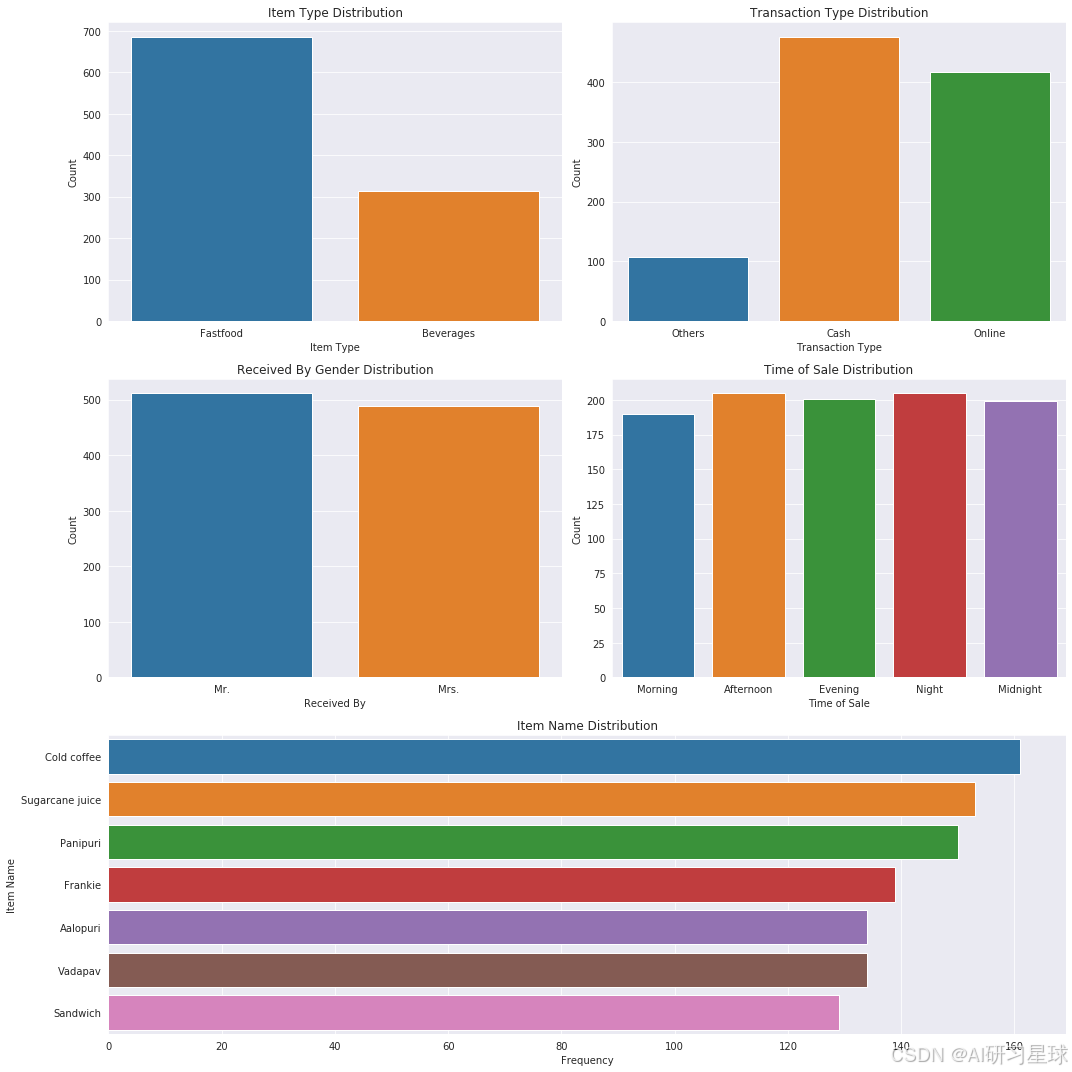
总结:
- 快餐是交易量最大的类别,表明快餐可能是该餐厅的主打产品。
- 现金和在线支付是最常见的两种交易方式,其中现金比在线支付更多一点,其他支付方式的使用频率较低。
- 男性和女性接待顾客的订单数量可能大致相等,显示出性别在工作分配上的均衡。
- 下午和晚上的销售量高于其他时段,这可能与顾客的生活习惯或该餐厅的营业高峰时段有关。
- 销售最多的商品是冷咖啡,最少的是三明治。
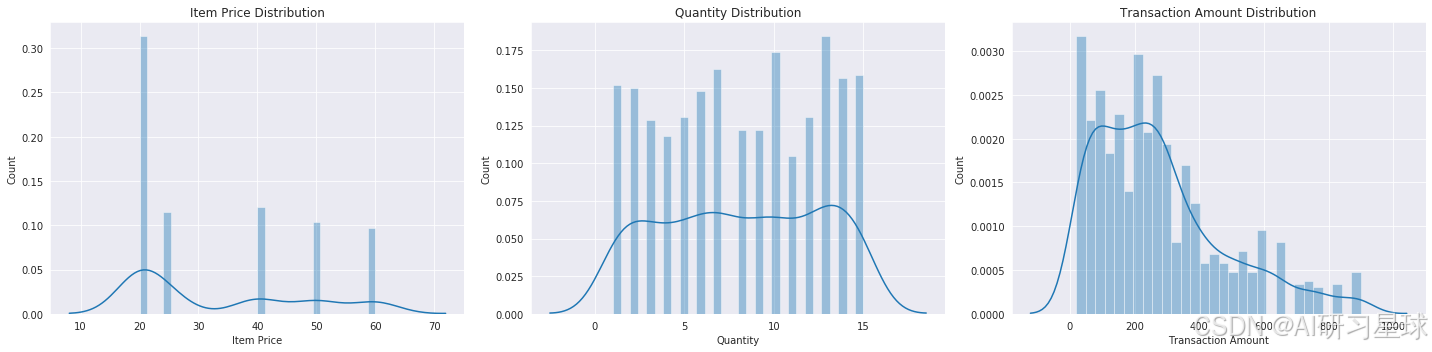
# 创建一个新的大图,用于展示3个数值型特征的分布情况
fig, axes = plt.subplots(1, 3, figsize=(20, 5))
# item_price的分布情况
sns.distplot(data["item_price"], bins=30, kde=True, ax=axes[0])
axes[0].set_title('Item Price Distribution')
axes[0].set_xlabel('Item Price')
axes[0].set_ylabel('Count')
# Quantity的分布情况
sns.distplot(data["quantity"], bins=30, kde=True, ax=axes[1])
axes[1].set_title('Quantity Distribution')
axes[1].set_xlabel('Quantity')
axes[1].set_ylabel('Count')
# transaction_amount的分布情况
sns.distplot(data["transaction_amount"], bins=30, kde=True, ax=axes[2])
axes[2].set_title('Transaction Amount Distribution')
axes[2].set_xlabel('Transaction Amount')
axes[2].set_ylabel('Count')
plt.tight_layout() # 调整子图布局
plt.show()
d、销售情况分析
i、销售量分析
time_category_sales = data.groupby(['time_of_sale', 'item_name'])['quantity'].sum().unstack().fillna(0)
