






相关文章:
三 推理阶段
在引擎文件构建完成后,接下来是推理,几乎所有推理算法架构都可拆解为以下三个步骤:
- 数据预处理
- 数据推理
- 推理结果后处理
数据前后处理方法由所用的特定模型决定, 但推理由算法架构编译的引擎决定,我们不必关心. 以tensorRT为例,只需对推理引擎指定输入输出节点,然后推理,等待结果即可. 固定的步骤适用于所有模型推理流程.
因此,我们只需针对不同部署模型实现数据前后处理即可.于是考虑设计一个抽象基类,使得具体算法继承基类,然后实现自身前后处理接口, 这样就能使用接口统一规范所有模型部署的调用问题
class Infer {
public:
Infer() = default;
virtual ~Infer() = default;
virtual std::shared_future<batchBoxesType> commit(const InputData *data) {};
virtual int preProcess(BaseParam ¶m, cv::Mat &image, float *pinMemoryCurrentIn) = 0;
virtual int postProcess(BaseParam ¶m, float *pinMemoryCurrentOut, int singleOutputSize, int outputNums, batchBoxesType &result) = 0;
};
上述代码中, Infer是抽象类, 各具体算法需要继承并实现preProcess,postProcess两个方法. 方法commit是另一个重要点,稍后再讲.
四 多线程
在上述推理阶段描述的工作场景中, 预处理,推理,后处理是线性执行的.
比如当模型执行到后处理阶段, 预处理和推理都是停止状态. 为提升效率,这里引入多线程方法. 即预处理,推理,后处理各是一个独立线程. 每个线程只处理从前一个步骤接收的数据,处理后放入共享队列, 等下一个节点去取用. 没有数据处理则进入等待状态. 三个线程同时工作, 效率会高很多.
那么这时需要考虑以下几个问题:
- 加工好的数据要占用内存和显存, 那么队列长度长度上限设为多少好呢? 这里设为1, 即队列中最多有1个batchsize加工好的数据等待,由于batchsize在初始化时才指定,因此所需内存/显存要在运行时才知道
方法commit是预处理线程的数据入口, 它们之间的关系图如下:
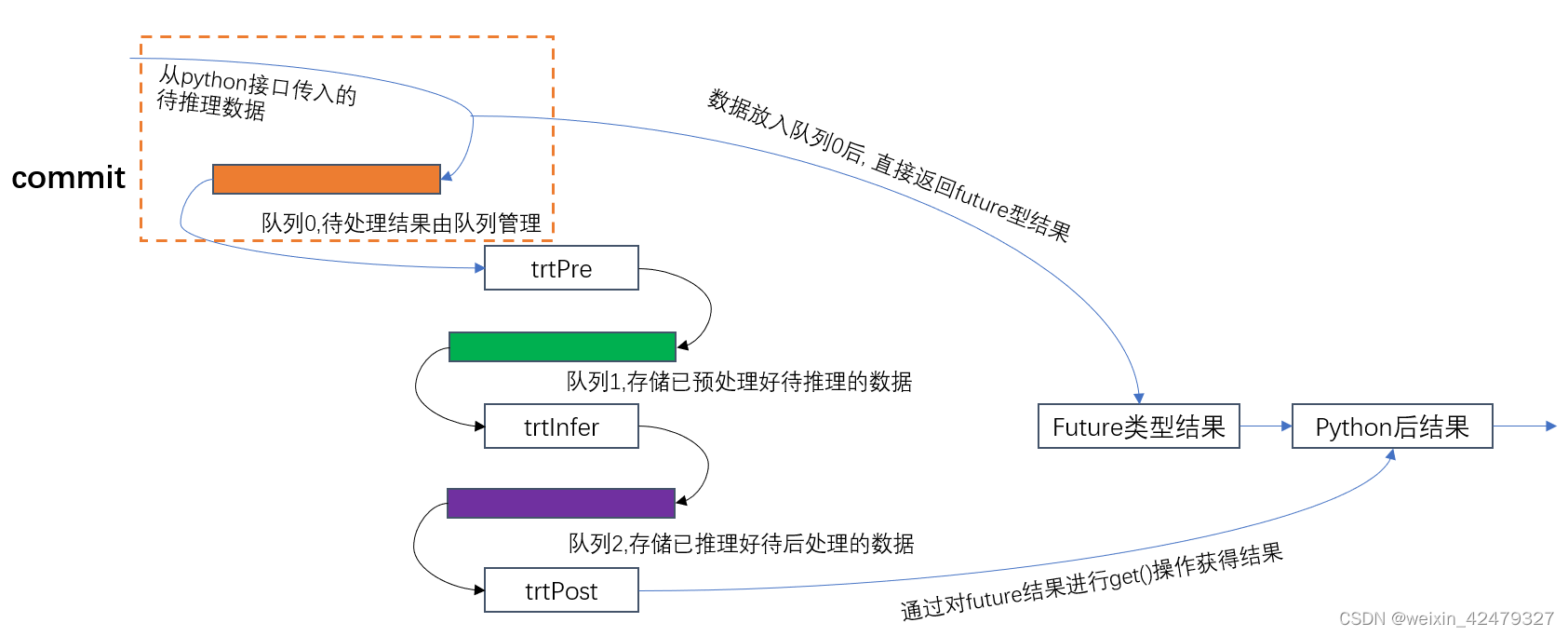 commit作用就是接受待推理数据并放入队列0中, 然后直接返回future型异步结果, 后处理结果通过.get()方法(C++ promise/future语法)在python中获得.
commit作用就是接受待推理数据并放入队列0中, 然后直接返回future型异步结果, 后处理结果通过.get()方法(C++ promise/future语法)在python中获得.
trtPre,trtInfer,trtPost三个线程持续运行, 无数据处理就进入等待状态. 当队列0有数据, 就会依次激活这三个线程
在上面描述的接口Infer中,可以使用接口模式+RAII方式实现(两种设计模式,这里不赘述,大意是不需要用户操作的代码全部隐藏起来,仅暴露必需的部分)
对Infer的具体实现如下:
class InferImpl : public Infer {
public:
explicit InferImpl(std::vector<int> &memory);
~InferImpl() override;
// 创建推理engine
static bool getEngineContext(BaseParam &curParam);
static std::vector<int> setBatchAndInferMemory(BaseParam &curParam);
/
// static unsigned long getInputNums(const InputData &data);
// 从队列中获得用于处理的图片数据
// void preMatRead(std::vector<cv::Mat> &mats, const futureJob &fJob);
