






GenN2N: Generative NeRF2NeRF Translation
GenN2N:生成NeRF2NeRF翻译
相约刘寒雪 2 昆明罗平谭 2 李毅 2, 3, 4 2
1 Hong Kong University of Science and Technology 2 Tsinghua University
香港科技大学 2 清华大学
3 Shanghai Artificial Intelligence Laboratory 4 Shanghai Qi Zhi Institute
3 上海人工智能实验室 4 上海启智研究院
Abstract 摘要 GenN2N: Generative NeRF2NeRF Translation
We present GenN2N, a unified NeRF-to-NeRF translation framework for various NeRF translation tasks such as text-driven NeRF editing, colorization, super-resolution, inpainting, etc. Unlike previous methods designed for individual translation tasks with task-specific schemes, GenN2N achieves all these NeRF editing tasks by employing a plug-and-play image-to-image translator to perform editing in the 2D domain and lifting 2D edits into the 3D NeRF space. Since the 3D consistency of 2D edits may not be assured, we propose to model the distribution of the underlying 3D edits through a generative model that can cover all possible edited NeRFs. To model the distribution of 3D edited NeRFs from 2D edited images, we carefully design a VAE-GAN that encodes images while decoding NeRFs. The latent space is trained to align with a Gaussian distribution and the NeRFs are supervised through an adversarial loss on its renderings. To ensure the latent code does not depend on 2D viewpoints but truly reflects the 3D edits, we also regularize the latent code through a contrastive learning scheme. Extensive experiments on various editing tasks show GenN2N, as a universal framework, performs as well or better than task-specific specialists while possessing flexible generative power. More results on our project page: GenN2N: Generative NeRF2NeRF Translation.
我们提出了GenN 2N,一个统一的NeRF到NeRF翻译框架,用于各种NeRF翻译任务,如文本驱动的NeRF编辑,着色,超分辨率,修复等。GenN 2N通过采用即插即用的图像到图像转换器在2D域中执行编辑并将2D编辑提升到3D NeRF空间中。由于2D编辑的3D一致性可能无法保证,我们建议通过生成模型来模拟底层3D编辑的分布,该模型可以覆盖所有可能的编辑NeRF。为了从2D编辑图像中对3D编辑NeRF的分布进行建模,我们仔细设计了一个VAE-GAN,它在解码NeRF的同时对图像进行编码。训练潜在空间以与高斯分布对齐,并通过其渲染上的对抗性损失来监督NeRF。 为了确保潜在代码不依赖于2D视点,而是真实地反映3D编辑,我们还通过对比学习方案来正则化潜在代码。在各种编辑任务上的大量实验表明,GenN2N作为一个通用的框架,在具有灵活的生成能力的同时,表现得与特定任务的专家一样好或更好。更多结果请访问我们的项目页面:https://xiangyueliu.github.io/GenN2N/。
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/89df7c83a7bfd2cba89d3b6f1933e97d.png)
Figure 1:We introduce GenN2N, a unified framework for NeRF-to-NeRF translation, enabling a range of 3D NeRF editing tasks, including text-driven editing, colorization, super-resolution, inpainting, etc. We show at least two rendering views of edited NeRF scenes at inference time. Given a 3D NeRF scene, GenN2N can produce high-quality editing results with suitable multi-view consistency.
图一:我们介绍GenN2N,NeRF到NeRF翻译的统一框架,实现了一系列3D NeRF编辑任务,包括文本驱动编辑,着色,超分辨率,修复等。给定一个3D NeRF场景,GenN2N可以产生具有适当多视图一致性的高质量编辑结果。
1Introduction 1介绍
Over the past few years, Neural radiance fields (NeRFs) [25] have brought a promising paradigm in the realm of 3D reconstruction, 3D generation, and novel view synthesis due to their unparalleled compactness, high quality, and versatility. Extensive research efforts have been devoted to creating NeRF scenes from 2D images [23, 43, 4, 39, 21] or just text [28, 14] input. However, once the NeRF scenes have been created, these methods often lack further control over the generated geometry and appearance. NeRF editing has therefore become a notable research focus recently.
