







1. YOLO V1
1.1 YOLO V1的核心思想
将整张图作为网络的输入,利用卷积层提取特征,全连接层预测图像位置和类别,做到了仅使用一个卷积神经网络端到端地实现检测物体的目的。
1.2 YOLO V1的网络结构
YOLO-v1借鉴了GoogleNet,整个网络包括24个卷积层和2个全连接层,其中卷积层用于提取图像特征,全连接层用来预测图像位置和类别。
早期,图像分类任务中,网络最后会将卷积输出的特征图拉平(flatten),得到一个一维向量,然后再接若干全连接层做预测。YOLOv1本身最大的弊端就在于“flatten”这种方式本身,基本上,对于“flatten方式会破坏特征的空间结构信息”的这一观点已经成为业界共识。

1.3 YOLO V1 的训练过程
1.3.1 YOLO V1的输入输出
由于两个全连接层的存在,因此输入图像尺寸须固定,论文中作者设计的输入尺寸是448 * 448。经过网络的特征提取,最后获得7 * 7 * 30的输出特征图。
其中7 * 7是由原图(448 * 448)经过了64倍的降采样获得。
1.3.2 每个单元格(grid_ceil)的作用
①.若一个物体的中心落在某个grid_ceil上,则说明该grid_ceil内有物体,由他来负责检测该物体。(每个单元格分开干活)
②.每个grid_ceil要预测B个Bounding box(论文中b = 2),同时为每个Bounding box预测一个Confidence。即每个Bounding box要预测(x, y, w, h)、Confidence这5个值。
③.每个grid_ceil要预测C(物体种类个数)个类别。
由上可知:
1. 每个grid_ceil可以预测多个Bounding box值以及置信度。
2. 由于每个grid_ceil只预测一种物体类别,因此无论该单元格预测了多少个Bounding box,他们的类别必须一致。(只能是同类的不同物体)
3. 这B个Bounding box实际是网络输出的预测结果,而非后面AnchorBase算法中的anhcor_box,因此本质上来说,YOLOv1是anchor free算法。
1.3.3 Confidence
置信度有两个含义:
1.单元格内是否有物体。
2.Bounding box的准确度。
定义置信度为
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object)*IOU_{pred}^{truth}
Pr(Object)∗IOUpredtruth
若单元格内有物体,则
P
r
(
O
b
j
e
c
t
)
=
1
Pr(Object)=1
Pr(Object)=1, 此时置信度为训练过程中预测的bounding box 和实际的 groundtruth 之间的 IoU 值。
若单元格内没有物体,则
P
r
(
O
b
j
e
c
t
)
=
0
Pr(Object)=0
Pr(Object)=0,此时置信度为0。
1.3.4 YOLO V1的正负样本匹配与缺陷
①. 将GT的坐标x1, y1, x2, y2转换成中心点、宽高格式
②. 计算中心点所在的网格(grid_x, grid_y),该网格则为正样本候选区域,其表示该grid_ceil中有物体。
③. 计算在该grid_ceil中输出的B个预测框与GT的iou,选择IOU大的那个预测框为正样本,分别计算置信度损失、类别损失和边界框回归损失,其中置信度损失的标签就是该IoU值。(iou-aware思想)
④. 对于剩下的没被选中的B-1个预测框,它们都被标记为负样本,即只计算置信度损失,且置信度标签都为0。这些负样本不计算类别损失和边界框回归损失。同时,对于那些处在正样本候选区域之外的预测,都标记为该标签的负样本,也只计算置信度损失。
缺陷:
我们不断重复这几个步骤,直到给所有的标签都匹配上了一个正样本为止。不过,这里会有两个潜在的问题,
①. 两个同类物体的中心点都在同一个网格,且都匹配到了同一个预测框(共用预测框)
②. 两个不同类别物体的中心点落在了同个网格(共用正样本区域)
那么这个预测框该学哪个标签?这个问题是YOLOv1无法回答的,是YOLOv1的一个缺陷。
def generate_txtytwth(gt_label, w, h, s):
xmin, ymin, xmax, ymax = gt_label[:-1]
# 计算边界框的中心点
c_x = (xmax + xmin) / 2
c_y = (ymax + ymin) / 2
box_w = (xmax - xmin)
box_h = (ymax - ymin)
# 计算中心点所在的网格坐标
c_x_s = c_x / s
c_y_s = c_y / s
grid_x = int(c_x_s)
grid_y = int(c_y_s)
# 计算中心点偏移量和宽高的标签,为了统一尺度,将宽高也归一化至(0,1)
tx = c_x_s - grid_x
ty = c_y_s - grid_y
tw = box_w / w
th = box_h / h
return grid_x, grid_y, tx, ty, tw, th
1.3.5 损失函数
损失函数分为3个部分,每个部分都使用MSE loss:
这是因为YOLO-v1关于框的五个参数和类别都是用的是线性函数(全连接层不加激活函数)来做的预测。