// preProcess,postProcess空实现,具体实现由实际继承Infer.h的应用完成
int preProcess(BaseParam ¶m, cv::Mat &image, float *pinMemoryCurrentIn) override {};
int postProcess(BaseParam ¶m, float *pinMemoryCurrentOut, int singleOutputSize, int outputNums, batchBoxesType &result) override {};
// 具体应用调用commit方法,推理数据传入队列, 直接返回future对象. 数据依次经过trtPre,trtInfer,trtPost三个线程,结果通过future.get()获得
std::shared_future<batchBoxesType> commit(const InputData *data) override;
// 将待推理数据写入队列1, 会调用上述由具体应用实现的preProcess
void trtPre(BaseParam &curParam, Infer *curFunc);
// 从队列1取数据进行推理,然后将推理结果写入队列2
void trtInfer(BaseParam &curParam);
// 从队列2取数据,进行后处理, 会调用上述由具体应用实现的postProcess
void trtPost(BaseParam &curParam, Infer *curFunc);
bool startThread(BaseParam &curParam, Infer &curFunc);
private:
// lock1用于预处理写入+推理时取出
std::mutex lock1;
// lock2用于推理后结果写入+后处理取出
std::mutex lock2;
std::condition_variable cv_;
float *gpuMemoryIn0 = nullptr, *gpuMemoryIn1 = nullptr, *pinMemoryIn = nullptr;
float *gpuMemoryOut0 = nullptr, *gpuMemoryOut1 = nullptr, *pinMemoryOut = nullptr;
float *gpuIn[2]{}, *gpuOut[2]{};
std::vector<int> memory;
// 读取从路径读入的图片矩阵
cv::Mat mat;
std::queue<Job> qPreJobs;
// 存储每个batch的推理结果,统一后处理
std::queue<Out> qPostJobs;
futureJob fJob;
std::queue<futureJob> qfJobs;
// 记录传入的图片数量
std::queue<int> qfJobLength;
std::queue<std::shared_ptr<std::promise<batchBoxesType>>> qBatchBoxes;
std::atomic<bool> preFinish{false}, inferFinish{false}, workRunning{true};
std::shared_ptr<std::thread> preThread, inferThread, postThread;
//创建cuda任务流,对应上述三个处理线程
cudaStream_t preStream{}, inferStream{}, postStream{};
};
该实现类中最主要方法是commit,trtPre,trtInfer,trtPost和startThread, 属性中各种必需的变量和队列,结构体,结构体定义在外部,具体定义在完整代码中有详细说明.
preProcess,postProcess对应具体算法的前后处理,由各自算法实现, 并在trtPre和trtPost中调用,因此这里仅给出空实现.
- 关于commit具体实现如下:
// batchBoxesType 定义
