







本文由南加州大学和亚马逊联合发布,文章题目为《TriggerNER: Learning with Entity Triggers as Explanations for Named Entity Recognition 》,已经被ACL2020录用。文章针对命名实体识别中存在的需要大量耗时耗力的人工标注工作现状提出了方法TriggerNER,利用一种能够帮助人们找到实体的触发器entity trigger,通过Trigger Matching Network学习到相关触发器的信息以及触发器跟句子之间的匹配程度,从而更有利于标注。在实验上发现,使用20%的带有触发器的数据训练模型,其能力能够媲美使用70%原始数据训练的模型。

论文链接:
https://arxiv.org/pdf/2004.07493.pdfarxiv.org要点概览
- 提出“entity trigger”的概念,这是命名实体识别问题的一种解释性注释的新颖形式。在两个流行的数据集上众包并公开发布了14k带注释的实体触发器:CoNLL03(通用域),BC5CDR(生物医学域)。
- 提出一种新颖的学习框架,称为“Trigger Matching Network”,该框架对实体触发器进行编码,并柔化未标记的句子,以提高基础实体标记器的效率。
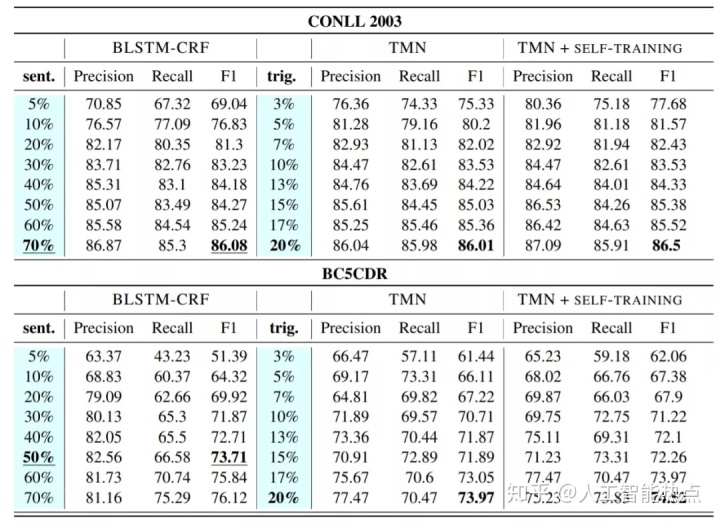
- TMN使用原始CoNLL03数据集中20%的触发器注释语句达到了使用70%的注释语句训练传统模型的性能。
背景
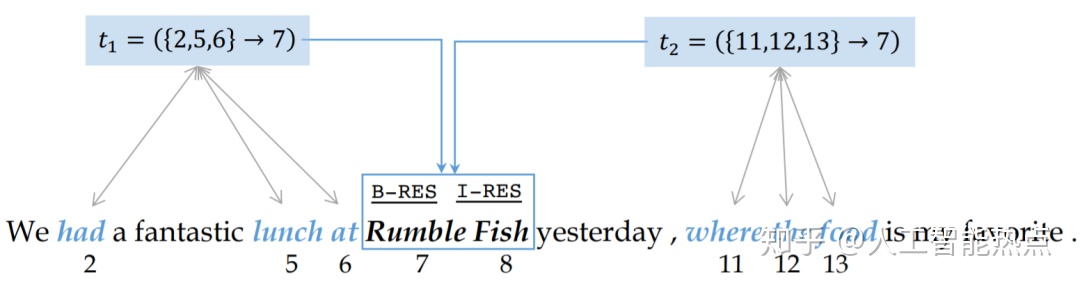