I
i
j
o
b
j
\mathbb{I}_{ij}^{obj}
Iijobj,
I
i
j
n
o
o
b
j
\mathbb{I}_{ij}^{noobj}
Iijnoobj,
I
i
o
b
j
\mathbb{I}_{i}^{obj}
Iiobj:
I
i
j
o
b
j
\mathbb{I}_{ij}^{obj}
Iijobj:表示第i个grid_ceil预测出的第j个框是正样本,由上图可以看出,只有正样本才计算bbox损失与类别损失。
I
i
j
n
o
o
b
j
\mathbb{I}_{ij}^{noobj}
Iijnoobj:表示第i个grid_ceil预测出的第j个框是负样本,其参加置信度计算
I
i
o
b
j
\mathbb{I}_{i}^{obj}
Iiobj:表示第i个grid_ceil中有一类物体,其参加分类损失计算。
λ
c
o
r
r
d
λ_corrd
λcorrd和
λ
n
o
o
b
j
λ_noobj
λnoobj:
λ
n
o
o
b
j
λ_noobj
λnoobj:一张图中,有物体的网格数目是小于没有物体的网格数目的,因此,为了平衡他们两个的损失,需要赋予不同的权重,正样本的置信度损失的权重给1 ,没有物体的,即负样本的损失权重给0.5 。
λ
c
o
r
r
d
λ_corrd
λcorrd:框回归的权重,平衡回归学习与类别学习的权重。
w、h的开根号:
对于预测的bbox框,大的bbox预测有点偏差可以接受,而小的bbox预测有点偏差就比较受影响了。
对于这种情况,宽高使用先平方根再求均方误差,尽可能的缩小在小偏差下的影响。(开根号后的差值更小)
categories:
类别分支只负责计算正样本区域(grid_ceil有物体),不计算负样本区域(grid_ceil没有物体,这部分交给objectness分支)。
由于每个单元格只负责一类物体的预测,故不需要考虑B个bbox,其损失函数为:
1.4 YOLO V1的推理过程
-
计算bbox和类别:
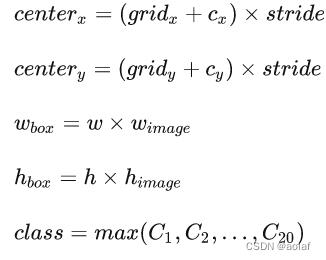
-
计算每个边界框的得分:
在YOLOv1中,边界框的得分score=该处框的置信度即objectness与类别的置信度class的乘积:
score = Cbox * Pr(class)
因为在训练阶段,只有正样本区域的类别预测会被学习到,而负样本区域给出的类别预测不会被学习,这就会导致在推理的时候,grid_ceil有物体的地方会有可靠的class预测输出,而没有物体的地方的class预测输出约等于瞎预测,毕竟没有被训练。但这个时候,由于objectness的作用就是判断是否有物体,因此,对于前景,objectness的值会很接近1,反之很接近0。那么,即使class瞎预测,但objectness只要给出接近0的值,那么这个地方的score也会很低,从而滤除了背景。 -
用这个得分去做后续的非极大值抑制处理(NMS)。最后保留下来的结果,就是网络的最终预测输出。
1.5 YOLO V1的优缺点
优点:
YOLO的精髓在一在于把背景和前景与各个类别的学习给解耦了。objectness分支就负责学习前景和背景,本质是个二分类,等价于Faster R-CNN中的RPN,而类别学习只学正样本的信息,标签里也没加进去背景标签,这就等于Faster R-CNN的第二阶段。而像SSD和RetinaNet,都是把背景作为一类标签加到了class里,把背景和前景与各个类别的学习耦合到了一块去,那自然要比YOLO学得麻烦一些。
缺点:
由于每个网格只预测一类物体,对于相互靠近的不同类物体,检测效果不好。
2. YOLO V2
2.1 YOLO V2的改进策略
2.1.1 Batch Normalization(BN层)
2.1.2 High Resolution Classifier(高分辨率分类器)
在YOLOv1中,其backbone先在ImageNet上进行预训练,预训练时所输入的图像尺寸是224×224,而做检测任务时,YOLOv1所接收的输入图像尺寸是448×448,不难想到,训练过程中,网络必须要先克服由分辨率尺寸的剧变所带来的问题。毕竟,backbone网络在ImageNet上看得都是224×224的低分辨率图像,突然看到448×448的高分辨率图像,难免会“眼晕”。为了缓解这一问题,作者将已经在224×224的低分辨率图像上训练好的分类网络又在448×448的高分辨率图像上进行微调,共微调10个轮次。微调完毕后,再去掉最后的全局平均池化层和softmax层,作为最终的backbone网络。
2.1.3 New Backbone:Darknet-19
YOLO V2采用了一个新的基础模型,称为Darknet-19,包括19个卷积层和5个maxpooling层。Darknet-19与VGG16模型设计原则是一致的,主要采用3 * 3卷积,通过2 * 2的maxpooling进行2倍下采样,同时将特征图的channles增加两倍。
Darknet-19采用了全局平均池化做预测,并且在3 * 3卷积之后使用了1 * 1卷积来降维,减少计算量。
Darknet-19每个卷积层之后使用了BN层以加快收敛速度,降低模型过拟合。激活函数采用leakly-relu

