







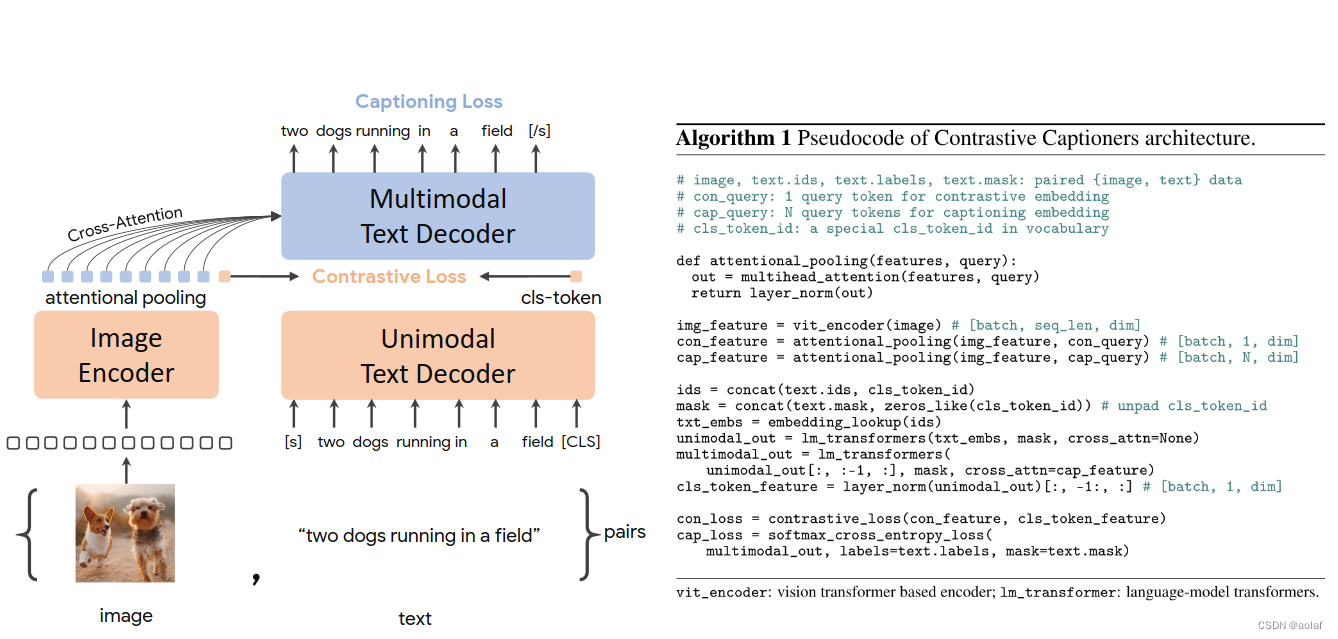
1 CoCa简介
CoCa代表Contrastive Captioner 的缩写,代表模型用两个目标函数训练出来的,一个是Contrastive Loss,一个是Captioning Loss。
2 CoCa训练流程
- 利用ViT对image进行encoder编码获得图像特征token
- 对图像特征进行attention pooling(multihead attention), 取第0位作为计算对比损失的cls-token,后255位作为计算生成损失的视觉token
- 对text进行embedding编码,在文本token末尾嵌入cls_token
- 生成相应的单词遮挡掩膜mask,给text-token加上位置编码
- 将text-token和mask-atten送入transformer学习获得文本cls_token(text_latent), 和其余单词token(token_emb)
2.1 image encoder
def _encode_image(self, images, normalize: bool = True):
image_latent, tokens_embs = self.visual(images)
image_latent = F.normalize(image_latent, dim=-1) if normalize else image_latent
# image_latent:constractive_token, tokens_embs: caption_token
return image_latent, tokens_embs
#### self.visual(images):
def forward(self, x: torch.Tensor):
# [b, 3, 224, 224]--->[b, 1024, 16, 16]
x = self.conv1(x)
# [b, 1024, 16, 16]--->[b, 1024, 256]
x = x.reshape(x.shape[0], x.shape[1], -1)
# [b, 1024, 256]--->[b, 256, 1024]
x = x.permute(0, 2, 1)
# 在序列长度上给图像嵌入一个类别,x:[b, 256 + 1, 1024]
x = torch.cat([_expand_token(self.class_embedding, x.shape[0]).to(x.dtype), x], dim=1)
# 嵌入位置编码,x:[b, 256 + 1, 1024]
x = x + self.positional_embedding.to(x.dtype)
# patch_dropout, x:[b, 256 + 1, 1024]
x = self.patch_dropout(x)
# LayerNorm处理 x:[b, 256 + 1, 1024]
x = self.ln_pre(x)
# NLD -> LND [b, 256 + 1, 1024]---> [256 + 1, b, 1024]
x = x.permute(1, 0, 2)
# transformer网络处理
x = self.transformer(x)
# LND -> NLD [256 + 1, b, 1024]--->[b, 256 + 1, 1024]
x = x.permute(1, 0, 2)
if self.attn_pool is not None:
# this is the original OpenCLIP CoCa setup, does not match paper
# x:[b, 257, 1024]--->[b, 256, 768]
x = self.attn_pool(x)
# ln归一化, [b, 256, 768]
x = self.ln_post(x)
# pooled: 类别token:[b, 768] tokens:图像token:[b, 255, 768]
pooled, tokens = self._global_pool(x)
# pooled: [b, 768]@[768, 768]--->[b, 768]
if self.proj is not None:
pooled = pooled @ self.proj
# 同时返回cls-token和视觉token
if self.output_tokens:
return pooled, tokens
return pooled
# self.attn_pool(x)
class AttentionalPooler(nn.Module):
def __init__(
self,
d_model: int,
context_dim: int,
n_head: int = 8,
n_queries: int = 256,
norm_layer: Callable = LayerNorm
):
super().__init__()
self.query = nn.Parameter(torch.randn(n_queries, d_model))
self.attn = nn.MultiheadAttention(d_model, n_head, kdim=context_dim, vdim=context_dim)
self.ln_q = norm_layer(d_model)
self.ln_k = norm_layer(context_dim)
def forward(self, x: torch.Tensor):
# ln归一化,NLD -> LND [b, 257, 1024]--->[257, b, 1024]
x = self.ln_k(x).permute(1, 0, 2)
N = x.shape[1]
# q: [256, 768]
q = self.ln_q(self.query)