在过去的几年里,神经辐射场(NeRFs)[ 25]由于其无与伦比的紧凑性,高质量和多功能性,在3D重建,3D生成和新颖的视图合成领域带来了一个有前途的范例。广泛的研究工作致力于从2D图像[23,43,4,39,21]或仅文本[28,14]输入创建NeRF场景。然而,一旦创建了NeRF场景,这些方法通常缺乏对生成的几何形状和外观的进一步控制。因此,NeRF编辑最近成为一个值得注意的研究热点。
Existing NeRF editing schemes are usually task-specific. For example, researchers have developed NeRF-SR [37], NeRF-In [20], PaletteNeRF [17] for NeRF super-resolution, inpainting, and color-editing respectively. These designs require a significant amount of domain knowledge for each specific task. On the other hand, in the field of 2D image editing, a growing trend is to develop universal image-to-image translation methods to support versatile image editing [27, 48, 31]. By leveraging foundational 2D generative models, e.g., stable diffusion [30], these methods achieve impressive editing results without task-specific customization or tuning. We then ask the question: can we conduct universal NeRF editing leveraging foundational 2D generative models as well?
现有的NeRF编辑方案通常是特定于任务的。例如,研究人员已经开发了NeRF-SR [ 37],NeRF-In [ 20],PaletteNeRF [ 17]分别用于NeRF超分辨率,修复和颜色编辑。这些设计需要大量的领域知识来完成每个特定的任务。另一方面,在2D图像编辑领域,一个不断增长的趋势是开发通用的图像到图像转换方法,以支持通用的图像编辑[ 27,48,31]。通过利用基础2D生成模型,例如,稳定的扩散[ 30],这些方法实现了令人印象深刻的编辑结果,而无需特定于任务的定制或调整。然后,我们提出了一个问题:我们是否也可以利用基本的2D生成模型进行通用NeRF编辑?
The first challenge is the representation gap between NeRFs and 2D images. It is not intuitive how to leverage image editing tools to edit NeRFs. A recent text-driven NeRF editing method [10] has shed some light on this. The method adopts a “render-edit-aggregate” pipeline. Specifically, it gradually updates a NeRF scene by iteratively rendering multi-view images, conducting text-driven visual editing on these images, and finally aggregating the edits in the NeRF scene. It seems that replacing the image editing tool with a universal image-to-image translator could lead to a universal NeRF editing method. However, the second challenge would then come. Image-to-image translators usually generate diverse and inconsistent edits for different views, e.g. turning a man into an elf might or might not put a hat on his head, making edits aggregation intricate. Regarding this challenge, Instruct-NeRF2NeRF [10] presents a complex optimization technique to pursue unblurred NeRF with inconsistent multi-view edits. Due to its complexity, the optimization cannot ensure the robustness of the outcomes. Additionally, the unique optimization outcome fails to reflect the stochastic nature of NeRF editing. Users typically anticipate a variety of edited NeRFs just like the diverse edited images.
第一个挑战是NeRF和2D图像之间的表示差距。如何利用图像编辑工具来编辑NeRF并不直观。最近的一种文本驱动的NeRF编辑方法[10]对此有一些启示。该方法采用"渲染—编辑—聚合"流水线。具体来说,它通过迭代地渲染多视图图像,对这些图像进行文本驱动的视觉编辑,并最终聚合NeRF场景中的编辑来逐步更新NeRF场景。似乎用通用的图像到图像翻译器取代图像编辑工具可以产生通用的NeRF编辑方法。然而,第二个挑战就来了。图像到图像翻译器通常会为不同的视图生成不同且不一致的编辑,例如,将一个人变成一个精灵可能会或可能不会在他的头上戴上帽子,使编辑聚合复杂。 关于这一挑战,Instruct-NeRF 2NeRF [ 10]提出了一种复杂的优化技术,以实现不模糊的NeRF和不一致的多视图编辑。由于其复杂性,优化不能确保结果的鲁棒性。此外,独特的优化结果未能反映NeRF编辑的随机性质。用户通常会期待各种编辑的NeRF,就像各种编辑的图像一样。
To tackle the challenges above, we propose GenN2N, a unified NeRF-to-NeRF translation framework for various NeRF editing tasks such as text-driven editing, colorization, super-resolution, inpainting (see Fig. 1). In contrast to Instruct-NeRF2NeRF which adopts a “render-edit-aggregate” pipeline, we first render a NeRF scene into multi-view images, then exploit an image-to-image translator to edit different views, and finally learn a generative model to depict the distribution of NeRF edits. Instead of aggregating all the image edits to form a single NeRF edit, our key idea is to embrace the stochastic nature of content editing by modeling the distribution of the edits in the 3D NeRF space.
