







1. 分类损失函数
1.1 二值交叉熵损失函数(BCE)
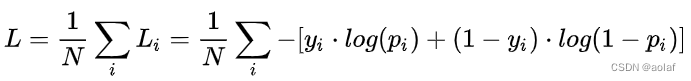
log的底数为e
yi表示样本 i 的标签,正类为1,负类为0(注:BCE并不是只能学习0或1的label),使用的是one_hot编码
pi表示样本 i 预测为正类的概率,是经过sigmoid后的数
N 表示样本个数,这里是取了均值的
推理过程:
假设x为输入特征,y为标签,当标签为1时,概率为p。
那么标签为0时的概率为1-p。
利用最大似然估计将其结合:
P(y|x)= py(1-p)1-y
我们希望的是概率 P(y|x) 越大越好。首先,我们对 P(y|x) 引入 log 函数,因为 log 运算并不会影响函数本身的单调性。
logP(y|x) = log(py (1-p)1-y) = y logp + (1-y) log(1-p)
我们希望logP(y|x)越大越好,为了方便最优化计算,另Loss= -logP(y|x),此时变成了Loss越小越好。
Loss = -ylogp - (1-y)log(1-p)
以上是单个样本的损失函数,对于N个样本,分别将他们的损失函数相加即可。
图形理解:
当y=1时,Loss = -logp,此时预测p离标签1越近损失越小。
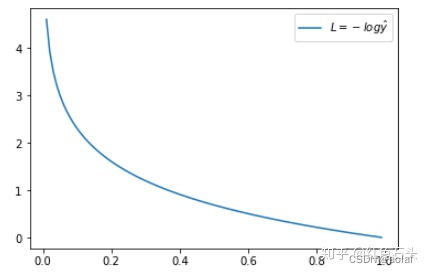
当y=0时,Loss = -log(1-p),此时预测p离标签0越近损失越小。
1.2 交叉熵损失函数(CE)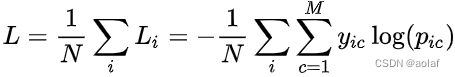
log的底数为e
yic 表示样本 i 的标签,这是一个符号函数,如果样本 i 的真实类别等于c,则取1,否则取0
pic 表示样本 i 预测为 c类 的概率
N 表示样本个数
M 表示类别数量
示例:
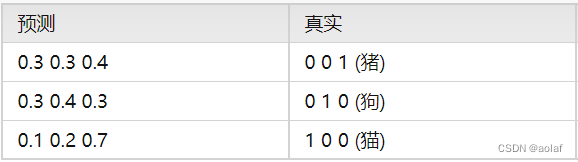
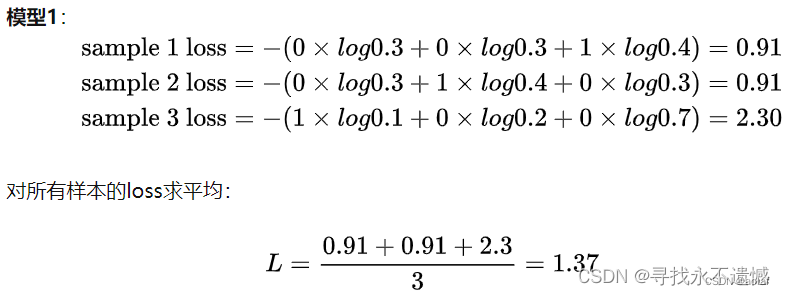
1.3 Balanced Cross Entropy
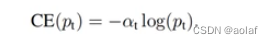 引入了一个权重因子α ∈ [ 0 , 1 ] ,当为正样本时,权重因子就是α,当为负样本时,权重因子为1-α,当权重因子为0.75时,效果最好。用于解决正负样本不平衡的问题
引入了一个权重因子α ∈ [ 0 , 1 ] ,当为正样本时,权重因子就是α,当为负样本时,权重因子为1-α,当权重因子为0.75时,效果最好。用于解决正负样本不平衡的问题
1.4 focal loss
focal loss 是基于Balanced Cross Entropy loss的,给其乘了(1-p)γ的权重,其中γ为一个参数,范围在 [0,5], 当 γ为0时,就变为了Balanced Cross Entropy损失函数。Y用于控制样本的难易程度,α用于控制正负样本比例。
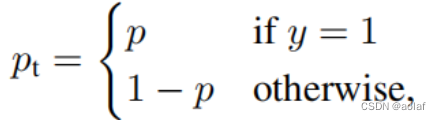
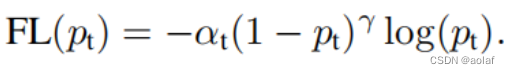
