







原文:Learning representations by back-propagating errors, 1986
作者:David E. Rumelhart*, Geoffrey E. Hintont & Ronald J. Williams*
1.目标:
使得网络的输出尽可能地接近理想的输出,因此需要调整代表着特征表示的隐藏节点的权重。但是,对于特定的任务哪些隐藏节点所表示的特征才是所希望的很难直接了解。为了在端对端中实现自动的特征选择,因此提出了BP算法。
2.算法的实现:
最简单的学习网络就是分层网络:输入层在底部,中间多个隐藏层,顶部为输出层。当然,这种连接是可跳跃的(原文:but connections can skip intermediate layers,但是没有详细的拓展,resnet就可以看作一种拓展)。
对于输出层X的第j个节点,其由上一层Yi的节点的加权求和得到:
![]()
接着需要对节点进行非线性激活才能得到节点的输出(在文中使用的是sigmiod函数,但是sigmiod由严重的训练麻痹现象,现在用Relu居多):
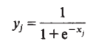
随后就是计算网络输出与理想输出的差异,这里采用的LOSS是平方差MSE准则,公式里面的C代表的是所有输入-输出对的index,其实本质上是把所有数据作为一个Batch,文中指出也可以逐逐个计算输入-输出对来更新权重,这样的好处是不需要不需要独立的内存来放置偏导数,但是没有讨论Batch对象梯度下降的优势:
![]()
接着就是利用链式法则进行逐层反向传播,计算误差对于权重的偏导数:
![]()
![]()
![]()
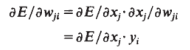
最后是权重的更新过程,在原文中提出了两种方法:直接根据偏导数更新、结合偏导数及上一次的更新情况来更新,方法1的收敛性不及方法2,但方法1更加简单和容易并行计算。方法2中阐述α采用指数衰减,取值范围在0-1间:
![]()
![]()
3.两个任务
BP算法在上面已经陈述完成,后面作者在文中穿插了两个用神经网络实现的任务:对称性检测与家族关系的存储,有兴趣到原文中阅读:


4.总结与建议
最后文中提出,BP算法最大的弱点就是不能保证到达全局最小值,通常得到的是一个局部最小值,尽管该局部最小值往往不会与全局最小差别很大。作者还提到他在当神经网络恰好刚刚能满足任务时会遇到比较离谱的情况,但是可以增加更多的连接以绕过带来较差结果的障碍。
最最最后作者说这种BP的传到与人脑的实际过程还是不一样的,值得花时间去探索更多类脑的梯度下降方法。















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