# 获取每个时间段销售的总数量,以计算占比
time_sales_totals = time_category_sales.sum(axis=1)
time_category_sales_percentage = time_category_sales.divide(time_sales_totals, axis=0) * 100
# 绘制堆叠条形图,并在条形图中添加标签显示占比
fig, ax = plt.subplots(figsize=(14, 8)) # 设置图表大小
# 绘制堆叠条形图
time_category_sales.plot(kind='bar', stacked=True, colormap='viridis', ax=ax)
# 为了将标签放在条形中,我们计算每个条形的位置和高度
for i, (time_idx, item_row) in enumerate(time_category_sales.iterrows()):
cum_height = 0 # 累积高度,用于定位条形中的标签位置
for item_idx, value in item_row.iteritems():
# 计算占比
percentage = value / item_row.sum() * 100
if value > 0: # 仅为非零值添加标签
ax.text(i, cum_height + value/2, f'{item_idx}: {percentage:.1f}%',
ha='center', va='center', color='white', fontsize=10, fontweight='bold')
cum_height += value
# 移除图例
ax.legend().set_visible(False)
# 设置图表标题和轴标签
ax.set_title('Consumer Preferences by Time of Sale')
ax.set_xlabel('Time of Sale')
ax.set_ylabel('Quantity Sold')
ax.set_xticklabels(time_category_sales.index, rotation=0)
# 显示图表
plt.tight_layout()
plt.show()
