







Optimization Methods and Regularization
- Extension to SGD: Momentum & Nesterov acceleration
- Momentum:通俗来讲——想想你童年最喜欢的游乐场,在那里你花了几天时间从山上滚下来,把自己盖在草地和泥土上(这让你妈妈很懊恼)。当你下山时,你会积累越来越多的动力,而这些动力反过来又会带你更快地下山。
原始权重更新公式
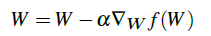
添加了动量项的V的权重更新公式

- Nesterov acceleration: 通俗的讲——假设你回到童年的游乐场,从山上滚下来。你已经蓄势待发,而且进展很快——但有一个问题。在山脚下是你学校的砖墙,你想要避免全速撞上它
同样的思想也适用于SGD。如果我们建立了太多的动力,我们可能会超过当地的最低限度,并继续前进。因此,有一个更聪明的滚动将是有利的,一个知道什么时候减速,这就是Nesterov
可以将Nesterov理解为动量的修正更新,可以获的更新后参数的大致位置

使用标准动量法,计算出梯度(蓝色小向量),并且在梯度方向进行一个大的跳跃(蓝色大向量);利用Nesterov加速在之前的梯度方向上进行一个大跳跃(棕色大向量),测量梯度,然后进行一个修正(红色向量)-绿色向量为最终的修正后的 - Regulariztion:不完全拟合/过度拟合/泛化
正则化技术的类型:
- 直接更新损失函数,增加额外项来约束模型
- 显式地将正则化类型添加到网络体系结构中:dropout
- 隐式的正则化形式应用于训练过程
Updating Loss and Weight Update to Include Regularization
对于添加正则项的理解
Convolutional Neural Networks
网络中至少有一层全连接层
In the context of image classification , CNN may learn to :
- Detect edges from raw pixel data in the first layer
- use these edges to detect shape in the second layer
- use these shape to detect higher-level features such as facial structures,parts of car,
CNN的两个优点: local invariance 局部不变性和compositionality
就深度学习而言,图像的卷积是两个矩阵按元素相乘然后求和
think of an image as big matirx and a kernel or convolutional matrix as a tiny matrix that is use for blurring
- Kernels

kernels可以使任意大小的矩阵M*N, 但是M和N必须是奇数

CNN:are arranged in a 3D wolume in three dimensions: width ,height ,and depth - Layer Types
- Convolutional(CONV)
- Activation(ACT or RELU,)
- Pooling(POOL)
- Fully - connected(FC)
- Batch normalization
- Dropout(DO)
CONV
将这些层堆叠:INPUT => CONV => RELU => FC => SOFTMAX
CNNs的三个参数用于控制输入的维度:depth stride zero-padding size
- Depth: 控制卷积层连接输入图像的局部神经元个数,每一个过滤器都会形成一个激活映射
- Stride:filter 的滑动步长s=1;s=2

- padding==((W-F+2P)/S)+1
padding用于保持卷积后的矩阵维度

CNN参数结构

Activation Layer
常用的非线性激活函数:RELU 、ELU、leaky ReLU
激活层并不是名义上的“layer”(因为在激活层中并没有学习相应的参数和权重)有时在网络结构中会被省略,假设跟在卷积后
Pooling layers
减少输入卷尺寸的两种方法:
- CONV layers with stride >1
- Pooling layers: max / average
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC
input : Winput *Hinput *Dinput
1:field sIze F
2: stride S
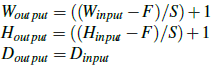
两种pooling:overlapping& non-overlapping pooling

Fully-connected layers
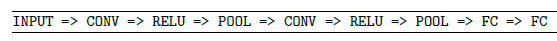
对于图像分类问题中FC后跟一个softmax
Batch Normalization
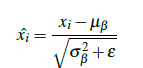
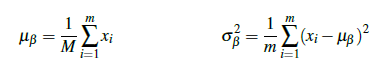
批处理的位置放在relu之前或之后
Dropout
dropout 是一种正则化的形式
常见的CNN结构模式:
INPUT => [[CONV => RELU]*N => POOL?]*M => [FC => RELU]*K => FC
Here the * operator implies one or more and the ? indicates an optional operation.
Common choices for each reputation include:
常见模式

- INPUT => CONV => RELU => FC
- **AlexNet-like:**INPUT => [CONV => RELU => POOL] * 2 => [CONV => RELU] * 3 => POOL =>[FC => RELU => DO] * 2 => SOFTMAX
- **VGGNet:**INPUT => [CONV => RELU] * 2 => POOL => [CONV => RELU] * 2 => POOL =>[CONV => RELU] * 3 => POOL => [CONV => RELU] * 3 => POOL =>
[FC => RELU => DO] * 2 => SOFTMAX
在应用池层之前叠加多个CONV层允许CONV层在执行破坏性池操作之前开发更复杂的特性;还可以移除FC层
Rules of Thumb
搭建你自己的CONV的经验法则:
-
input layer : the images are square
Common input layer sizes include 32×32 64×64 , 96×96 , 224×224 , 227×227 and 229×229 -
在应用卷积操作后,输入层应该被2倍整除
-
对输入图像添加zero-padding使得CONV的输出维度和输入图像维度一致
-
对于添加了批处理的操作:将归一化放在激活函数之后
















 4622
4622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