# q: [256, 768]--->[256, 1, 768]--->[256,b, 768], k=v=x, x:[257, b, 1024]
# out: [256, b, 768], MultiheadAttention
out = self.attn(q.unsqueeze(1).expand(-1, N, -1), x, x, need_weights=False)[0]
# out: [256, b, 768]--->[b, 256, 768]
return out.permute(1, 0, 2) # LND -> NLD
2.2 Unimodal text decoder
def _encode_text(self, text, normalize: bool = True):
# text_latent:[b, 768], token_emb:[b, 76, 768]
text_latent, token_emb = self.text(text)
text_latent = F.normalize(text_latent, dim=-1) if normalize else text_latent
return text_latent, token_emb
def forward(self, text):
cast_dtype = self.transformer.get_cast_dtype()
seq_len = text.shape[1]
# x:[b, 76, 768], 将text:[b, 76]进行embeding, F.embedding(text, weight=[40408, 768])49408---一共49408个单词,每个单词维度768
x = self.token_embedding(text).to(cast_dtype)
attn_mask = self.attn_mask
if self.cls_emb is not None:
seq_len += 1
# 在文本token末尾嵌入cls_token, x:[b, 76, 768] ---> [b, 76+1, 768]
x = torch.cat([x, _expand_token(self.cls_emb, x.shape[0])], dim=1)
# cls_mask: [12b, 77, 77], text:[b, 76]
cls_mask = self.build_cls_mask(text, cast_dtype)
# 将单词有序遮挡mask, attn_mask: [[0, -inf, -inf,...-inf], [0, 0, -inf, ..., -inf],...[0, 0, 0,...,0,-inf], [0, 0, 0, ...,0]]
if attn_mask is not None:
# attn_mask: [1,77, 77] + cls_mask[12b, 77, 77] ===> 获得最终的attn_mask: [12b, 77, 77], 有单词的位置为0, 被遮挡以及没单词的位置为-inf
attn_mask = attn_mask[None, :seq_len, :seq_len] + cls_mask[:, :seq_len, :seq_len]
# 加上位置编码, x: [b, 77, 768]
x = x + self.positional_embedding[:seq_len].to(cast_dtype)
# x: [b, 77, 768]--->[77, b, 768]
x = x.permute(1, 0, 2) # NLD -> LND
# 进入transformer学习, x:[77, b, 768]
x = self.transformer(x, attn_mask=attn_mask)
# x: [77, b, 768]--->[b, 77, 768]
x = x.permute(1, 0, 2) # LND -> NLD
# x.shape = [batch_size, n_ctx, transformer.width]
if self.cls_emb is not None:
# presence of appended cls embed (CoCa) overrides pool_type, always take last token
# pooled: cls_token:[b, 768] tokens:图像token:[b, 76, 768]
pooled, tokens = text_global_pool(x, pool_type='last')
# layernorm
pooled = self.ln_final(pooled) # final LN applied after pooling in this case
# [b, 768] @ 【768, 768】---> [b, 768]
pooled = pooled @ self.text_projection
# pooled:[b, 768], tokens:[b, 76, 768]
if self.output_tokens:
return pooled, tokens
return pooled
def build_cls_mask(self, text, cast_dtype: torch.dtype):
# 找到text中存在单词的cls_mask,值设为True,text:[b, 76], cls_mask: [b, 1, 76]
cls_mask = (text != self.pad_id).unsqueeze(1)
# cls_mask: [b, 1, 76]--->[b, 77, 77]
cls_mask = F.pad(cls_mask, (1, 0, cls_mask.shape[2], 0), value=True)
# 随机一个[b, 77, 77]的mask
additive_mask = torch.empty(cls_mask.shape, dtype=cast_dtype, device=cls_mask.device)