time_item_name_pivot = pd.pivot_table(data, values='quantity',
index='time_of_sale',
columns='item_name',
aggfunc=np.sum,
fill_value=0)
# 创建不同时间段和菜品的消费组合的热图
plt.figure(figsize=(14, 8))
sns.heatmap(time_item_name_pivot, annot=True, fmt=".0f", linewidths=.5, cmap="YlGnBu")
plt.title("Sales Quantity Heatmap by Time of Sale and Item Name")
plt.ylabel("Time of Sale")
plt.xlabel("Item Name")
plt.show()
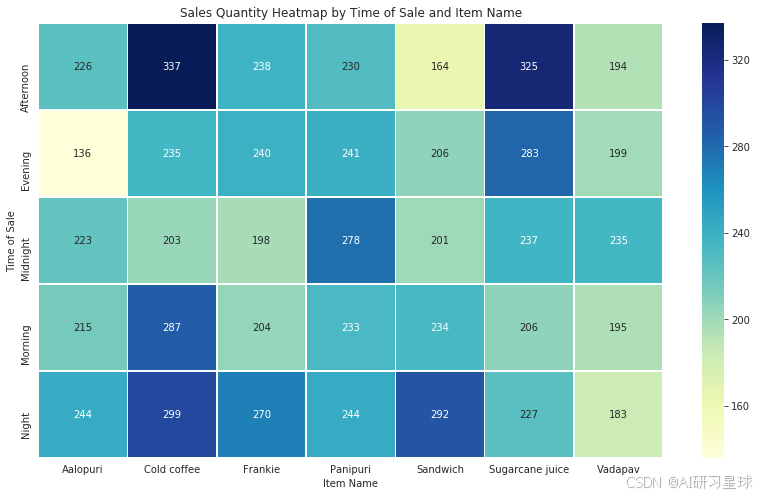
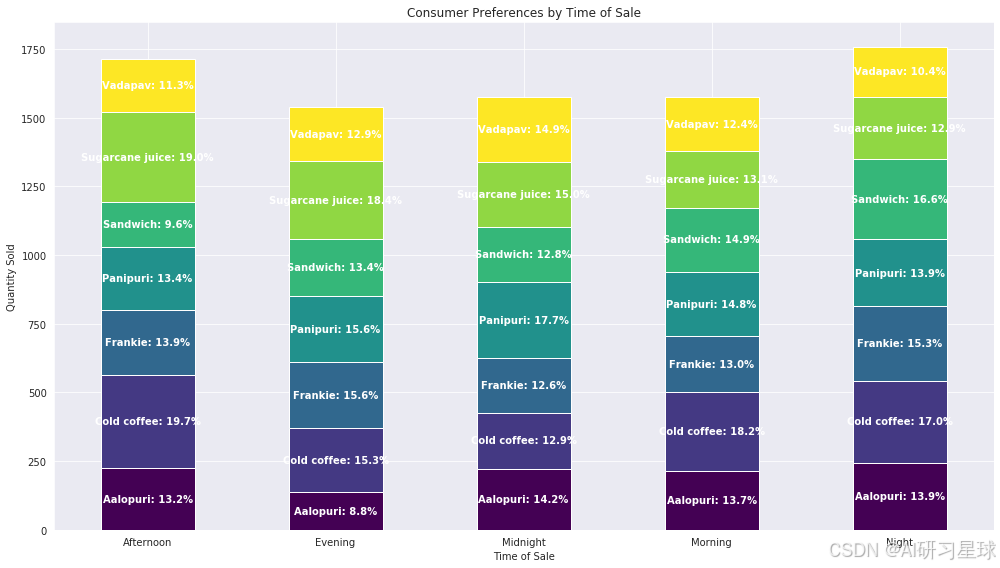
总结:
- 冷咖啡是一整天都相对比较受欢迎的饮品,尤其是在早上、下午和晚上销量较高,这可能与人们早晚需要提神的习惯有关。
- 三明治在早上和晚上的销售量很好,可以考虑将它作为早餐和晚餐的主推商品。
- 甘蔗汁在下午的销售量好,这可能与下午天气较热,人们需要解渴有关,但到了晚上,销量有所下降。
- Vadapav和Panipuri在午夜时段非常受欢迎,这可能是因为它们作为小吃在夜晚比较适合食用。
- Aalopuri的销售在晚上和午夜比较好,而在傍晚销售量最低。
建议:
- 早上应该准备充足的冷咖啡和三明治,因为它们是早餐时间的热销商品。
- 下午可以多备一些甘蔗汁,因为它在热天时是顾客的热门选择。
- 晚上到午夜时间段,应该重点准备好Vadapav和Panipuri,以满足夜晚消费者对小食的需求。
- Aalopuri作为一个在晚上和午夜销售良好的商品,也需要适量准备。
- 考虑到冷咖啡全天都有稳定的销量,应该确保全天都有充足的供应。
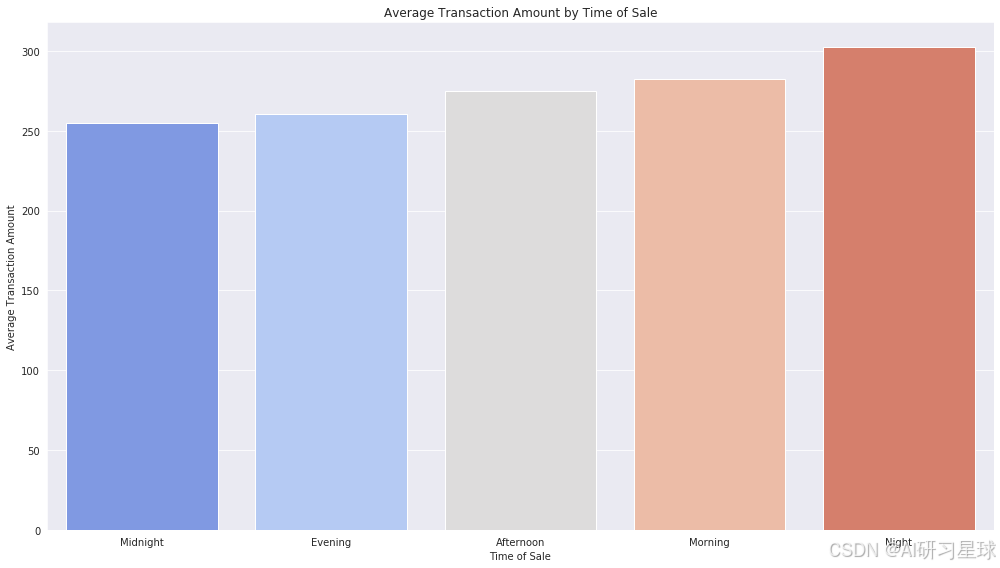
ii、销售额分析
# 计算每个时间段的平均交易金额
average_transaction_by_time = data.groupby('time_of_sale')['transaction_amount'].mean().sort_values()
