







文章目录
0. 功能描述
散列更适合查找,不适合频繁更新
索引结构,每次插入和删除都需要更新索引,费时
1. 概念解析
-
聚集
把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。
-
填装因子(负载因子)
装填因子 = (哈希表中的记录数) / (哈希表的长度)
装填因子是哈希表装满程度的标记因子。值越大,填入表中的数据元素越多,产生冲突的可能性越大。
-
冲突
不同关键字值对应相同的存储空间
-
同义词
如果两个关键字的值不等但哈希函数值相等,则称这两个关键字为同义词。
2. 构造方法(HASH函数)
2.1 直接定址法(散列法)
直接定址法是直接取关键字的某个线性函数值为散列地址:H(key)=a*key+b
🌰
直接定址法是直接取关键字的某个线性函数值为散列地址。当散列函数为H(key)=a*key+b时,假设常数a和b的值分别为0.6和3,散列表的长度为20,那么在不考虑冲突的情况下,key值为10的关键字散列的地址位置为(9)
答:0.6*10+3 = 9
2.2 除余法
设散列表中有 m 个存储单元,除余法散列函数(HASH函数) H(key)= key % p (p 最好选择:小于等于m的最大素数 )
2.3 平方取中法
H(key)=(key*key div 1000 ) mod 1000000)平方后取中间的,每位包含信息比较多。
取关键字平方后的中间几位为哈希地址。由于一个数的平方的中间几位与这个数的每一位都有关,因而,平方取中法产生冲突的机会相对较小。平方取中法中所取的位数由表长决定。
🌰
K = 456 , K2 = 207936 若哈希表的长度m=102,则可取79(中间两位)作为哈希函数值。
以下构造方法还未整理
数字分析法
假设关键字是以r为基的数,并且哈希表中可能[TA6:除余法] 出现的关键字都是事先知道的,则可取关键字中的若干位组成哈希地址。
折叠法
把一个关键码分成位数相同的几段(最后一段的位数可以, 不同),段的长度取决于哈希表的地址位数,然后将各段的 叠加和(舍去进位)作为哈希地址。
折叠法又分为移位叠加和边界叠加两种。其中,移位叠加是将 各段的最低位对齐,然后相加;而边界叠加则是两个相邻的段沿边界来回折叠,然后对齐相加。
例:关键字K=58242324169,哈希表长度为1000,则将此关键字分成三位一段,两种叠加结果如下:582+ 423+ 241+69=315,582+324+ 241+96= 243
当关键字位数很多,而且关键字中每一位上数字分布大致均匀时,可以使用折叠法。
乘余取整法
首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整
f(x):=trunc((x/maxX)*maxlongit) mod maxM,主要用于实数。
随机数法
选择一个随机函数,取关键字的随机函数值为它的散列地址
3. 冲突处理
在哈希法存储中,冲突指的是?
答:不同关键字值对应相同的存储空间
| 分类 | 具体细节 |
|---|---|
| 开放定址法(找坑位) | 线性探测、二次探测 |
| 拉链法 | 链式地址法 |
拉链法、双重散列、多重散列、开放定址法、公共溢出区法
3.1 线性探测再散列
需要搜索或加入一个哈希表项时,使用哈希函数计算哈希值:
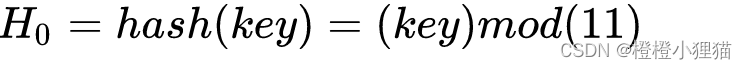
一旦发生冲突,在表中顺次向后寻找“下一个”空值Hi的公式为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4s02oKhv-1665217849882)(https://www.nowcoder.com/equation?tex=H_%7Bi%7D%3D(H_%7Bi-1%7D%2B1)]mod%20%5Cleft(%20m%5Cright)%2Ci%3D1%2C2%2C...%2Cm-1)](https://img-blog.csdnimg.cn/a686b47a876747bcac42b0cf935c58ca.png)
🌰
设哈希表长m=13,哈希函数H(key)=key MOD 11。表中点:addr(16)=5,addr(28)=6,addr(84)=7,addr(19)=8,其余地址为空,如用线性探测再散列处理冲突,则关键字为38的地址为( )
38 % 11 = 7; 与addr(84)=7冲突;所以就顺着表往后放,即(7 + i)% 13 (i = 1, 2, … ,直到存储空间上没有值), 所以为9
3.2 二次探测再散列法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hzn2XZio-1665217849883)(https://uploadfiles.nowcoder.com/images/20170604/4811031_1496559933034_F7F0BBDB094D0B83D7561FC5EC2130D7)]](https://img-blog.csdnimg.cn/f87f621102bd4a95a61f15daa88c04e2.png)
3.3 链式地址法
将哈希值相同的元素用链表进行相连。
最后:本文的有些图片来自于牛客网哈希选择练习题中的评论。
















 6105
6105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