using batchBoxesType = std::vector<std::vector<std::vector<float>>>;
std::shared_future<batchBoxesType> InferImpl::commit(const InputData *data) {
//std::shared_future <batchBoxesType> InferImpl::commit(const std::vector <cv::Mat> &images) {
// 将传入的多张或一张图片,一次性传入队列总
unsigned long len = !data->mats.empty() ? data->mats.size() : data->gpuMats.size();
if (0 == len) std::thread();
futureJob fJob2;
fJob2.mats = data->mats;
fJob2.gpuMats = data->gpuMats;
// 两种方法都可以实现初始化,make_shared更好?
fJob2.batchResult = std::make_shared<std::promise<batchBoxesType>>();
// fJob.batchResult.reset(new std::promise<batchBoxesType>());
// 创建share_future变量,一次性取回传入的所有图片结果, 不能直接返回xx.get_future(),会报错
std::shared_future<batchBoxesType> future = fJob2.batchResult->get_future();
{
std::lock_guard<std::mutex> l1(lock1);
qfJobLength.emplace(len);
// qBatchBoxes.emplace(fJob2.batchResult);
qfJobs.emplace(std::move(fJob2));
}
// 通知图片预处理线程,图片已就位.
cv_.notify_all();
return future;
}
考虑到以后可能要处理直接读入到GPU上的数据, 这里把数据由结构体统一管理
该方法功能如下:
- 对接收结果的变量batchResult 使用promise初始化, 之后通过.get_future()方法获得share_future类型结果,并直接返回.
- 将数据加入到队列0(qfJobs)中,接下来工作就交由trtPre,trtInfer,trtPost三个线程完成.
当然, 这三个线程要在初始化阶段就启动起来:
bool InferImpl::startThread(BaseParam &curParam, Infer &curFunc) {
try {
preThread = std::make_shared<std::thread>(&InferImpl::trtPre, this, std::ref(curParam), &curFunc);
inferThread = std::make_shared<std::thread>(&InferImpl::trtInfer, this, std::ref(curParam));
postThread = std::make_shared<std::thread>(&InferImpl::trtPost, this, std::ref(curParam), &curFunc);
} catch (std::string &error) {
printf("thread start fail: %s !\n", error.c_str());
return false;
}
printf("thread start success !\n");
return true;
}
三个线程分别对应推理前预处理,推理过程,推理数据后处理,这三个线程并行处理,线程间通过队列传递数据.















 7240
7240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