为了解决上述挑战,我们提出了GenN 2N,一个统一的NeRF到NeRF翻译框架,用于各种NeRF编辑任务,如文本驱动编辑,着色,超分辨率,修复(见图1)。与采用“render-edit-aggregate”流水线的Instruct-NeRF 2NeRF相比,我们首先将NeRF场景渲染成多视图图像,然后利用图像到图像翻译器编辑不同的视图,最后学习生成模型来描述NeRF编辑的分布。我们的关键思想不是聚合所有图像编辑以形成单个NeRF编辑,而是通过对3D NeRF空间中编辑的分布进行建模来拥抱内容编辑的随机性。
Specifically given a NeRF model or its multi-view images, along with the editing goal, we first generate edited multi-view images using a plug-and-play image-to-image translator. Each view corresponds to a unique 3D edit with some geometry or appearance variations. Conditioned on the input NeRF, GenN2N trains a conditional 3D generative model to reflect such content variations. At the core of GenN2N, we design a 3D VAE-GAN that incorporates a differentiable volume renderer to connect 3D content creation with 2D GAN losses, ensuring that the inconsistent multi-view renderings can still help each other regarding 3D generation. Moreover, we introduce a contrastive learning loss to ensure that the 3D content variation can be successfully understood just from edited 2D images without being influenced by the camera viewpoints. During inference, users can simply sample from the conditional generative model to obtain various 3D editing results aligned with the editing goal. We have conducted experiments on human, items, indoor and outdoor scenes for various editing tasks such as text-driven editing, colorization, super-resolution and inpainting, demonstrating the effectiveness of GenN2N in supporting diverse NeRF editing tasks while keeping the multi-view consistency of the edited NeRF.
特别是给定NeRF模型或其多视图图像,沿着编辑目标,我们首先使用即插即用的图像到图像转换器生成编辑的多视图图像。每个视图对应于具有一些几何形状或外观变化的唯一3D编辑。在输入NeRF的条件下,GenN 2N训练条件3D生成模型以反映此类内容变化。在GenN 2N的核心,我们设计了一个3D VAE-GAN,它结合了一个可区分的体积渲染器,将3D内容创建与2D GAN损失联系起来,确保不一致的多视图渲染仍然可以在3D生成方面相互帮助。此外,我们引入了一个对比学习损失,以确保3D内容的变化可以成功地理解只是从编辑的2D图像,而不受相机的视点。在推理过程中,用户可以简单地从条件生成模型中采样,以获得与编辑目标一致的各种3D编辑结果。 我们已经对人类,物品,室内和室外场景进行了各种编辑任务的实验,例如文本驱动编辑,着色,超分辨率和修复,证明了GenN2N在支持各种NeRF编辑任务的同时保持编辑后NeRF的多视图一致性的有效性。
We summarize the contribution of this paper as follows,
我们总结本文的贡献如下,
- •
A generative NeRF-to-NeRF translation formulation for the universal NeRF editing task together with a generic solution;
·用于通用NeRF编辑任务的生成NeRF到NeRF翻译公式以及通用解决方案; - •
a 3D VAE-GAN framework that can learn the distribution of all possible 3D NeRF edits corresponding to the a set of input edited 2D images;
·3D VAE-GAN框架,其可以学习与输入的编辑的2D图像的集合相对应的所有可能的3D NeRF编辑的分布; - •
a contrastive learning framework that can disentangle the 3D edits and 2D camera views from edited images;
·对比学习框架,其可以将3D编辑和2D相机视图与编辑的图像分离; - •
extensive experiments demonstrating the superior efficiency, quality, and diversity of the NeRF-to-NeRF translation results.
·大量实验证明NeRF到NeRF翻译结果的上级效率、质量和多样性。
2Related Work 2相关工作
NeRF Editing. Previous works such as EditNeRF [22] propose a conditional neural field that enables shape and appearance editing in the latent space. PaletteNeRF [17, 40] focuses on controlling color palette weights to manipulate appearance. Other approaches utilize bounding boxes [46], meshes [44], point clouds [6], key points [50], or feature volumes [19] to directly manipulate the spatial representation of NeRF. However, these methods either heavily rely on user interactions or have limitations in terms of spatial deformation and color transfer capabilities.
