






FaceShifter:朝向高保真度和遮挡感知的人脸交换
介绍
两阶段框架,主题不可知,一旦训练好,该模型就可以应用于任何新的人脸对,而不需要进行特定于受试者的训练。
第一阶段:基于GAN的网络,称为自适应嵌入集成网络(AEI-Net),用于对目标属性进行彻底和自适应地集成(1)提出一种用于提取多级目标人脸属性的新型属性编码器,用于提取各种空间分辨率的目标属性 ,而不是将其压缩成单个向量RSGAN、IPGAN(2)一种自适应注意去规范化(AAD)层的新型生成器,自适应地学习在哪里集成属性或身份嵌入。可以解决照明和面部形状不一致的问题
第二阶段:由一个新的启发式错误识别精化网络(HEAR-Net)组成,以自我监督的方式恢复异常区域,而无需任何手动注释。将目标和源相同的人脸图像输入到经过良好训练的AEI-Net中时,重建的人脸图像在多个区域偏离输入,这些偏差强烈暗示了人脸遮挡的位置。也就是在没有任何手动注释的情况下以自我监督的方式找到遮挡。
主要难点:提取和自适应重组两幅图像的身份和属性
先前的方法仅使用来自目的图像的姿势和表情指导来合成交换的面部,然后使用目标面部的遮罩将面部混合到目标图像中。但是很容易造成伪影FaceSwap
(1)在合成交换人脸时,除了姿势和表情外,几乎没有利用关于目标图像的知识,很难尊重场景亮度或图像分辨率等目标属性
(2)丢弃位于目标面罩外部的源面罩的所有外围区域
主题不可知的人脸交换研究
RSGAN分别提取人脸和头发区域的矢量化嵌入,并对它们进行重组以合成交换的人脸。
FSNet将源图像的面部区域表示为向量,将其与非面部目标图像组合以生成交换的面部。
IPGAN将人脸的身份和属性分解为向量。通过引入直接来自源身份和目标图像的监督,IPGAN支持具有更好身份保护的人脸交换。
方法
AEI-Net
需要两个输入图像,源图像提供身份,目标图像提供属性,例如姿势、表情、场景照明和背景
在第一阶段,使用AELNet生成基于信息集成的高保真度人脸交换结果。在第二阶段使用HEARNet处理面部遮挡并细化结果
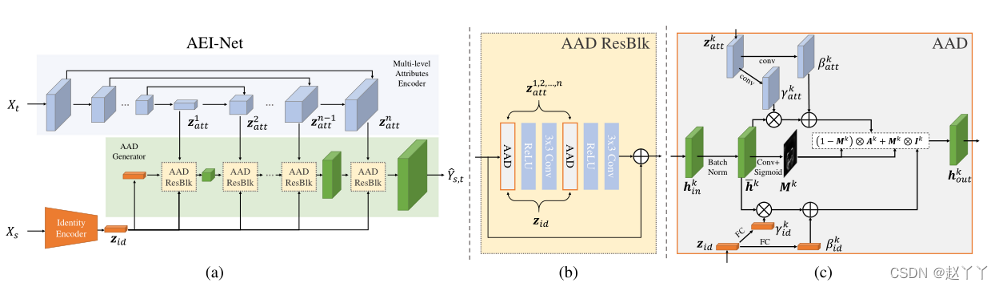
身份编码器,从源图像中提取身份信息
使用Arcface人脸识别模型作为身份编码器,身份嵌入Zid(Xs)被定义为在最终FC层之前生成的最后一个特征向量
多级属性编码器Zatt(Xt)提取目标图像Xt的属性
将嵌入的属性表示为多级特征图,而不是将其压缩成单个向量,将Xt馈送到U-Net-like结构中,然后将属性嵌入定位为从U-Net解码器生成的特征图。
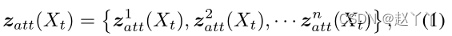
其中zkatt(Xt)表示来自U-Net解码器的第k级特征图,n是特征级的数量。
属性嵌入网络不需要任何属性注释,使用自我监督训练来提取属性。
AAD生成器,生成交换的面部图像
将两个嵌入Zid(Xs)和Zatt(Xt)进行积分,生成原始交换面,利用非规范化进行多个特征级别的特征集成
在第K个特征级别中,让hkin表示输入AAD层的激活图,大小为Ck×Hk×Wk的3D张量,Ck是通道的数量,Hk×W k是空间维度,在集成之前,我们对hkin执行批量规范化
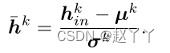
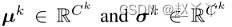
是hkin小批量内通道激活的平均值和标准偏差,提出三个并行的分支来自hk,(1)属性整合(2)身份整合(3)自适应注意力掩码
对于属性嵌入集成,zkatt是该特征级别上的属性嵌入,大小为
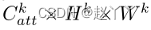
的3D张量,我们通过根据属性嵌入对归一化的Hk进行反规范化来计算属性激活Ak
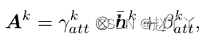