Loss = -(1-p)γ logp,(y=1)
Loss = - pγ log(1-p),(y=0)
理解:
若y=1,此时若预测p接近于1,那么说明该正样本容易区分,为简单样本,同时1-p接近于0,相当于弱化了简单样本的权重。
若预测p远离1,那么说明该正样本不易区分,为复杂样本,同时1-p趋近于1,不影响困难样本的权重。
若y=0, 此时若预测p接近于0,那么说明该负样本容易区分,为简单样本,因此Loss就小。
若预测p接近于1,那么说明该负样本不易区分,为复杂样本,因此Loss就大。
1.5 QFL
QFL将focal loss中的(1-p)γ替换为|y-σ|β,利用预测框和GT的iou作为y,将focal loss中原先的0,1离散值变为y这一连续数值。同时在训练过程中将质量评估分支与分类分支进行了关联。解决了推理阶段,分类score高,但是框的质量较差的问题。
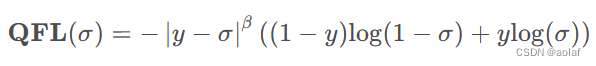
其中y为0~1的质量标签,σ为预测结果经过sigmoid处理。注意QFL的全局最小解即是σ = y。和Focal Loss类似,我们实验中发现一般取β = 2为最优。
相比于单独预测质量分支的优点:
①. 训练的时候,分类和质量估计各自训练,但测试的时候却又乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end。
②. 分类分支是联合了正负样本共同训练,而质量分支只训练了正样本,对于大量可能的负样本,他们的质量预测是一个未定义行为。那么在做nms的时候,可能面临一个类别分数较低的负样本他的质量评估分支很高,两者乘积后,从而排在了正样本之前。
2. 回归损失函数
2.1 L1 loss (MAE)
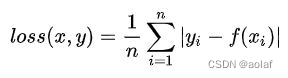
对离群值不敏感,当目标变量的分布具有异常值时,都有着稳定的梯度,不易导致梯度爆炸问题,它被认为对异常值具有很好的鲁棒行。
在x=0处不可导,导数不连续,求解效率低。
2.2 L2 loss(MSE )
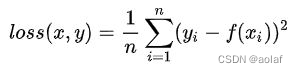
使用平方意味着当预测值离目标值更远时在平方后具有更大的惩罚,预测值离目标值更近时在平方后惩罚更小,因此,当异常值与样本平均值相差格外大时,模型会因为惩罚更大而开始偏离,因此对异常值处理不好。
处处可导,导数连续,求解效率高。
2.3 smooth L1 loss
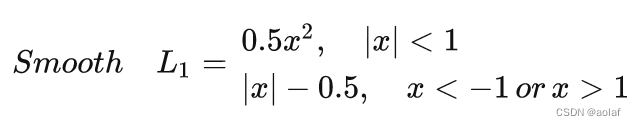
在0附近采用了平方函数,解决了L1 loss在0处不可导的问题,其余地方使用L1,解决了对离群点的鲁棒性。
2.4 Iou 类型loss
2.4.1 Iou loss
IOU_Loss:主要考虑预测框和目标框重叠面积。
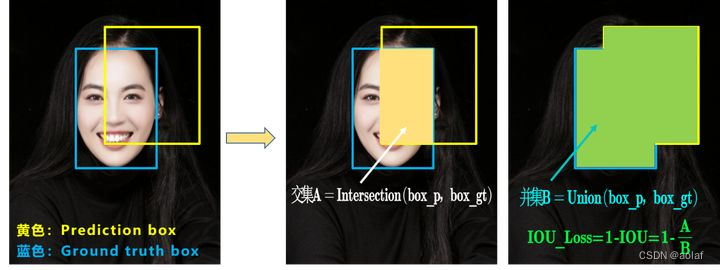
问题1:当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,IOU_Loss无法优化两个框不相交的情况。
问题2:两个预测框iou相同时,IOU_Loss无法区分两者重叠的好坏。

