







我的transformer学习笔记:
-
transformer 总体架构图:
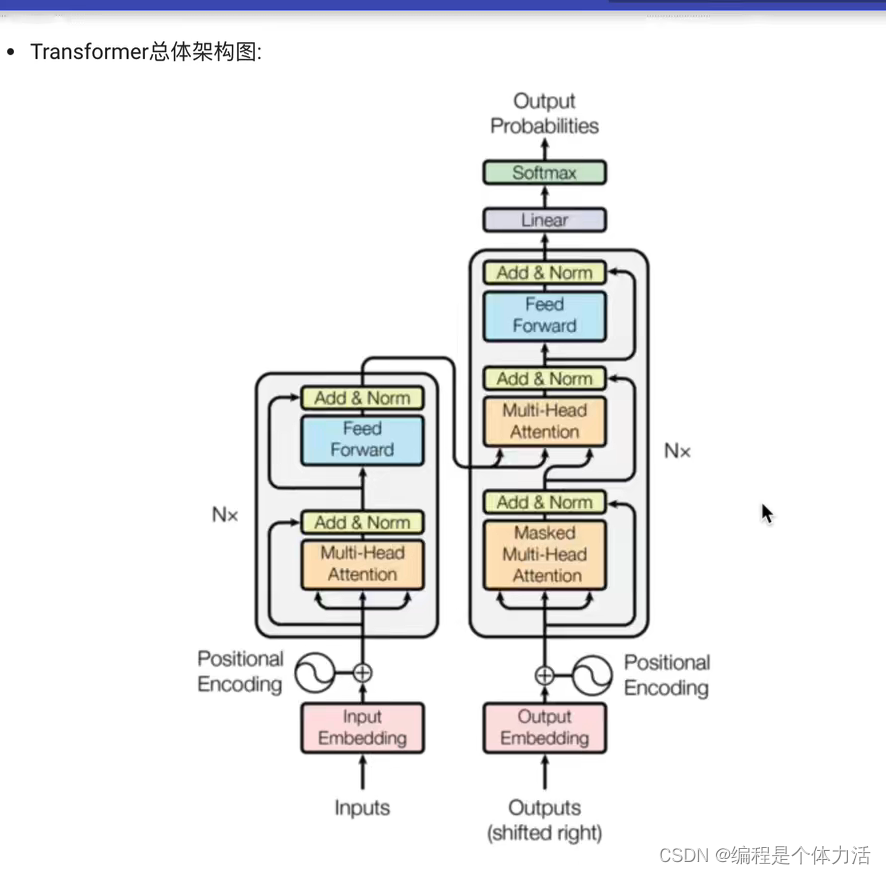
-
transformer的作用:
transformer 是可以用于自然语言处理的强有力的工具。基于seq2seq架构的transformer模型可以完成nlp领域的典型任务,如机器翻译,文本生成,同时又可以构建预训练的语言模型(这个应用还是比较广泛的),用于不同任务的迁移学习。
transformer 主要分为四部分:1.输入部分 2. 输出部分 3. 编码器 4. 解码器
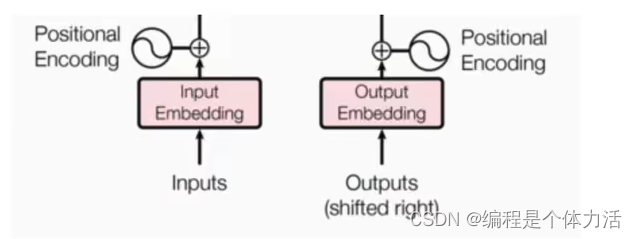
输入部分:原文本的嵌入层(input embedding)及其位置编码器(positional encoding),目标文本的嵌入层及其位置编码器
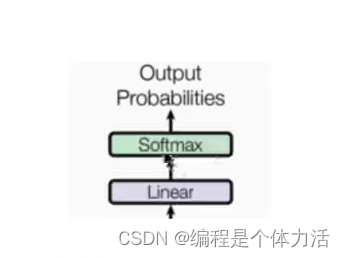
输出部分:线性层(为了得到我们最后的output size)和softmax层
编码器部分:
- 由N个编码器堆叠而成,编码器旁边有一个N表示总共有N个编码器
- 每个编码器有两个子层链接组成
- 第一个子层有一个多头自注意力机制子层和一个规范化层以及一个残差连接组成
- 第二个子层由一个前馈全连接子层和一个规范化层以及一个残差连接组成

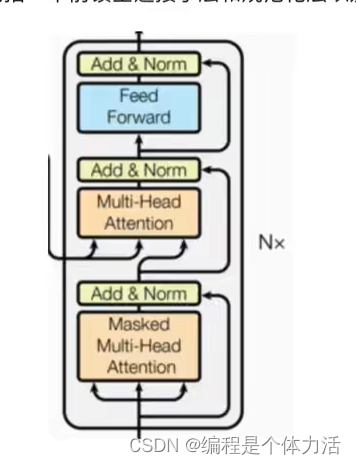
解码器部分:
- 由N个解码器堆叠而成,编码器旁边有一个N表示总共有N个编码器
- 每个编码器有三个子层链接组成
- 第一个子层有一个掩码多头自注意力机制子层和一个规范化层以及一个残差连接组成
- 一个多头注意力机制子层和一个规范化层以及一个残差连接组成
- 第二个子层由一个前馈全连接子层和一个规范化层以及一个残差连接组成
-
输入部分的实现:
输入部分:原文本的嵌入层及其位置编码器,目标文本的嵌入层及其位置编码器
文本嵌入层的作用:将文本的词汇转换为向量表示
需要的工具包:pytorch,numpy,matplotlib,seaborn
文本嵌入层的代码实现:
import torch
# 封装好的一些常用的层
import torch.nn as nn
# 数学计算工具包
import math
# torch 中的变量封装函数Variable
from torch.autograd import Variable
"""
词嵌入逻辑思路:
1.使用nn.Embedding(词表大小,词嵌入维度)
2.对词嵌入维度放缩
"""
#定义embeddings 类来实现文本嵌入层,s代表两个一摸一样的嵌入层,他们共享参数
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
'''
类初始化,两个参数
d_model:词嵌入的维度
vocab:词表的大小,例子如果是英文,那么vocab的大小是英文的总词数
'''
# 使用super()继承nn.moudle的初始化函数,找到embedding的父类,并调用它的初始化方法
super(Embeddings, self).__init__()
# 调用nn预定义层的embedding,获得一个词嵌入对象self.lut
self.lut = nn.Embedding(vocab, d_model)
# 最后将d_model传入类中
self.d_model = d_model
def forward(self, x):
'''
所有定义的对象依照定义的顺序依次执行
'''
return self.lut(x) * math.sqrt(self.d_model)















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