# 绘制每个时间段的平均交易金额的条形图
plt.figure(figsize=(14, 8))
sns.barplot(x=average_transaction_by_time.index, y=average_transaction_by_time.values, palette="coolwarm")
plt.title("Average Transaction Amount by Time of Sale")
plt.ylabel("Average Transaction Amount")
plt.xlabel("Time of Sale")
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
time_item_sales = data.groupby(['time_of_sale', 'item_name'])['transaction_amount'].sum().unstack().fillna(0)
plt.figure(figsize=(14, 8))
sns.heatmap(time_item_sales, annot=True, fmt=".0f", linewidths=.5, cmap="BuPu")
plt.title('Sales Amount Heatmap by Time of Sale and Item Name')
plt.xlabel('Item Name')
plt.ylabel('Time of Sale')
plt.show()
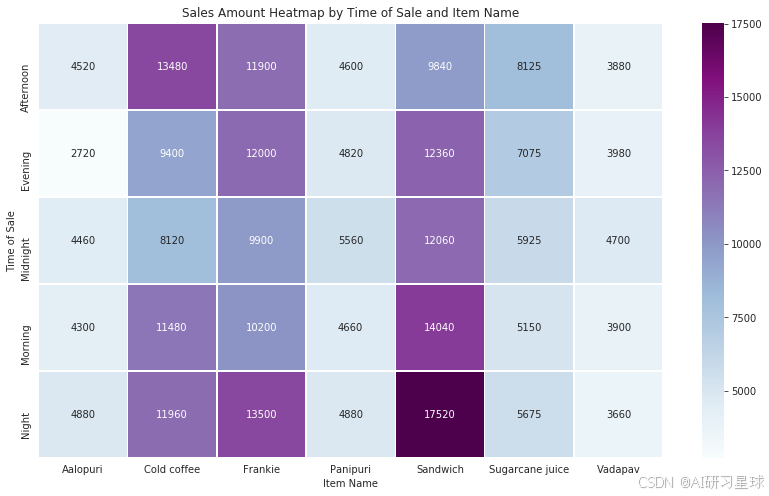
总结:
- 晚上和早上的销售平均销售金额比较高,夜间和午夜的平均交易金额相对较低。
- 三明治、冷咖啡和Frankie这三类商品的总体带来的销售额比较高,Panipuri和Vadapav只有在午夜带来的销售额才比较高。
- Aalopuri销售额在夜间的时候最低。
- 甘蔗汁在下午的时候销售额最高。
e、时间序列分析
i、根据销售额分析
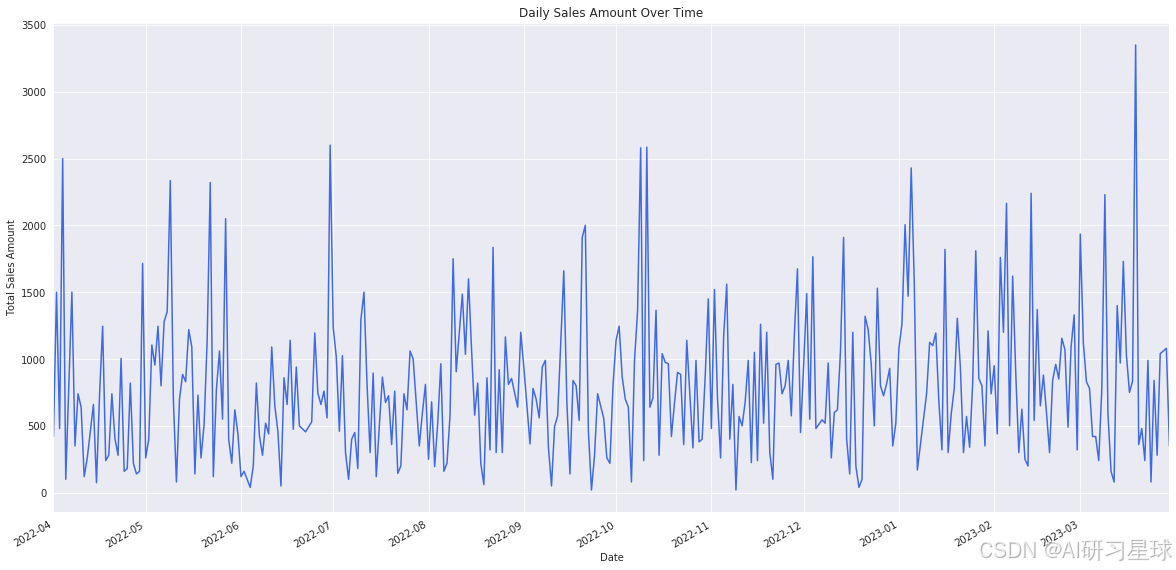
# 聚合数据以获取每天的总销售额
daily_sales = data.groupby('date')['transaction_amount'].sum()
# 创建时间序列图表
plt.figure(figsize=(20, 10))