2.1.4 引入Faster R-CNN中的anchor box机制
借鉴Faster R-CNN的RPN层,在每个grid_ceil处预先设置k个不同尺寸、不同宽高比的先验框anchor box。
先验框的作用就是提供边界框的尺寸先验信息,让网络只需学习偏移量来调整先验框去获得最终的边界框,相较于YOLOv1的直接回归边界框的宽高,基于先验框的方法表现得往往更好。
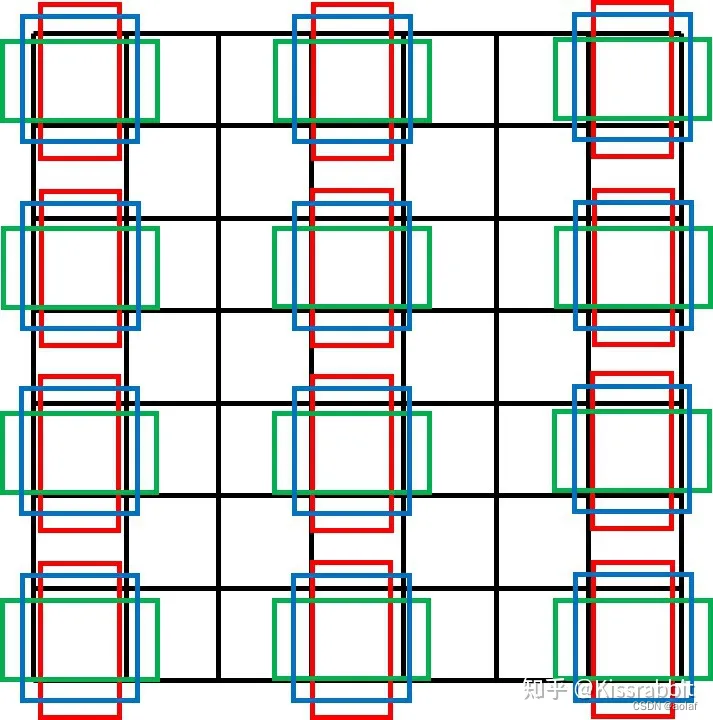
2.1.5 Dimension Clusters(尺寸聚类)
在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLO V2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
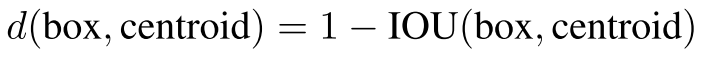
聚类的缺点:
由聚类所获得的先验框严重依赖于数据集本身,倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。
2.1.6 Direct location prediction(更换预测框编码方式)
tx, ty:
对于每个GT框的中心点,YOLOv2仍去学习中心点偏移量tx, ty,由于这两个值在[0, 1],因此对网络预测的输出结果加了sigmoid加以约束。(在YOLOv1时,作者没有在意这一点,直接使用线性函数输出,在训练初期,模型很有可能会输出数值极大的中心点偏移量,导致训练不稳定甚至发散。)
tw, th:
对于每个GT框的宽高,由于有了先验框的宽高信息,因此网络不必再学习整个GT框的宽高,只需学习相对其先验框的偏移量tw, th。
# 将真实边界框的尺寸映射到网格的尺度上去
c_x_s = c_x / s
c_y_s = c_y / s
box_ws = box_w / s
box_hs = box_h / s
# 计算中心点所落在的网格的坐标
grid_x = int(c_x_s)
grid_y = int(c_y_s)
# anchor box的宽高
p_w, p_h = anchor_size
# 网络预测值
tx = c_x_s - grid_x
ty = c_y_s - grid_y
tw = np.log(box_ws / p_w)
th = np.log(box_hs / p_h)
下图为推理过程,其中蓝框为GT,虚线框为先验框。