NeRF编辑先前的工作,如EditNeRF [ 22]提出了一个条件神经场,可以在潜在空间中编辑形状和外观。PaletteNeRF [ 17,40]专注于控制调色板权重以操纵外观。其他方法利用边界框[ 46],网格[ 44],点云[ 6],关键点[ 50]或特征体积[ 19]来直接操纵NeRF的空间表示。然而,这些方法要么严重依赖于用户交互,要么在空间变形和颜色转移能力方面具有限制。
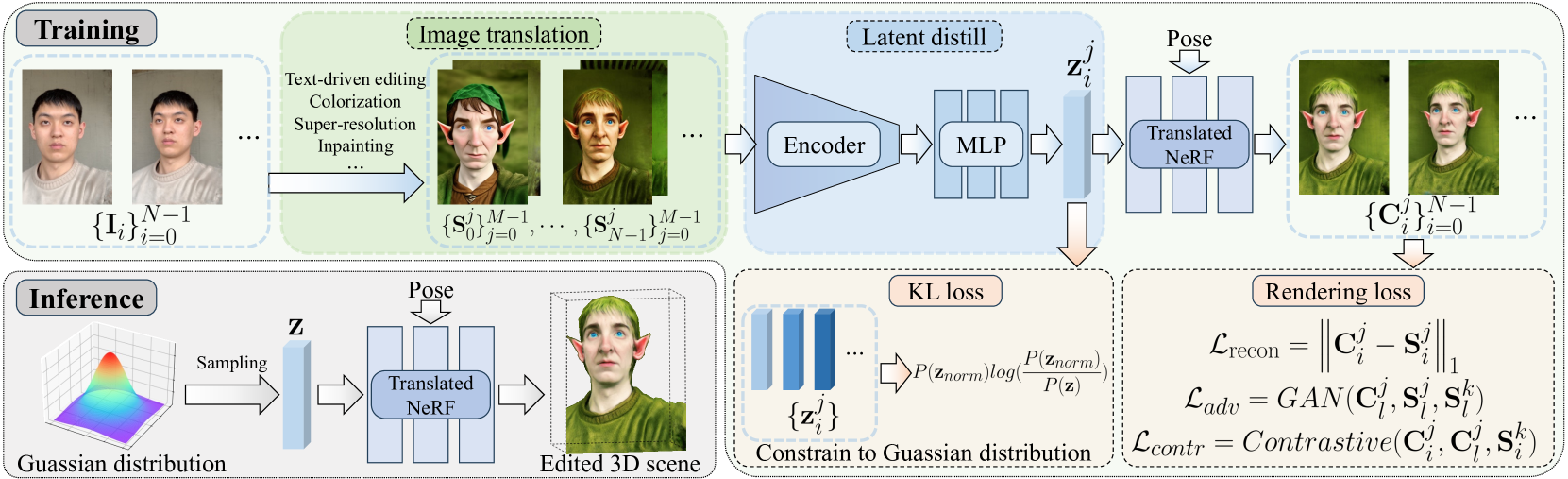
Figure 2:Overview of GenN2N. We first edit the source image set {𝐈𝑖}𝑖=0𝑁−1 using 2D image-to-image translation methods, e.g., text-driven editing, colorization, zoom out, etc. For each view 𝑖∈[0,𝑁−1], we generate 𝑀 edited images, resulting in a group of translated image set {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1. Then we use the Latent Distill Module to learn 𝑀×𝑁 edit code vectors from the translated image set, which serve as the input of the translated NeRF. To optimize our GenN2N, we design four loss functions: a KL loss to constrain the latent vectors to a Gaussian distribution; and ℒrecon, ℒadv and ℒcontr to optimize the appearance and geometry of the translated NeRF. At inference, we can sample a latent vector 𝐳 from Gaussian distribution and render a corresponding multi-view consistent 3D scene with high quality.