daily_sales.plot(title='Daily Sales Amount Over Time', color='royalblue')
plt.xlabel('Date')
plt.ylabel('Total Sales Amount')
plt.show()
# 设置图表大小
plt.rcParams['figure.figsize'] = (20,15)
# 由于时间序列分解需要没有缺失值的完整序列,我们需要确保所有日期都有数据
# 为此,我们对缺失的日期进行填充,使用前一天的数据填充
daily_sales_complete = daily_sales.asfreq('D', method='ffill')
# 应用时间序列分解
result = seasonal_decompose(daily_sales_complete, model='additive')
# 绘制时间序列分解的结果
result.plot()
plt.show()
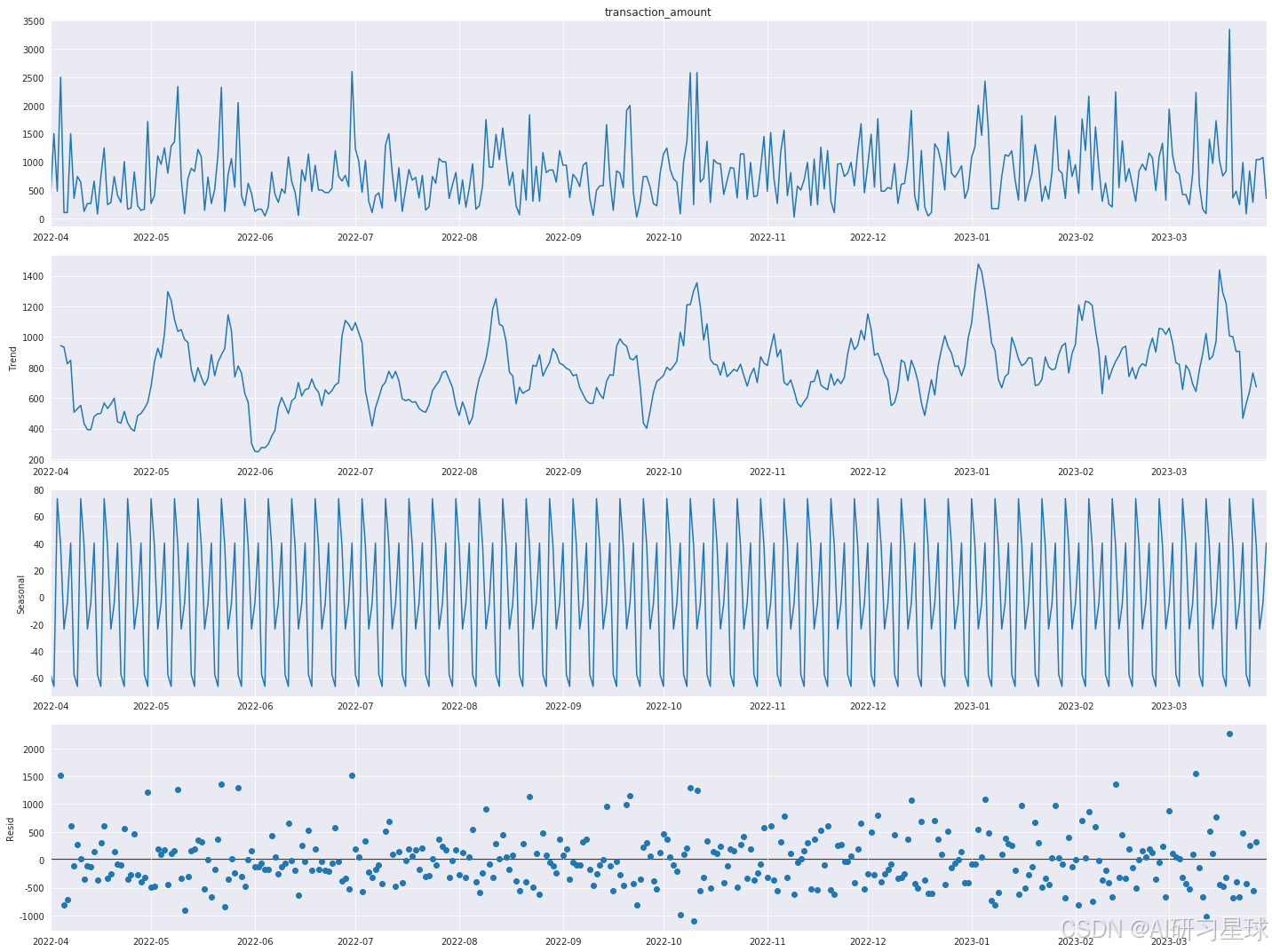
总结:
销售额数据确实表现出一定的季节性,尽管这个季节性模式在不同时间的影响程度不同。趋势部分显示了销售额随时间的整体变化,而残差则表现为随机波动,这些波动可能是由不规则因素如节假日促销、突发事件等引起的。
model = auto_arima(daily_sales_complete, seasonal=True, m=7, trace=True,error_action='ignore', suppress_warnings=True)
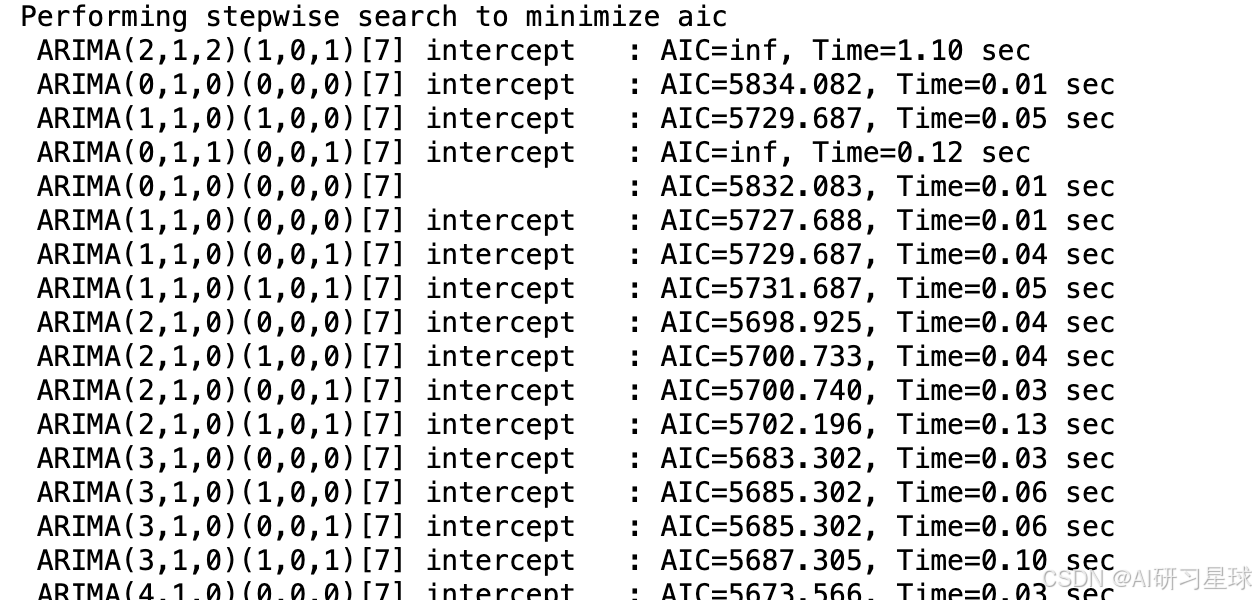
model.summary()
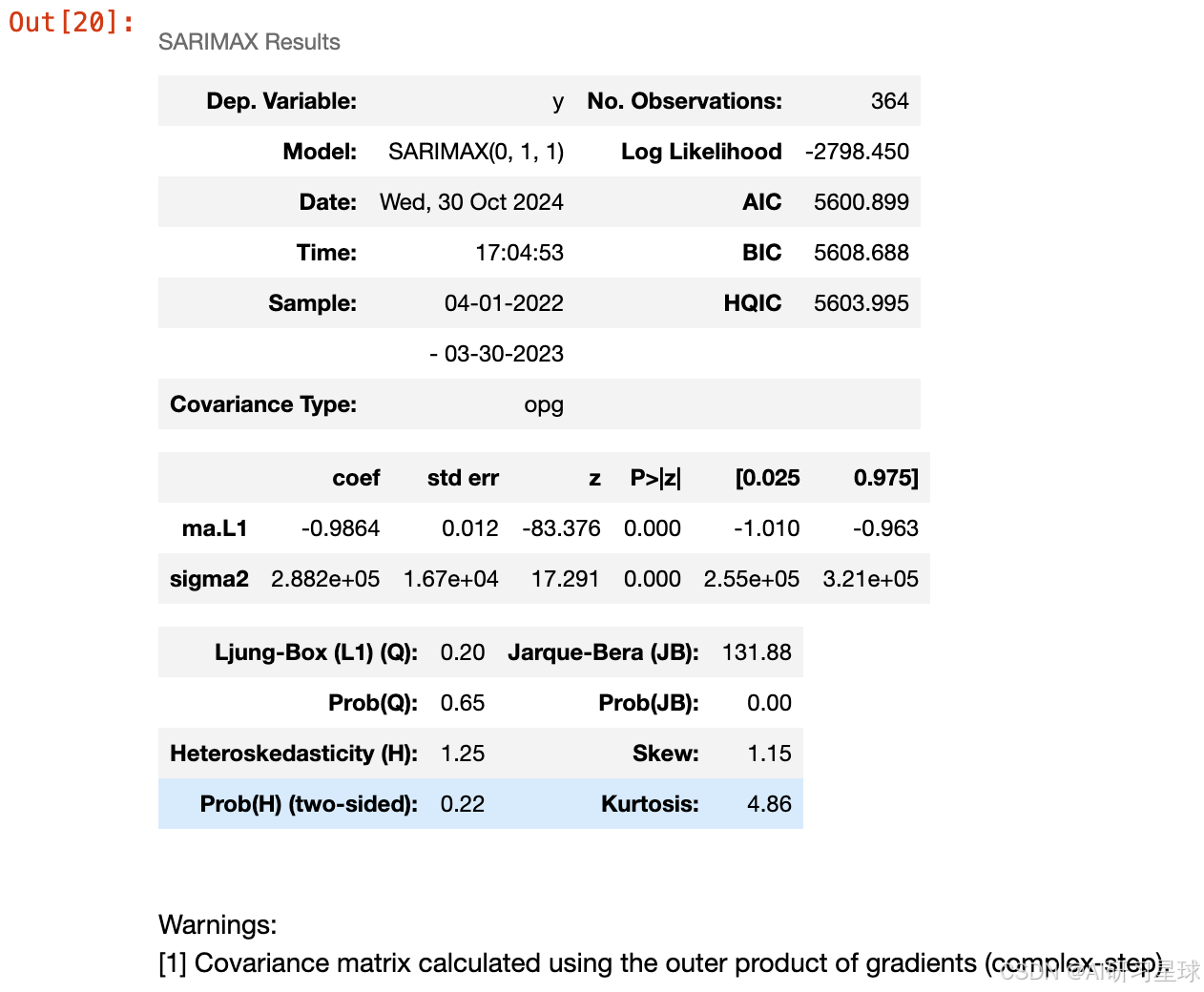
总结:
通过自动选择参数,这里选择了SARIMAX(2, 1, 2)模型,具有两个自回归项、一次差分和两个移动平均项。AIC:5599.808,BIC:5623.175。模型的结果显示一些参数在统计上显著,但残差分布的偏度和峰度表明分布可能偏离正态分布,模型没有表现出异方差性,这是积极的一面。
# 拟合模型
model.fit(daily_sales_complete)
forecast = model.predict(n_periods=30)
forecast

# 创建一个与预测值相对应的日期范围。这将取决于你的数据集的最后一个日期。
last_date = daily_sales_complete.index[-1]