当前序列标注的进步主要集中在使用大量人工标注数据训练得到的神经网络模型,然而,收集这样的人工标注数据不仅昂贵,而且耗时,尤其对社交媒体数据或者各种专业领域数据。文章提出一个概念实体触发器,entity trigger,指的是一组能够在一个完整句子帮助解释实体识别的词语。例如图2,“have…lunch at”跟“where the food”是跟把实体Rumble Fist识别为Restaurant相关联的两个实体触发器。
方法
给定语料
对于句子中的人工标注的触发器,触发词的索引为
基于新的语料数据
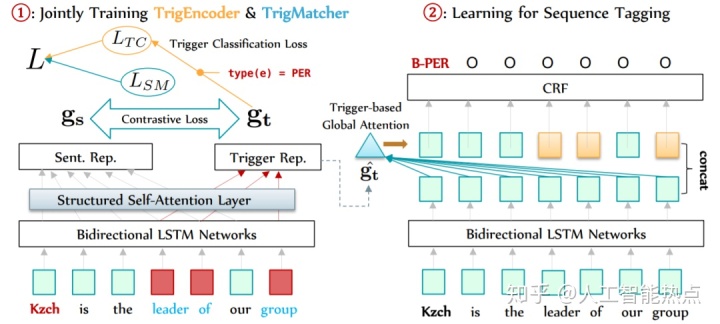
TrigEncoder
为了更佳高效的训练,文章把
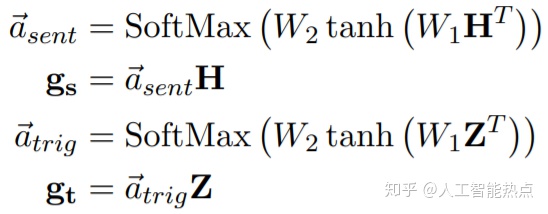
作者认为好的触发器的信息应该能帮助模型正确识别出实体的各种类型,为了衡量TrigEncoder的效果,文章设计了一个分类器,接受触发器的向量表示
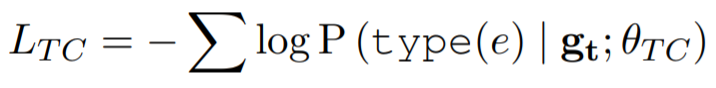
TrigMatcher
文章认为一个相似的触发器跟句子应有有相似的向量表示,所以同时设计了另一个TrigMatcher,用来学习去匹配触发器跟句子之间表示的程度,相应的对比损失函数如下公式所示。在训练时通过随机混淆触发器跟句子去生成负样本,然后利用正样本跟负样本一起训练这个TrigMatcher。
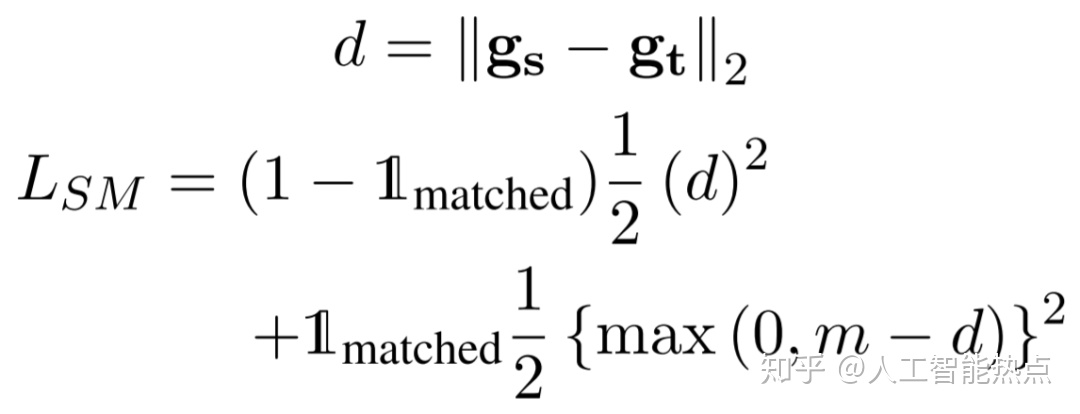
第一步的训练就是联合训练TrigEncoder和TrigMatcher,相应的损失函数就是
SeqTagger
当第一步训练完成后,会得到一个训练好的TrigEncoder和TrigMatcher,利用TrigEncoder编码得到的触发器向量的平均值作为
