







分类模型
分类模型的因变量是离散值,不同与回归模型的因变量为连续值,单单衡量预测值和因变量的相似度可能行不通。分类问题中,我们对于每个类别犯错的代价不尽相同。衡量分类模型的方式也与回归模型不同。为了解决这些问题,我们定义用于评估分类模型的指标。
我们使用一个 2x2 混淆矩阵来总结我们的模型,该矩阵描述了所有可能出现的结果(共四种)
- 真正例TP:是指模型将正类别样本正确地预测为正类别。
- 真负例TN:是指模型将负类别样本正确地预测为负类别。
- 假正例FP:是指模型将负类别样本错误地预测为正类别。
- 假负例FN:是指模型将正类别样本错误地预测为负类别。
用表格表示如下
| 实际P | 实际N | |
|---|---|---|
| 预测P | 真正例TP | 假正例FP |
| 预测N | 假负例FN | 真负例TN |
分类模型的指标:
准确率
准确率是一个用于评估分类模型的指标。准确率是指我们的模型预测正确的结果所占总样本的比例。
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy=\frac {TP+TN} {TP+TN+FP+FN}
Accuracy=TP+TN+FP+FNTP+TN
精确率
精确率是指在被预测为正类别的样本中,真正为正类别的比例。
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision=\frac {TP} {TP+FP}
Precision=TP+FPTP
召回率
召回率是在所有正类别样本中,被正确预测为正类别的比例。
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall=\frac {TP} {TP+FN}
Recall=TP+FNTP
F1值
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。我们将精确率和召回率组合成一个指标,称为F1值
F
1
=
2
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F1 =\frac{2\times Precision\times Recall}{Precision+ Recall}
F1=Precision+Recall2×Precision×Recall
ROC曲线
ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。该曲线绘制了以下两个参数:
- 真正例率(TPR)
真正例率是召回率的同义词,因此定义如下:
T P R = T P T P + F N TPR=\frac {TP} {TP+FN} TPR=TP+FNTP - 假正例率(FPR)
F
P
R
=
F
P
F
P
+
T
N
FPR=\frac {FP} {FP+TN}
FPR=FP+TNFP
ROC 曲线用于绘制采用不同分类阈值时的 TPR 与 FPR。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。下图显示了一个典型的 ROC 曲线
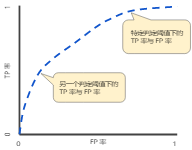
ROC 曲线下面积:测量从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个面积。
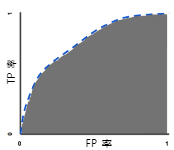
ROC曲线下面积对所有可能的分类阈值的效果进行综合衡量。
逻辑回归logistic regression
一种分类模型,将线性预测转化为概率表示,生成分类问题中每个可能的离散标签值的概率。逻辑回归经常用于二元分类问题,用来表示某件事情发生的可能性。线性回归中我们的值通常不在一个概率范围内[0,1]表示,那么有什么办法能转换为概率表示,确保输出值始终落在 0 和 1 之间。正好Sigmoid函数生成的输出值正好具有这些特性,其定义如下:
y
=
1
1
+
e
−
z
y=\frac {1} {1+e^{-z}}
y=1+e−z1
其中令
z
=
w
T
x
z=w^Tx
z=wTx 即表示线性函数,利用Sigmoid函数即可将线性结果转换到[0,1]区间。
基于概率的分类模型
- 线性判别分析:
线性判别分析是一个比较久远的算法,分别是基于贝叶斯公式和降维分类的思想。 - 朴素贝叶斯:
在线性判别分析中,我们假设每种分类类别下的特征遵循同一个协方差矩阵,每两个特征之间是存在协方差的,因此在线性判别分析中各种特征是不是独立的。但是,朴素贝叶斯算法对线性判别分析作进一步的模型简化,它将线性判别分析中的协方差矩阵中的协方差全部变成0,只保留各自特征的方差,也就是朴素贝叶斯假设各个特征之间是不相关的。在之前所看到的偏差-方差理论中,我们知道模型的简化可以带来方差的减少但是增加偏差,因此朴素贝叶斯也不例外,它比线性判别分析模型的方差小,偏差大。虽然简化了模型,实际中使用朴素贝叶斯的案例非常多,甚至多于线性判别分析,例如鼎鼎大名的新闻分类,垃圾邮件分类等。 - 决策树 :
与前面内容所讲的决策树回归大致是一样的,只是在回归问题中,选择分割点的标准是均方误差,但是在分类问题中,由于因变量是类别变量而不是连续变量,因此用均方误差显然不合适。那问题是用什么作为选择分割点的标准呢?我们先来分析具体的问题:
在回归树中,对一个给定的观测值,因变量的预测值取它所属的终端结点内训练集的平均因变量。与之相对应,对于分类树来说,给定一个观测值,因变量的预测值为它所属的终端结点内训练集的最常出现的类。分类树的构造过程与回归树也很类似,与回归树一样,分类树也是采用递归二叉分裂。但是在分类树中,均方误差无法作为确定分裂节点的准则,一个很自然的替代指标是分类错误率。
决策树分类算法的完整步骤:
a. 选择最优切分特征j以及该特征上的最优点s:
遍历特征j以及固定j后遍历切分点s,选择使得基尼系数或者交叉熵最小的(j,s)
b. 按照(j,s)分裂特征空间,每个区域内的类别为该区域内样本比例最多的类别。
c. 继续调用步骤1,2直到满足停止条件,就是每个区域的样本数小于等于5。
d. 将特征空间划分为J个不同的区域,生成分类树。 - 支持向量机SVM:
支持向量机SVM是20世纪90年代在计算机界发展起来的一种分类算法,在许多问题中都被证明有较好的效果,被认为是适应性最广的算法之一。
支持向量机的基本原理非常简单,我们的目标是找到一个分割平面将两个类别分开。通常来说,如果数据本身是线性可分的,那么事实上存在无数个这样的超平面。这是因为给定一个分割平面稍微上移下移或旋转这个超平面,只要不接触这些观测点,仍然可以将数据分开。一个很自然的想法就是找到最大间隔超平面,即找到一个分割平面距离最近的观测点最远。















 3102
3102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