forecast_dates = pd.date_range(start=last_date, periods=31, closed='right') # 获取30天的预测,不包括最后一个已知数据点的日期
# 将预测值转换为Pandas Series,并设置索引为未来日期
forecast_series = pd.Series(forecast, index=forecast_dates)
# 绘制原始数据
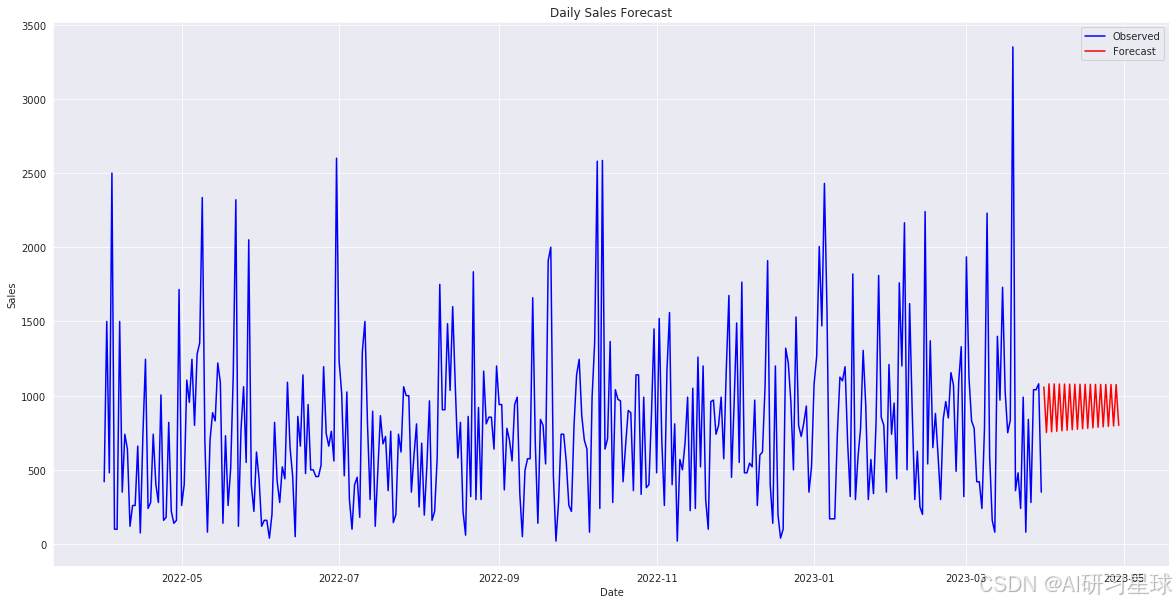
plt.figure(figsize=(20,10))
plt.plot(daily_sales_complete, label='Observed', color='blue')
# 绘制预测数据
plt.plot(forecast_series, label='Forecast', color='red')
# 设置图例和标签
plt.legend()
plt.title('Daily Sales Forecast')
plt.xlabel('Date')
plt.ylabel('Sales')
# 显示图形
plt.show()
ii、根据销售量分析
# 对数据进行按日期聚合,计算每天的总销售量
daily_quantities = data.groupby('date')['quantity'].sum()
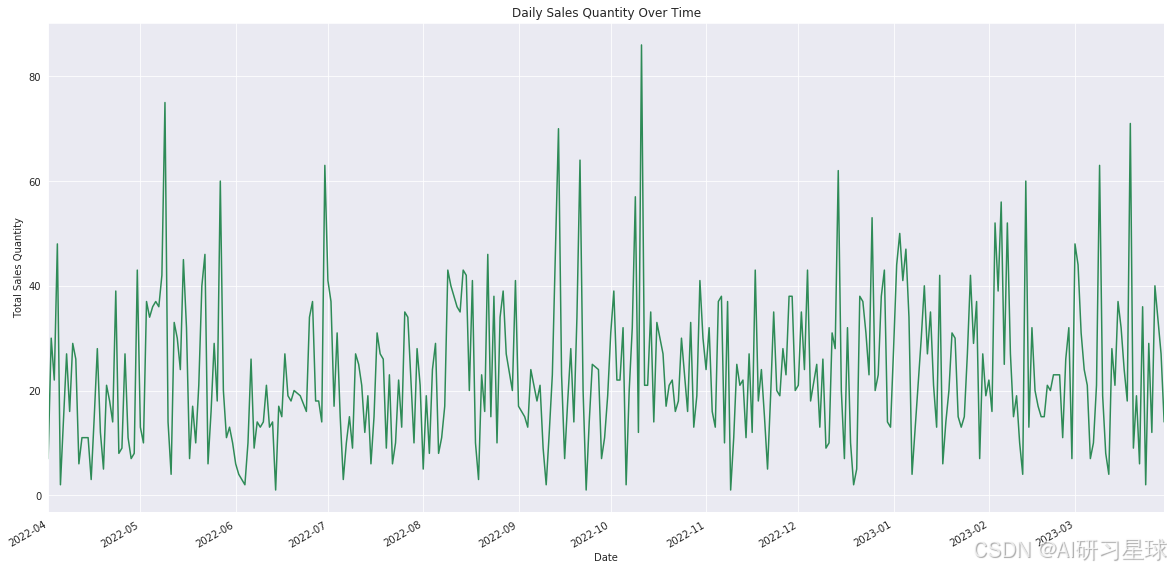
plt.figure(figsize=(20, 10))
daily_quantities.plot(title='Daily Sales Quantity Over Time', color='seagreen')
plt.xlabel('Date')
plt.ylabel('Total Sales Quantity')
plt.show()
# 保时间序列中没有缺失值。如果有缺失的日期,我们使用前一天的销售量数据进行填充
daily_quantities_complete = daily_quantities.asfreq('D', method='ffill')
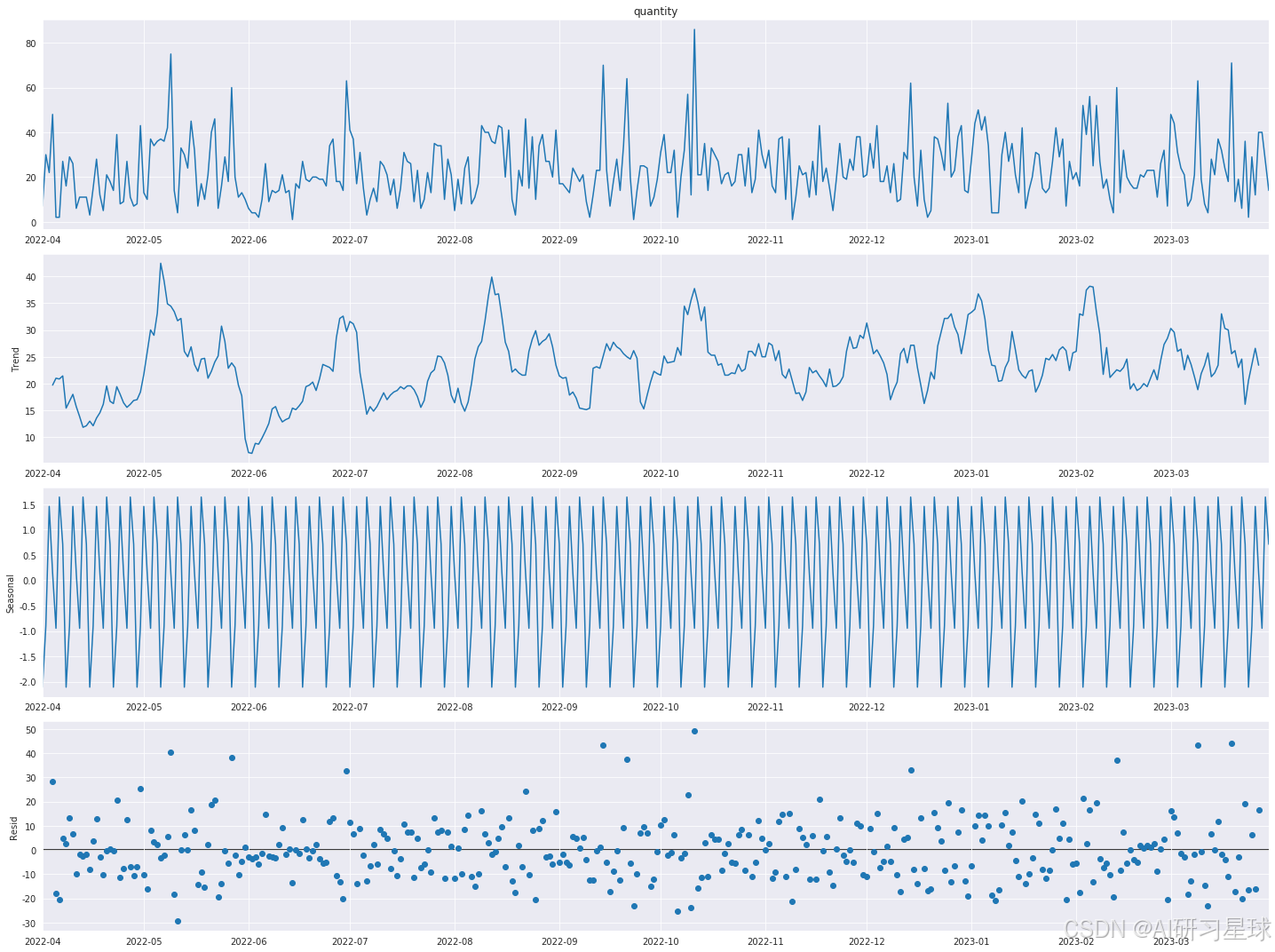
result_quantities = seasonal_decompose(daily_quantities_complete, model='additive')