图2:GenN 2N概述。我们首先使用2D图像到图像转换方法编辑源图像集 {𝐈𝑖}𝑖=0𝑁−1 ,例如,文本驱动编辑、彩色化、缩小等。对于每个视图 𝑖∈[0,𝑁−1] ,我们生成 𝑀 编辑的图像,从而产生一组转换的图像集 {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1 。然后,我们使用Latent Distill模块从翻译后的图像集学习 𝑀×𝑁 编辑代码向量,这些代码向量用作翻译后的NeRF的输入。为了优化我们的GenN 2N,我们设计了四个损失函数:KL损失将潜在向量约束为高斯分布; ℒrecon , ℒadv 和 ℒcontr 优化翻译后的NeRF的外观和几何形状。在推理时,我们可以从高斯分布中采样潜在向量 𝐳 ,并以高质量渲染相应的多视图一致的3D场景。
NeRF Stylization. Images-referenced stylization [13, 7, 47] often prioritize capturing texture style rather than detailed content, resulting in imprecise editing appearance of NeRF only. Text-guided works [38, 36], on the other hand, apply contrastive losses based on CLIP [29] to achieve the desired edits. While text references usually describe the global characteristics of the edited results, instructions offer a more convenient and precise expression.
NeRF程式化。图像参考风格化[13,7,47]通常优先捕获纹理风格而不是详细内容,导致仅NeRF的编辑外观不精确。另一方面,文本引导的作品[ 38,36]应用基于CLIP [ 29]的对比损失来实现所需的编辑。虽然文本引用通常描述编辑结果的全局特征,但说明提供了更方便和精确的表达。
Instruct-driven NeRF editing. Among numerous image-to-image translation works, InstructPix2Pix [2] stands out by efficiently editing images following instructions. It leverages large pre-trained models in the language and image domains [3, 30] to generate paired data (before and after editing) for training. While editing NeRF solely based on edited images is problematic due to multi-view inconsistency. To address this, an intuitive yet heavy approach [10] is to iteratively edit the image and optimize NeRF. In addition, NeRF-Art [38] and DreamEditor [51] adopt a CLIP-based contrastive loss [29] and score distillation sampling [28] separately to supervise the optimization of editing NeRF. Inspired by Generative Radiance Fields [32, 5], We capture various possible NeRF editing in the generative space to solve it.
指令驱动的NeRF编辑。在众多的图像到图像翻译作品中,InstructPix 2 Pix [ 2]通过按照指令有效地编辑图像而脱颖而出。它利用语言和图像域中的大型预训练模型[ 3,30]来生成用于训练的配对数据(编辑前后)。而编辑NeRF仅基于编辑的图像是有问题的,由于多视图不一致。为了解决这个问题,一个直观但繁重的方法[ 10]是迭代编辑图像并优化NeRF。此外,NeRF-Art [ 38]和DreamEditor [ 51]分别采用基于CLIP的对比损失[ 29]和分数蒸馏采样[ 28]来监督编辑NeRF的优化。受生成辐射场[ 32,5]的启发,我们在生成空间中捕获各种可能的NeRF编辑来解决它。
3Method 3方法
Given a NeRF scene, we present a unified framework GenN2N to achieve various editing on the 3D scene leveraging geometry and texture priors from 2D image editing methods, such as text-driven editing, colorization, super-resolution, inpainting, etc. While a universal image-to-image translator can theoretically accomplish these 2D editing tasks, we actually use a state-of-the-art translator for each task. Therefore, we formulate each 2D image editing method as a plug-and-play image-to-image translator and all NeRF editing tasks as our universal NeRF-to-NeRF translation, in which the given NeRF is translated into NeRF scenes with high rendering quality and 3D geometry consistency according to the user-selected editing target. The overview of GenN2N is illustrated in Fig. 2, we first perform image-to-image translation in the 2D domain and then lift 2D edits to 3D and achieve NeRF-to-NeRF translation.
给定一个NeRF场景,我们提出了一个统一的框架GenN2N,以实现各种编辑的3D场景利用几何和纹理先验的2D图像编辑方法,如文本驱动的编辑,着色,超分辨率,修补等,而一个通用的图像到图像的翻译器理论上可以完成这些2D编辑任务,我们实际上使用一个国家的最先进的翻译器为每个任务。因此,我们将每个2D图像编辑方法制定为即插即用的图像到图像翻译器,并将所有NeRF编辑任务制定为我们的通用NeRF到NeRF翻译,其中给定的NeRF根据用户选择的编辑目标被翻译为具有高渲染质量和3D几何一致性的NeRF场景。GenN2N的概述如图2所示,我们首先在2D域中执行图像到图像的转换,然后将2D编辑提升到3D并实现NeRF到NeRF的转换。
Given 𝑁 multi-view images {𝐈𝑖}𝑖=0𝑁−1 of a scene, we first use Nerfstudio [35] to train the original NeRF. Then we use a plug-and-play image-to-image translator to edit these source images. However, the content generated by the 2D translator may be inconsistent among multi-view images. For example, using different initial noise, the 2D translator [1] may generate different content for image editing, which makes it difficult to ensure the 3D consistency between different view directions in the 3D scene.