2.1.7 Head变化----全卷积网络
在YOLOv1中,网络在最后阶段使用了全连接层这不仅破坏了先前的特征图所包含的空间信息结构,同时也导致参数量爆炸。为了解决这一问题,作者便将其改成了全卷积结构。
网络的输入图像尺寸从448改为416,去掉了YOLOv1网络中的最后一个maxpooling层和所有的全连接层,修改后的网络的最大降采样倍数为32。由于每个网格处设置了K个先验框anhcor box,每个anchor box都需要预测1个置信度、4个边界框的位置参数和C个类别预测。因此网络的最终输出为13 * 13 * K * (1 + 4 + 20),其中13 * 13为输出分辨率,K * (1 + 4 + 20)为通道数。

2.1.8 使用更高分辨率的特征
YOLO作者又借鉴了同年的SSD工作:使用更高分辨的特征。
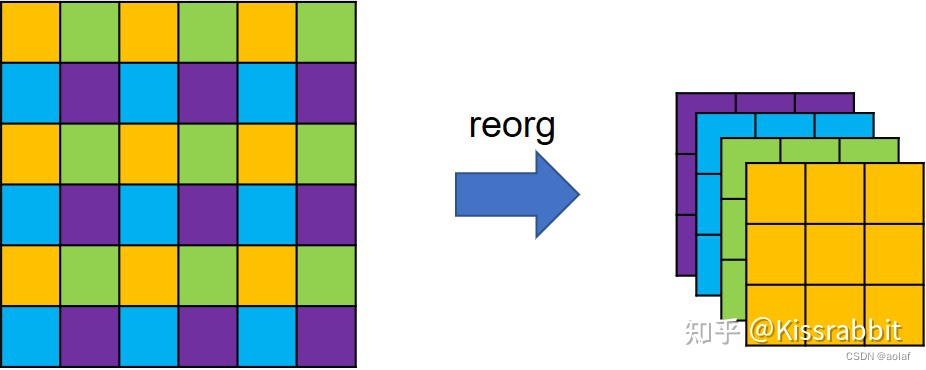
具体来说,之前的改进中,YOLOv1都是在最后一张大小为13×13×1024的特征图上进行检测,为了引入更多的细节信息,作者将backbone的第17层卷积输出的26×26×512特征图拿出来,利用卷积将通道数变为26×26×64,接着做一次特殊的降采样操作(reorg),得到一个13×13×256特征图,然后将二者在通道的维度上进行拼接,最后在这张融合了更多信息的特征图上去做检测。
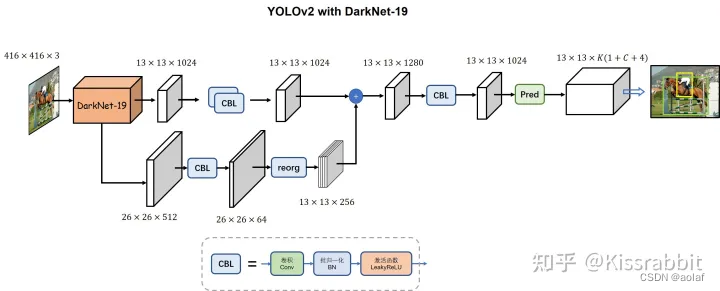
特征图在经过reorg操作的处理后,特征图的宽高会减半,而通道则扩充至4倍,因此,从backbone拿出来的26×26×512特征图就变成了13×13×2048特征图。这种特殊降采样操作的好处就在于降低分辨率的同时,没丢掉任何细节信息,信息总量保持不变。
2.1.9 多尺度训练
每迭代10个iter,就从{320,352,384,416,448,480,512,576,608}选择一个新的图像尺寸用作后续10次训练的图像尺寸。
2.2 YOLO V2的正负样本匹配
YOLOv2的检测机制和YOLOv1是一样的,仍是先获得所有预测框,然后与真实框计算IoU,只有IoU最大的预测框会去计算正样本损失,小于阈值的计算负样本损失,其余的框忽略。
2.3 YOLO V2的损失函数
源码中计算loss的步骤:

-
计算预测框中是否有物体的损失,这里需要计算每个预测框和GT框之间的IOU值,并且取最大值记作MaxIOU,如果该值小于一定的阈值,YOLOv2论文取了0.6,那么这个预测框就标记为background。
-
12800个iter之前计算计算Anchor box和预测框的坐标误差,促进网络学习到Anchor的形状。
-
计算类别预测的损失(MSE)。















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