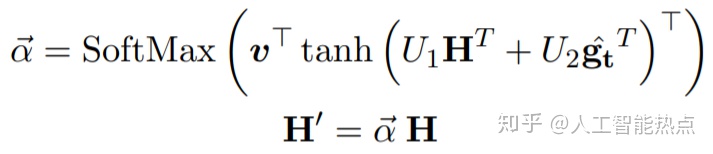
预测
当Trigger Matching Network训练完成后,在对没有触发器标注信息的句子进行预测时,会通过TrigMatcher,从所有的触发器词典中进行遍历,匹配到跟当前句子最相似的K个触发器。对这K个触发器的编码向量求平均后作为当前句子的触发器信息,从而使用Trigger Matching Network进行对应的命名实体识别,如图4所示。
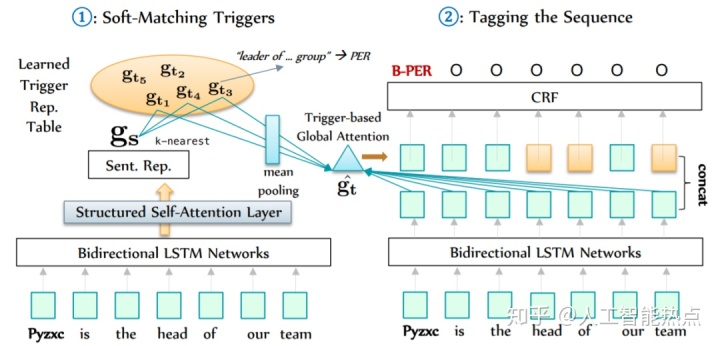
实验
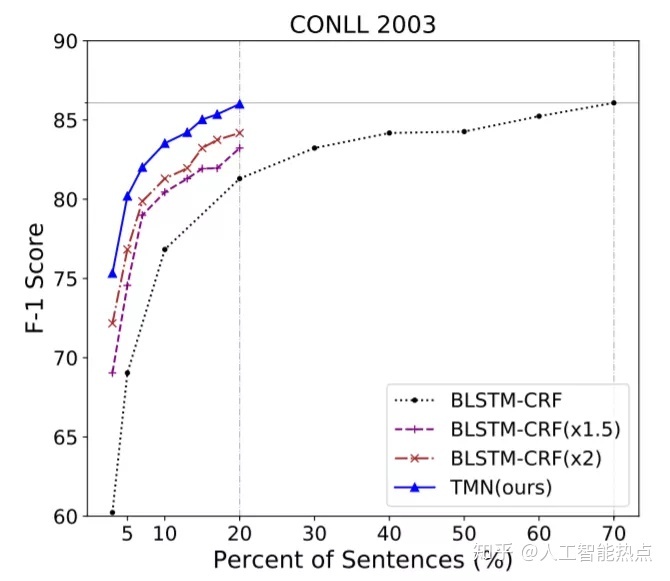
文章在两个数据集上进行了实验,一个是一般领域的CoNLL2003,另一个是生物医学领域的BC5CDR。主要的结论就是TMN更高效,使用TMN框架只要20%的数据得到的模型可以媲美使用70%的数据训练得到的传统模型。如图5,图6所示。
总结
文章引进了一个概念实体触发器“entity trigger”,它能够提供一些补充信号从而使得模型能够更高效的学习和具备更强的泛化能力。同时文章提出了一种新的命名实体识别框架TMN,能够联合学习触发器的表达和触发器跟所在句子之间的软匹配,所以在命名实体识别任务中能更好的处理那些未见过的句子。
对于TMN后期的研究,文章列举了三项:(1)研究如何自动生成触发器;(2)把存在的实体触发器迁移到那些低资源的语言;(3)改进实体触发器的建模方式。TMN框架,是对现有命名实体识别的一种改进,有一定的发展前景,极具落地的潜力。
转载请注明出处!


















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