其中γkatt和βkatt是两个调制参数,都是由zkatt卷积得到的。它们与hk具有相同的张量维度。将计算出的γkatt和βkatt相乘并添加到“hk元素”中
对于身份嵌入集成,让zkid是身份嵌入,它应该是大小为Cid的1D向量。我们还以类似于集成属性的方式,通过计算身份激活Ik来集成zkid。
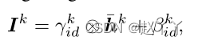
其中γkid∈RCk和βkid≠RCk是zid通过FC层生成的另外两个调制参数。
AAD层的一个关键设计是自适应地调整身份嵌入和属性嵌入的有效区域,使它们能够参与合成人脸的不同部分。例如,对于身份嵌入更侧重于合成对区分身份最具鉴别力的面部部分,眼睛、嘴巴、面部轮廓。所以,在AAD层采用了一种注意力机制。使用hk通过卷积和激活生成注意力掩膜Mk,Mk的值在0和1之间。
最后,AAD层的输出可以由AK和Ik获得,有掩码Mk加权
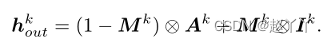
使用多个AAD层构建AAD生成器,从源Xs中提取身份嵌入zid和从目标Xt中提取属性嵌入zatt后,我们级联AAD残差块(AAD-ResBlks)以生成交换的面。对于第k个特征级别上的AAD ResBlk,它首先将上一个级别的上采样激活作为输入,然后将该输入与zid和zkatt集成。从最后一次激活开始卷积最终输出图像。
训练损失
AEI-Net的可训练模块包括多级属性编码器和ADD生成器。
对AEINet进行对抗性训练,实现在多尺度鉴别上,身份保全损失用来保全来源的身份,余弦相似性
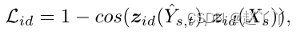
属性损失多级属性嵌入之间的L2距离
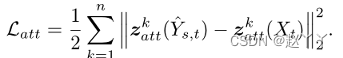
重建损失当训练样本中的源图像和目标图像相同时,像素级L2距离
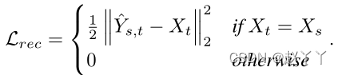
总损失
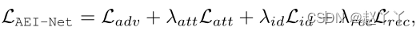
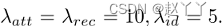
HEAE-Net
可以利用重建图像与其输入之间的误差来定位面部遮挡。我们称之为输入图像的启发式误差,因为它启发式地指示异常发生的位置。
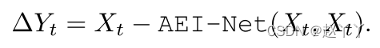
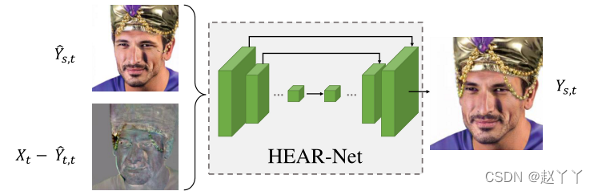
将启发式误差∆Yt和第一阶段的结果馈送到U-Net结构中,并获得精细图像Ys,t:
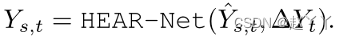
训练损失
变化损失:保证第一阶段和第二阶段结果的一致性
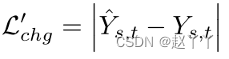 重建损失限制第二阶段源和目标图像相同
重建损失限制第二阶段源和目标图像相同
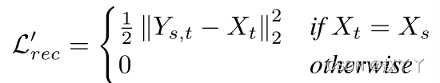
总损失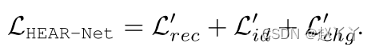
有遮挡的数据是有限的,所以合成遮挡,遮挡的部分从各种数据集随机采样,包括EgoHands、GTEA Hand2K和ShapeNet。经过随机旋转、重新缩放和颜色匹配后,它们会混合到现有的人脸图像上
实验
实验细节
首先提取五点地标HEAR-Net中的下采样/上采样数设置为5。对人脸进行对齐和裁剪,大小为256*256,覆盖整个人脸以及一些背景区域。AEI-Net中的属性嵌入的数量被设置为n=8。
AEI-Net使用CelebA HQ、FFHQ和VGGFace进行训练。而HEAR-Net仅使用在这些数据集中具有Top-10%启发式错误的一部分人脸进行训练,并使用合成遮挡的额外增强。遮挡图像是从EgoHands、GTEA Hand2K和ShapeNet的对象渲染中随机采样的。
定性比较