# 全部填充为0 additive_mask:[b, 77, 77]
additive_mask.fill_(0)
# 不满77长度的单词中,0填充的位置换为-inf
additive_mask.masked_fill_(~cls_mask, float("-inf"))
# 将additive_mask在batch维度上重复self.heads(12)次,[b, 77, 77]--->[12b, 77, 77]
additive_mask = torch.repeat_interleave(additive_mask, self.heads, 0)
return additive_mask
2.3 Multimodal text decoder
# logits: [b, 76, 49408], image_embs:caption_embedings[b, 255, 768], token_embs:文本embedings [b, 76, 768]
logits = self.text_decoder(image_embs, token_embs)
# self.text_decoder forward
def forward(self, image_embs, text_embs):
# [b, 76, 768]--->[76, b, 768]
text_embs = text_embs.permute(1, 0, 2)
# [b, 255, 768]--->[255, b, 768]
image_embs = image_embs.permute(1, 0, 2)
# 76
seq_len = text_embs.shape[0]
# cross-attention: q=text_embs, k_x=image_embs, v_x=image_embs
for resblock, cross_attn in zip(self.resblocks, self.cross_attn):
text_embs = resblock(text_embs, attn_mask=self.attn_mask[:seq_len, :seq_len])
# q=text_embs, k_x=image_embs, v_x=image_embs
text_embs = cross_attn(text_embs, k_x=image_embs, v_x=image_embs)
# x: [76, b, 768]--->[b, 76, 768]
x = text_embs.permute(1, 0, 2) # LND -> NLD
# layer_norm
x = self.ln_final(x)
# x: [b, 76, 768] @ [768, 49408] ---> [b, 76, 49408]
if self.text_projection is not None:
x = x @ self.text_projection
# [b, 76, 49408]
return x
2.4 Loss计算
def forward(self, image_features, text_features, logits, labels, logit_scale, output_dict=False):
clip_loss = torch.tensor(0)
# constractive loss
if self.clip_loss_weight:
# image_features: [b, 768], text_features:[b, 768], logit_scale:温度系数
clip_loss = super().forward(image_features, text_features, logit_scale)
clip_loss = self.clip_loss_weight * clip_loss
# caption loss, self.caption_loss:CE loss
caption_loss = self.caption_loss(
logits.permute(0, 2, 1), # [b, 76, 49408]
labels, # [b, 76]
)
caption_loss = caption_loss * self.caption_loss_weight
if output_dict:
return {"contrastive_loss": clip_loss, "caption_loss": caption_loss}
return clip_loss, caption_loss
# clip_loss
def forward(self, image_features, text_features, logit_scale, output_dict=False):
device = image_features.device
# 假设有N个图像-文本对: logits_per_image: [N, N], logits_per_text: [N, N]
logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
# 假设有N个图像-文本对:labels=[0, 1, 2,....N]
labels = self.get_ground_truth(device, logits_per_image.shape[0])
# 总损失 = (图像维度的损失 + 文本维度的损失)/ 2
total_loss = (
F.cross_entropy(logits_per_image, labels) + # 图像维度的损失
F.cross_entropy(logits_per_text, labels) # 文本维度的损失
) / 2
return {"contrastive_loss": total_loss} if output_dict else total_loss

















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