result_quantities.plot()
plt.show()
总结:
我们可以看到销售量的趋势在不同时间点有所变化,这可能暗示了消费者行为的变化或市场环境的变化,销售量有明显的季节性,表明销售量受周期性因素的影响,残差主要在0周围波动,但是也存在一些特别的异常值,可能是一些特殊事件导致的销售量突增或减少。
model = auto_arima(daily_quantities_complete, seasonal=True, m=7, trace=True,error_action='ignore', suppress_warnings=True)
model.summary()
总结:
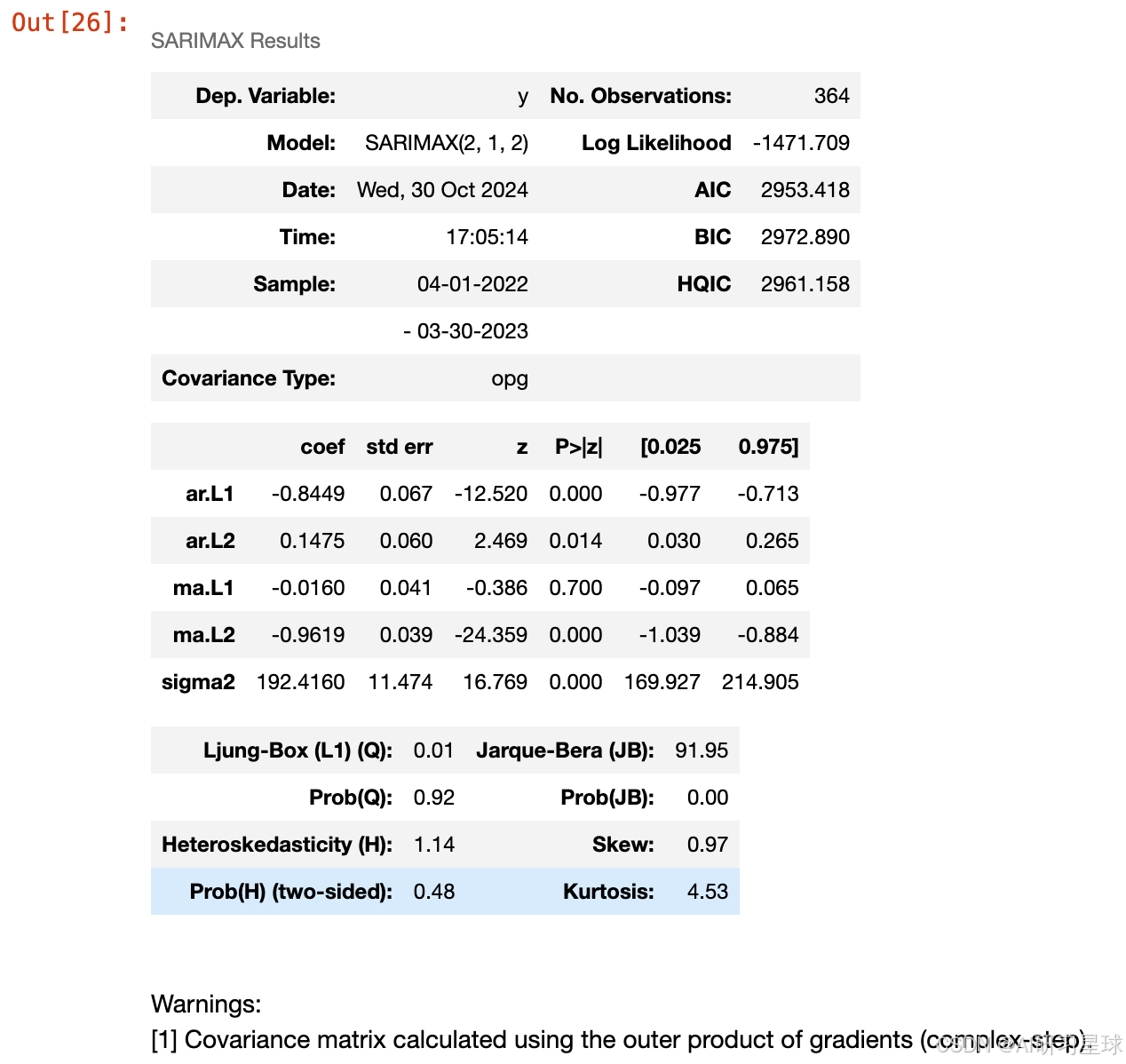
通过自动选择参数,这里选择了SARIMAX(2, 1, 2)x(0, 0, [1], 7)模型,其中AR部分为2,差分为1,MA部分为2;季节性模型部分(S)的参数为0,没有季节性差分(D),季节性MA为1,周期为7天,此时AIC:2951.906,BIC:2979.167,有些参数在统计上显著,而有些则不显著。模型的残差分布不符合正态分布的假设,可能是因为偏度或数据中的异常值导致的。然而,残差的自相关性检验表明,时间序列的自相关已被模型适当地捕捉。
# 拟合模型
model.fit(daily_quantities_complete)
forecast = model.predict(n_periods=30)
forecast
# 创建一个与预测值相对应的日期范围。这将取决于你的数据集的最后一个日期。
last_date = daily_quantities_complete.index[-1]
forecast_dates = pd.date_range(start=last_date, periods=31, closed='right') # 获取30天的预测,不包括最后一个已知数据点的日期
# 将预测值转换为Pandas Series,并设置索引为未来日期
forecast_series = pd.Series(forecast, index=forecast_dates)
# 绘制原始数据
plt.figure(figsize=(20,10))
plt.plot(daily_quantities_complete, label='Observed', color='blue')
