






计算每一个类的准确度:
做实验要计算每一个类的acc,我当时想去调用方法,找到了答案,搬运如下:
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
matrix = confusion_matrix(y_true, y_pred)
matrix.diagonal()/matrix.sum(axis=1)
混淆矩阵二分类,TP,FP,TN,FN。看不懂。
假设一个13个动物的样本,8只猫和5只狗,那混淆矩阵的结果可能如下表所示:
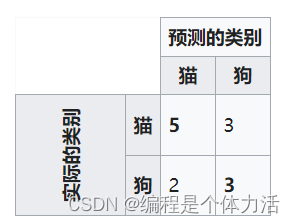
混淆矩阵:对角线上的是找对的,其他位置是找错的。给我两岁弟弟八张猫的图片,让我两岁弟弟认,他认出来五张是猫,包另外三张当成狗。
那么找对了多少个样本:(5+3)/13
那么找对了多少个猫:5/8















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









