






来自香港科技大学,清华大学的研究者提出了「GenN2N」,一个统一的生成式NeRF-to-NeRF的转换框架,适用于各种NeRF转换任务,例如文字驱动的NeRF编辑、着色、超分辨率、修复等,性能均表现极其出色!
论文地址:https://arxiv.org/abs/2404.02788
主页:https://xiangyueliu.github.io/GenN2N/
Github:github.com/Lxiangyue/GenN2N
近年来,神经辐射场(NeRF)因其紧凑、高质量、多功能性在三维重建、三维生成和新视角合成领域引起了广泛关注。然而,一旦创建了NeRF场景,这些方法通常缺乏对生成几何和外观的进一步控制。因此,NeRF编辑(NeRF Editing)最近成为了一个值得关注的研究重点。
目前的NeRF编辑方法通常是针对特定任务的,例如NeRF的文本驱动编辑、超分辨率、修复和着色。这些方法需要大量的特定任务领域知识。而在2D图像编辑领域,开发通用的图像到图像(Image-to-image)转换方法成为一种趋势,例如利用2D生成模型stable difussion支持多功能的图像编辑。因此,我们提出了利用基础的2D生成模型进行通用的NeRF编辑。
随之而来的挑战是NeRF和2D图像之间的表示差距,尤其是图像编辑器通常会为不同视角生成多种不一致的编辑。最近的一种基于文本的NeRF编辑方法Instruct-NeRF2NeRF对此进行了探究。其采用“渲染-编辑-聚合”的流程,通过逐步渲染多视角图像、编辑这些图像,将编辑图像聚合到NeRF中逐步更新NeRF场景。然而这种编辑方法,针对特定的编辑需求,经过大量的优化,只能生成一种特定编辑的结果,如果用户不满意则需要反复迭代尝试。
因此,我们提出了「GenN2N」,一种适用于多种NeRF编辑任务的NeRF-to-NeRF通用框架,其核心在于用生成的方式来刻画编辑过程多解性,使其可以借助生成式编辑轻松产生大量符合要求的编辑结果供用户挑选。
在GenN2N的核心部分,1)引入了3D VAE-GAN的生成式框架,使用VAE来表征整个编辑空间,来学习与一组输入的2D编辑图像对应的所有可能的3D NeRF编辑的分布,并用GAN为编辑NeRF的不同视图提供合理的监督,确保编辑结果的真实性,2)使用对比学习解耦编辑内容和视角,确保不同视角间的编辑内容一致性,3)在推理时,用户简单地从条件生成模型中随机地采样出多个编辑码,就可以生成与编辑目标对应的各种3D编辑结果。
相比于各种NeRF编辑任务的SOTA方法(ICCV2023 Oral等),GenN2N在编辑质量、多样性、效率等方面均优于已有方法。
方法介绍
我们首先进行2D图像编辑,然后将这些2D编辑提升到3D NeRF来实现生成式的NeRF-to-NeRF的转换。
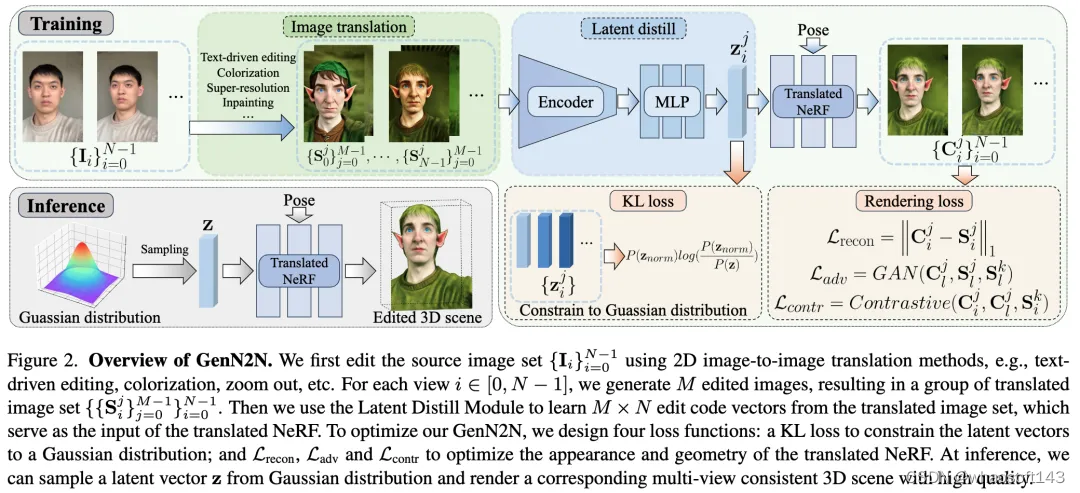
A. 隐式蒸馏(Latent Distill)
我们用Latent Distill Module作为VAE的encoder,为每张编辑图像学习一个隐式的编辑码,在NeRF-to-NeRF转换中通过此编辑码控制生成的内容。所有编辑码在KL loss的约束下服从于一个良好的正态分布,以便更好地采样。为了解耦编辑内容和视角,我们精心设计了对比学习,鼓励相同编辑风格视角不同的图片的编辑码相近,不同编辑风格但视角相同的图片的编辑码互相远离。
B. NeRF-to-NeRF的转换(Translated NeRF)
我们用NeRF-to-NeRF Translation作为VAE的decoder,其以编辑码作为输入,将原始的NeRF修改为一个转换NeRF。我们在原NeRF网络隐藏层之间添加了残差层,这些残差层以编辑码作为输入来调制隐藏层神经元,使得转换NeRF既能够保留原本NeRF的信息,又可以根据编辑码来控制转换3D内容。同时,NeRF-to-NeRF Translation也作为生成器参与生成对抗训练。通过生成而非优化的方式,使得我们可以一次性得到多种转换结果,显著提升了NeRF转换效率和结果多样性。
C. 条件判别器(Conditional Discriminator)
转换NeRF的渲染图片构成了需要判别的生成空间,这些图片的编辑风格、渲染视角各异,导致生成空间非常复杂。因此我们提供一个condition作为判别器的额外信息。具体而言,判别器在鉴别生成器的渲染图片Cj(负样本)或训练数据中的编辑图片Sj(正样本)时,我们都从训练数据中再挑选一张相同视角的编辑图片Sk作为条件,这使得判别器在鉴别正负样本时不会受到视角因素的干扰。
D. 推理(Inference)
在GenN2N优化后,用户可以从正态分布中随机采样出编辑码,输入转换NeRF即可生成出编辑后的高质量、多视角一致性的3D NeRF场景。
实验
我们在多种NeRF-to-NeRF任务上进行了大量的实验,包括NeRF的文本驱动编辑、着色、超分辨率、修复等。实验结果展示了GenN2N卓越的编辑质量、多视角一致性、生成的多样性、和编辑效率。
A. 基于文本的NeRF编辑
B. NeRF着色
C. NeRF超分辨率
D. NeRF修复
视频太大发不了..
对比实验
我们的方法与各种特定NeRF任务的SOTA方法进行了定性和定量对比(包括文本驱动编辑、着色、超分辨率和修复等)。结果表明,GenN2N作为一个通用框架,其表现与特定任务SOTA相当或者更好,同时编辑结果具有更强的多样性(如下是GenN2N与Instruct-NeRF2NeRF在基于文本的NeRF编辑任务上的对比)。
A. 基于文本的NeRF编辑















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