2.4.2 GIOU loss
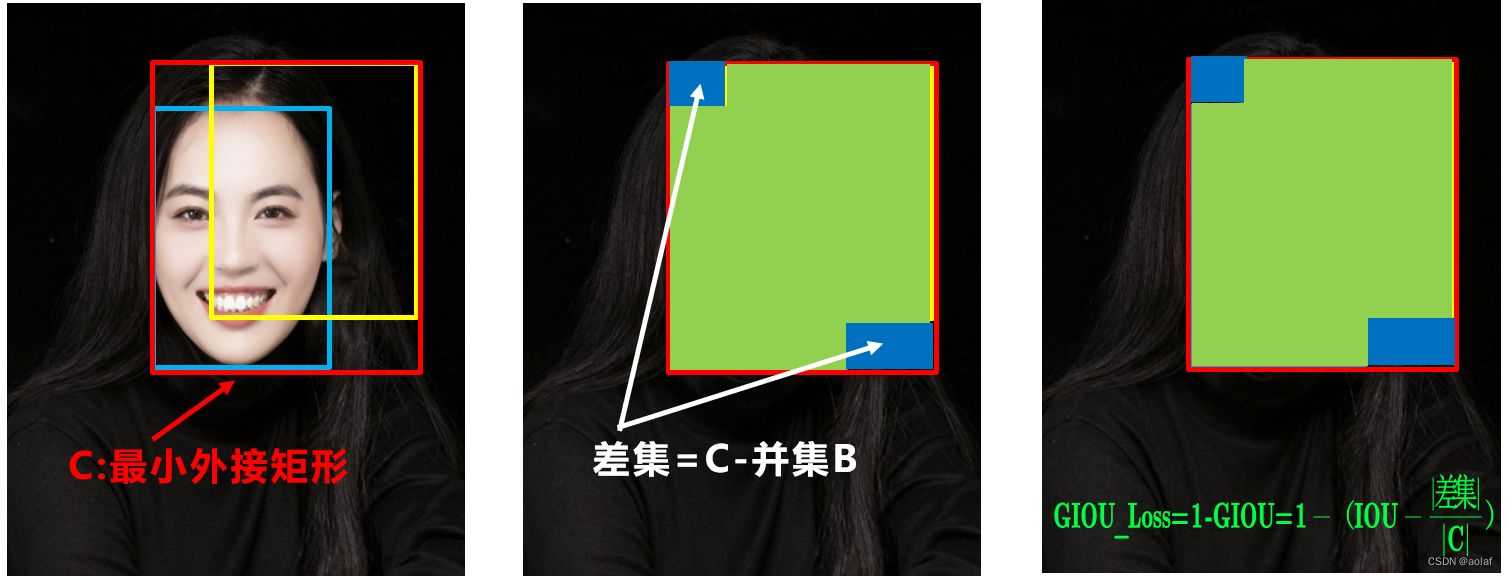
GIOU 在IOU的基础上,解决预测框和目标框不重合的问题。
 问题:
问题:
状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。

2.4.3 DIOU loss
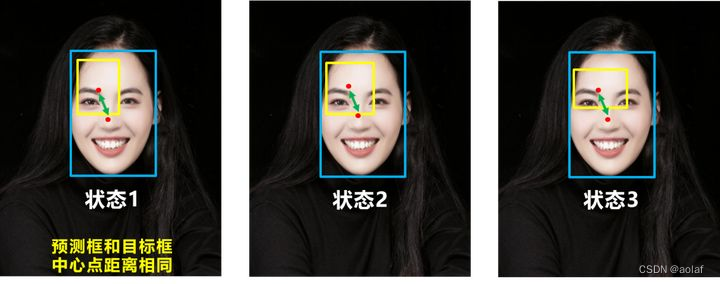
DIOU_Loss考虑了预测框和目标框的重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。

问题:没有考虑到长宽比
比如下面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
2.4.4 Ciou loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
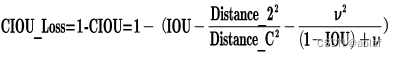
其中v是衡量长宽比一致性的参数,我们也可以定义为
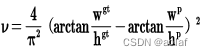














 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









