






1. CRNN 算法的背景
传统的OCR在识别过程中分为两步:单字切割与分类任务。我们一般都会讲一连串文字的文本文件先利用投影法切割出单个字体,再送入CNN里进行文字分类。但是此法已经有点过时了,现在更流行的是基于深度学习的端到端的文字识别,即我们不需要显式加入文字切割这个环节,而是将文字识别转化为序列学习问题,虽然输入的图像尺度不同,文本长度不同,但是经过CNN和RNN后,在输出阶段经过一定的翻译后,就可以对整个文本图像进行识别,也就是说,文字的切割也被融入到深度学习中去了。
现今基于深度学习的端到端OCR技术有两大主流技术:CRNN OCR和attention OCR。其实这两大方法主要区别在于最后的输出层(翻译层),即怎么将网络学习到的序列特征信息转化为最终的识别结果。这两大主流技术在其特征学习阶段都采用了CNN+RNN的网络结构,CRNN OCR在对齐时采取的方式是CTC算法,而attention OCR采取的方式则是attention机制。本文将介绍应用更为广泛的CRNN算法。
2. CRNN网络结构

网络主要由三部分组成,从下到上依次为:
卷积层,使用CNN,作用是从输入图像中提取特征序列;
循环层,使用RNN,作用是预测从卷积层获取的特征序列的标签(真实值)分布;
转录层,使用CTC,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;

2.1. 卷积层
卷积层使用了VGG16进行特征提取,其中输入图像为单通道灰度图像,且图像高度统一为32个像素 。区别于传统的VGG16,CRNN的卷积层在第3个和第4个maxpooling层采取了1×2的矩形池化窗口(h×w),这个改动是因为文本图像多数都是高较小而宽较长,所以其feature map也是这种高小宽长的矩形形状。CNN输出的图像尺寸大小为512 × 1 × w/4(c×h×w)。输出的向量格式为[b, c, h, w]。
例如,输入CNN的图像大小为[32, 100, 3],CNN处理完的结果为[1,25, 512]。
2.2 循环层
RNN部分使用了双向LSTM,隐藏层单元数为256,CRNN采用了两层BiLSTM来组成这个RNN层。
RNN层的输入为[seq_len, batch, input_size]
seq_len: 序列长度---------w
batch: 即batch_size-------batchsize
input_size: 输入特征数目 ---------c
将CNN的输出结果[b, c, h, w]经过转化变为[w, b, c]作为RNN的输入,即[w, b, c] = [seq_len, batch, input_size]
LSTM有256个隐藏节点,经过LSTM后变为长度为T × nclass的向量,再经过softmax处理,列向量每个元素代表对应的字符预测概率,最后再将这个T的预测结果去冗余合并成一个完整识别结果即可。

2.3 转录层
RNN进行时序分类时,不可避免地会出现很多冗余信息,比如一个字母被连续识别两次,这就需要一套去冗余机制。CTC有一个blank机制来解决这个问题。
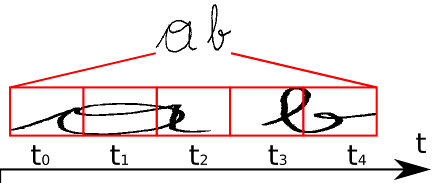 如上图所示,我们要识别这个手写体图像,标签为“ab”,经过CNN+RNN学习后输出序列向量长度为5,即t0~t4,此时我们要将该序列翻译为最后的识别结果。我们在翻译时遇到的第一个难题就是,5个序列怎么转化为对应的两个字母?重复的序列怎么解决?刚好位于字与字之间的空白的序列怎么映射?这些都是CTC需要解决的问题。
如上图所示,我们要识别这个手写体图像,标签为“ab”,经过CNN+RNN学习后输出序列向量长度为5,即t0~t4,此时我们要将该序列翻译为最后的识别结果。我们在翻译时遇到的第一个难题就是,5个序列怎么转化为对应的两个字母?重复的序列怎么解决?刚好位于字与字之间的空白的序列怎么映射?这些都是CTC需要解决的问题。
我们从肉眼可以看到,t0,t1,t2时刻都应映射为“a”,t3,t4时刻都应映射为“b”。如果我们将连续重复的字符合并成一个输出的话,即“aaabb”将被合并成“ab”输出。但是这样子的合并机制是有问题的,比如我们的标签图像时“aab”时,我们的序列输出将可能会是“aaaaaaabb”,这样子我们就没办法确定该文本应被识别为“aab”还是“ab”。CTC为了解决这种二义性,提出了插入blank机制,即连续相同的字符若中间含有blank则不予以合并,比如我们以“-”符号代表blank,则若标签为“aaa-aaaabb”则将被映射为“aab”,而“aaaaaaabb”将被映射为“ab”。引入blank机制,我们就可以很好地处理了重复字符的问题了。
3. CRNN的创新点
CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同点是将输入进LSTM的特征,从语音领域的声学特征(MFCC等),替换为CNN网络提取的图像特征。很好的将CNN做图像工程的潜力与LSTM做序列化识别的潜力进行结合。














 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