结果更好地保留了源身份的人脸形状,也更忠实于目标属性(如照明、图像分辨率)。其余方法都遵从先合成内部人脸区域,然后将其混合到目标人脸中的策略,正如预期的那样,它们存在混合不一致的问题。这些方法生成的所有面与其目标面共享完全相同的面轮廓,并忽略源面形状(图5第1-4行,图6第1-2行)。此外,他们的结果不能很好地尊重目标图像的关键信息,如照明(图5第3行,图6第3-5行)、图像分辨率(图5的第2行和第4行)。IPGAN[5]由于其单层属性表示,在所有样本中的分辨率都有所下降。IPGAN不能很好地保留目标面部的表情,例如闭着的眼睛(图5第2行)。

保留源的面部形状,目的的照明和图像分辨率。也有能力超越FSGAN来处理遮挡。
定量比较
对于FaceSwap和DeepFakes,测试集由每种方法的10K张人脸图像组成,通过从每个视频剪辑中均匀采样10帧。对于IPGAN、Nirkin等人和我们的方法,使用与其他方法相同的源和目标图像对生成10K人脸图像。然后,我们对三个指标进行了定量比较:身份检索、姿势误差和表情误差。
我们使用不同的人脸识别模型提取身份向量,并采用余弦相似度来测量身份距离
Cosface:Large margin cosine loss for deep face recognition.
使用姿势估计器来估计头部姿势,Fine grained head pose estimation without keypoints.
使用3D人脸模型来检索表情向量。Joint face detection and facial motion retargeting for multiple faces.
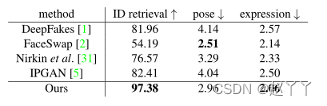
交换的面部与其目标面部之间的姿势和表情向量的L-2距离作为姿势和表情误差。
没有像fsgan(2D地标之间的欧几里得距离)那样使用人脸地标比较,人脸地标涉及身份信息,在交换的面部和目标面部应该是不一致的。
消融实验
注意掩码进行自适应整合
为了验证使用注意掩码进行自适应整合的必要性,将AEI-Net与两个基线模型进行比较:
(1)在AAD层采用元素加运算

(2)逐元素级联
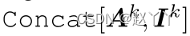

基线模型生成的人脸相对模糊,并且包含大量重影伪影。
不同级别AAD层掩码

可视化了不同级别上的AAD层的掩码Mk,其中较亮的像素表示等式5中身份嵌入的权重较高。结果表明,身份嵌入在低层中具有更大的效果。它的有效区域在中间层次变得更稀疏,只在与面部身份密切相关的一些关键区域激活,例如眼睛、嘴巴和面部轮廓的位置。
多层属性
多级属性:将其与另一个名为Compressed的基线模型进行了比较,该模型与AEI-Net共享相同的网络结构,但仅使用前三级嵌入zkatt,k=1,2,3。它的最后一个嵌入z3att被馈送到所有更高级别的AAD集成中。目标图像中的许多属性信息丢失,其结果会受到模糊等伪影的影响。

为了理解属性嵌入中编码的内容,我们将来自所有级别的嵌入zkatt(二进制上采样到256×256并向量化)连接为统一的属性表示。我们进行主成分分析以将向量维度减少为512。然后,我们使用这些向量的最近L-2距离执行从训练集中查询人脸的测试。即属性嵌入可以很好地反映面部属性,如头部姿势、头发颜色、表情,甚至是脸上的眼镜。
细化结果

