







一:目标函数
- 训练损失和正则化项两部分
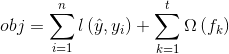
(1)L:代表损失函数,常见的损失函数
平方损失函数:
逻辑回归损失函数:
(2)y^ : xgboost是一个加法模型,因此预测得分是每棵树打分之和。
(3)正则项:k棵数的复杂度之和。 - 第t棵树
第t次迭代驯练的模型是ft(x) - 泰勒展开式
x 对应前t-1棵数,^x相当于第t棵树。
定义损失函数关于y’(t-1)的一阶偏导数 gi 和二阶偏导数hi
去掉全部常数项,得到目标函数 - 定义一棵树
q代表一棵树的结构,q(x)代表样本落到哪个叶子结点。 - 定义树的复杂度
由叶子结点的个数 和 叶子结点权重向量的L2范数 - 叶子结点归组
Gj :叶子结点j 所包含样本的 一阶偏导数 累加之和,是常量
Hj :叶子结点j 所包含样本的 二阶偏导数 累加之和,是常量 - 求解树结构权重及其最优obj的目标值
- :树的分裂细节
1.是否会带来信息增益选择是否分裂
Gain=Obj(L+R)-(Obj(L)-Obj®>0
2.寻找最佳分裂点
特征预排序+缓存:
XGBoost在训练之前,预先对每个特征按照特征值大小进行排序,然后保存为block结构,后面的迭代中会重复地使用这个结构,使计算量大大减小。
3.停止生长:
(1)Gain<0
(2) 达到最大深度
(3)叶子结点的样本权重小于某个阈值
Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