# 绘制预测数据
plt.plot(forecast_series, label='Forecast', color='red')
# 设置图例和标签
plt.legend()
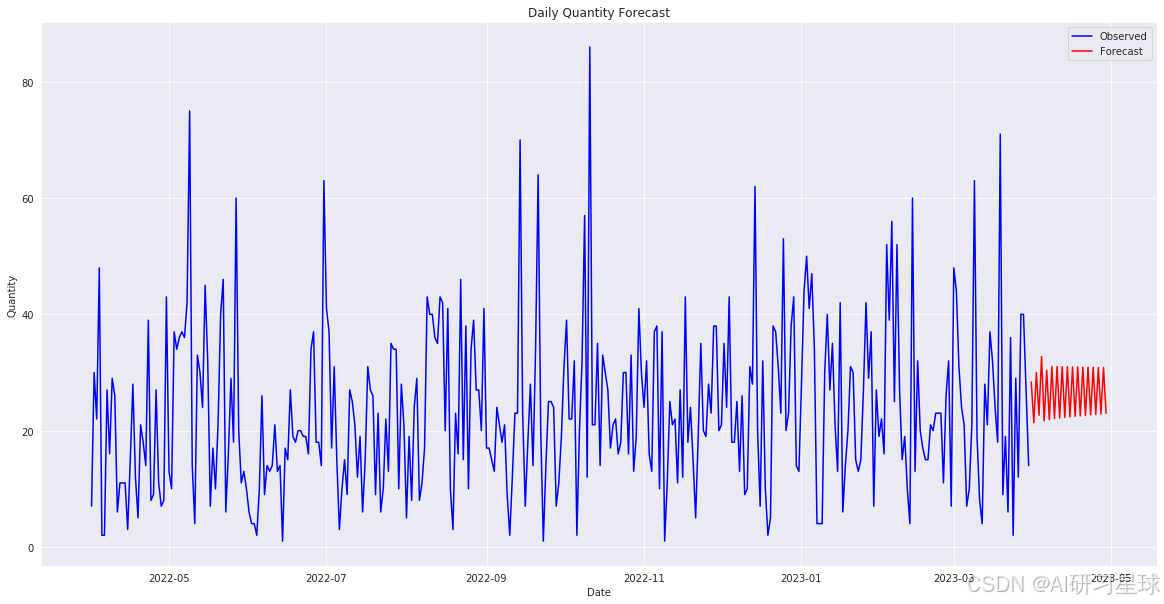
plt.title('Daily Quantity Forecast')
plt.xlabel('Date')
plt.ylabel('Quantity')
# 显示图形
plt.show()
f、总结
- 本项目主要采用了可视化分析,快餐是交易量最大的类别,表明快餐可能是该餐厅的主打产品,现金和在线支付是最常见的两种交易方式,其中现金比在线支付更多一点,其他支付方式的使用频率较低,男性服务员和女性服务员接待顾客的订单数量可能大致相等,显示出性别在工作分配上的均衡,下午和晚上的销售量高于其他时段,这可能与顾客的生活习惯或该餐厅的营业高峰时段有关,销售最多的商品是冷咖啡,最少的是三明治。
- 通过销售分析得出了冷咖啡是一整天都相对比较受欢迎的饮品,三明治在早上和晚上的销售量很好,甘蔗汁在下午的销售量好,到了晚上,销量有所下降,Vadapav和Panipuri在午夜时段非常受欢迎,Aalopuri的销售在晚上和午夜比较好。
- 晚上和早上的销售平均销售金额比较高,夜间和午夜的平均交易金额相对较低,三明治、冷咖啡和Frankie这三类商品的总体带来的销售额比较高,Panipuri和Vadapav只有在午夜带来的销售额才比较高,Aalopuri销售额在夜间的时候最低,甘蔗汁在下午的时候销售额最高。
- 最后进行时间序列分析,得出了销售额以及销售量均存在季节性(周期性),通过auto_arima构建了SARIMAX模型,预测了未来30天的销量以及销售额,有助于餐厅进行资源规划。
- 建议:早上应该准备充足的冷咖啡和三明治,因为它们是早餐时间的热销商品。下午可以多备一些甘蔗汁,因为它在热天时是顾客的热门选择。晚上到午夜时间段,应该重点准备好Vadapav和Panipuri,以满足夜晚消费者对小食的需求,Aalopuri作为一个在晚上和午夜销售良好的商品,也需要适量准备,考虑到冷咖啡全天都有稳定的销量,应该确保全天都有充足的供应,可以推出一些组合套餐,拉动一些低销量,但是高销售额的商品。
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