第二阶段的细化结果表明,HEAR-Net对各种误差具有很强的适应性,包括遮挡、反射、轻微偏移的姿态和颜色等。
网络结构
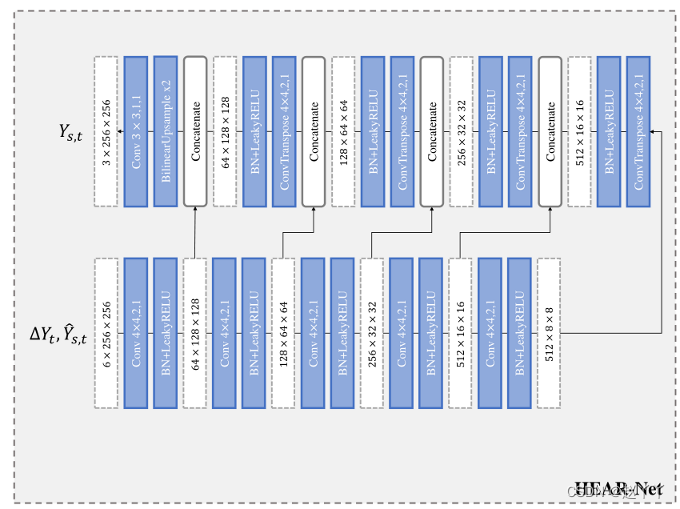
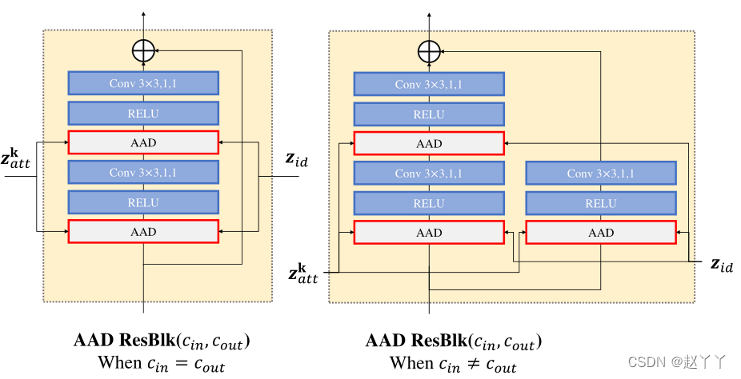
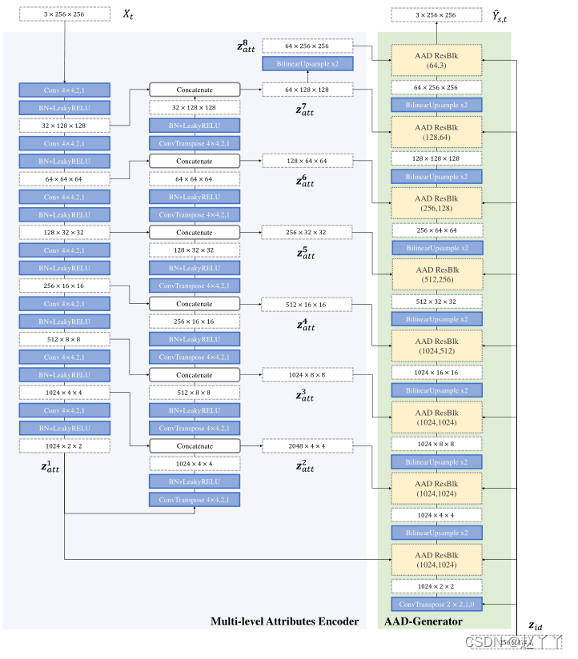
卷积k,s,p表示具有核大小k、步长s和填充p的卷积层。ConvTranspose k,s,p表示具有核大小k、步长s和填充p的转置卷积层。所有LeakyReLUs
AAD ResBlk(cin,cout)表示具有cin和cout的输入和输出通道的AAD ResBlk。
在AEI-Net中,我们使用Semantic image synthesis with spatially-adaptive normalization. 多尺度鉴别器,将对抗性损失实现为铰链损失。当训练AEI-Net时,训练样本Xt!=Xs的比率是80%,训练HEAR-Net时,训练样本Xt!=Xs的比率是50%。adam优化器β1=0,β2=0.999,lr=0.0004用于训练所有网络。
AEI-Net以500K训练,而HEAR-Net以50K训练,两者都使用4个P40 GPU,每个GPU有8个图像。
我们使用同步的均值和方差计算,即这些统计数据是从所有GPU中收集的。
除了从EgoHands和GTEA Hand2K中采样手图像外,我们还使用公共代码在遮挡数据增强中渲染ShapeNet对象。
















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









