






在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。
准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
图示表示如下:
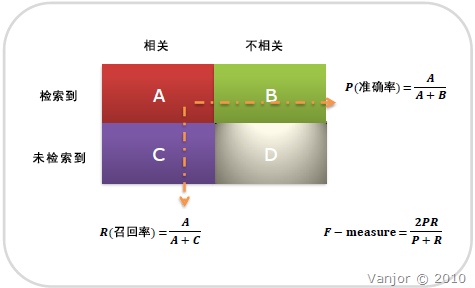
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
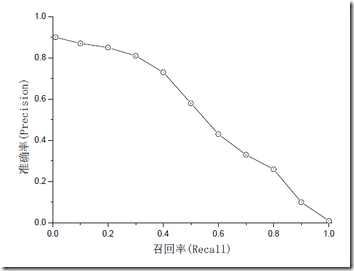
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
[python] view plaincopy
- F1 = 2 * P * R / (P + R)
公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









