







pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是Python成为强大而高效的数据分析环境的重要因素之一
首先导入pandas
import pandas as pd
import numpy as np
pandas中采用Serise()方法处理一维数据,这里为了方便直接用np生成一维数组,index中可添加行索引值,要求长度与数据长度一致.
对象t有index,values,dtype等属性:
t = pd.Series(np.arange(5), index=list('abcde'))
print(t)
print('*'*10)
print(t.index)
print('*'*10)
print(t.values)
print('*'*10)
print(t.dtype)

对于二维数据,pandas中有DataFrame()方法可以使用.
在导入数据的过程中,pandas也提供了大量的导入方法.

这里为了方便,将构造一组简单的二维数据
info_list = [
{"name":"xiaogui", "age": 18, "gender": 1},
{"name":"xiaoa", "age": 18, "gender": 1, "Vname": "gsuixiao"},
{"name": "pig", "age": 20, "gender": 0, "Vname": "bidg"},
{"name":"xiaob", "age": 18, "gender": 1},
{"name":"xiaoc", "age": 18, "gender": 1, "Vname": "guidxiao"},
{"name": "pia", "age": 20, "gender": 0, "Vname": "bidg"},
{"name":"xiaogudi", "age": 18, "gender": 1},
{"name":"xiaogusi", "age": 18, "gender": 1, "Vname": "guixiaoasdf"},
{"name": "pivg", "age": 20, "gender": 0, "Vname": "bigs"},
{"name":"xiadogui", "age": 18, "gender": 1},
{"name":"xiaosgui", "age": 18, "gender": 1, "Vname": "guixsiao"},
{"name": "pivg", "age": 20, "gender": 0, "Vname": "bigsdfa"},
{"name":"xiaxogui", "age": 18, "gender": 1},
{"name":"xiadogui", "age": 18, "gender": 1, "Vname": "gusdfixiao"},
{"name": "pigs", "age": 20, "gender": 0, "Vname": "bigaqw"},
{"name":"xiaodgui", "age": 18, "gender": 1},
{"name":"xiaogfdgui", "age": 18, "gender": 1, "Vname": "cvbguixiao"},
{"name": "pigdf", "age": 20, "gender": 0, "Vname": "baig"},
{"name":"xiaogxui", "age": 18, "gender": 1},
{"name":"xiaogdui", "age": 18, "gender": 1, "Vname": "gnhguixiao"},
{"name": "pigsd", "age": 20, "gender": 0, "Vname": "bigyur"},
]
df = pd.DataFrame(info_list)
DataFrame的基础属性以及方法
形状
print(df.shape) # (21,4)
列数据类型
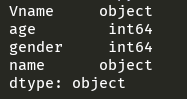
print(df.dtypes)
数据维度
print(df.ndim) # 2
行索引
print(df.index)

列索引
print(df.columns)

对象值,ndarray数组
print(df.values)

查看前n行,不加参数时默认为5
df.head(n)
查看最后n行,不加参数时默认为5
df.tail(n)
查看相关信息概览: 行数,列数,列索引,列非空个数,行类型,列类型,内存占用
print(df.info())

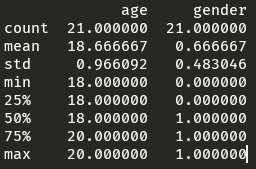
快速综合统计结果:技术,均值,标准差,最大值,四分位数,最小值
print(df.describe())
排序,默认ascending=True 升序
df = df.sort_values(by="age", ascending=False)
print(df)
pandas中优化了选择
t.loc[]
t.iloc[]
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape((3,4)), index=list('abc'), columns=list('wxyz'))
print(t.loc["a","w"])
# pandas中选择连续多行,比较特殊的是,选择是一个闭闭区间
# 结果是包含行索引值为"c"的那一行
print(t.loc["a":"c",["w","z"]])
# t.iloc根据位置选择
print(t.iloc[[0,2],[2,1]])
print(t.iloc[1:,2:])
数据缺失的处理
对于NaN的数据,在pandas中处理十分容易
判断数据是否为NaN: pd.isnull(df) pd.notnull(df)
处理方式1: 删除NaN所在的行列dropna(axis=0,how=‘any’,inplace=False)
处理方式2: 填充数据, t.fillna(t.mean()), t.fillna(t.median()), t.fillna(0)
处理为0的数据 t[t==0]=np.nan
pandas中计算平均值时,NaN不参与计算,但是0会















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