给定场景的 𝑁 多视图图像 {𝐈𝑖}𝑖=0𝑁−1 ,我们首先使用Nerfstudio [ 35]来训练原始NeRF。然后,我们使用即插即用的图像到图像翻译器来编辑这些源图像。然而,由2D转换器生成的内容在多视图图像之间可能不一致。例如,使用不同的初始噪声,2D翻译器[ 1]可能会生成不同的内容用于图像编辑,这使得难以确保3D场景中不同视图方向之间的3D一致性。
To ensure the 3D consistency and rendering quality, we propose to model the distribution of the underlying 3D edits through a generative model that can cover all possible edited NeRFs, by learning an edit code for each edited image so that the generated content can be controlled by this edit code during the NeRF-to-NeRF translation process.
为了确保3D一致性和渲染质量,我们建议通过生成模型来建模底层3D编辑的分布,该生成模型可以覆盖所有可能的编辑NeRF,通过学习每个编辑图像的编辑代码,以便在NeRF到NeRF翻译过程中可以通过此编辑代码控制生成的内容。
For each view ∈[0,𝑁−1], we generate 𝑀 edited images, resulting in a group of the translated image set {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1. Then we design a Latent Distill Module described in Sec. 3.1 to map each translated image 𝐒𝑖𝑗 into an edit code vector 𝐳𝑖𝑗 and design a KL loss ℒKL to constrain those edit code vectors to a Gaussian distribution. Conditioned on the edit code 𝐳𝑖𝑗, we perform NeRF-to-NeRF translation in Sec. 3.2 by rendering multi-view images {𝐂𝑖}𝑖=0𝑁−1 and optimize the translated NeRF by three loss functions: the reconstruction loss ℒrecon, the adversarial loss ℒAD, and the contrastive loss ℒcontr. After the optimization of the translated NeRF, as described in Sec. 3.3, we can sample an edit code 𝐳 from Gaussian distribution and render the corresponding edited 3D scene with high quality and multi-view consistency in the inference stage.
对于每个视图 ∈[0,𝑁−1] ,我们生成 𝑀 编辑的图像,从而产生一组转换的图像集 {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1 。然后,我们设计了一个潜在的蒸馏模块,在第二节中描述。3.1将每个转换后的图像 𝐒𝑖𝑗 映射到编辑代码向量 𝐳𝑖𝑗 ,并设计KL损失 ℒKL 以将这些编辑代码向量约束为高斯分布。在编辑代码 𝐳𝑖𝑗 的条件下,我们在Sec. 3.2通过渲染多视图图像 {𝐂𝑖}𝑖=0𝑁−1 ,并通过三个损失函数优化翻译的NeRF:重建损失 ℒrecon 、对抗损失 ℒAD 和对比损失 ℒcontr 。在优化翻译后的NeRF,如第二节所述。3.3,我们可以从高斯分布中采样编辑代码 𝐳 ,并在推理阶段以高质量和多视图一致性渲染相应的编辑后的3D场景。

Figure 3:Illustration of our proposed contrastive loss functions. Regarding the multi-view rendered images 𝐂𝑖𝑗 and 𝐂𝑙𝑗 sharing the same edit code, we resend them to our Latent Distill Module to extract 𝐳𝑖𝑗 and 𝐳𝑙𝑗, and aggregate them via ℒcontratt. In addition, for 𝐒𝑖𝑘 whose editing style vary from 𝐒𝑖𝑗, ℒcontrrep increase the distance between edit codes of them.
图3:我们提出的对比损失函数的说明。关于共享相同编辑代码的多视图渲染图像 𝐂𝑖𝑗 和 𝐂𝑙𝑗 ,我们将它们重新发送到我们的潜在提取模块以提取 𝐳𝑖𝑗 和 𝐳𝑙𝑗 ,并通过 ℒcontratt 聚合它们。此外,对于编辑风格与#6不同的 𝐒𝑖𝑘 , ℒcontrrep 增加了它们之间的编辑代码之间的距离。
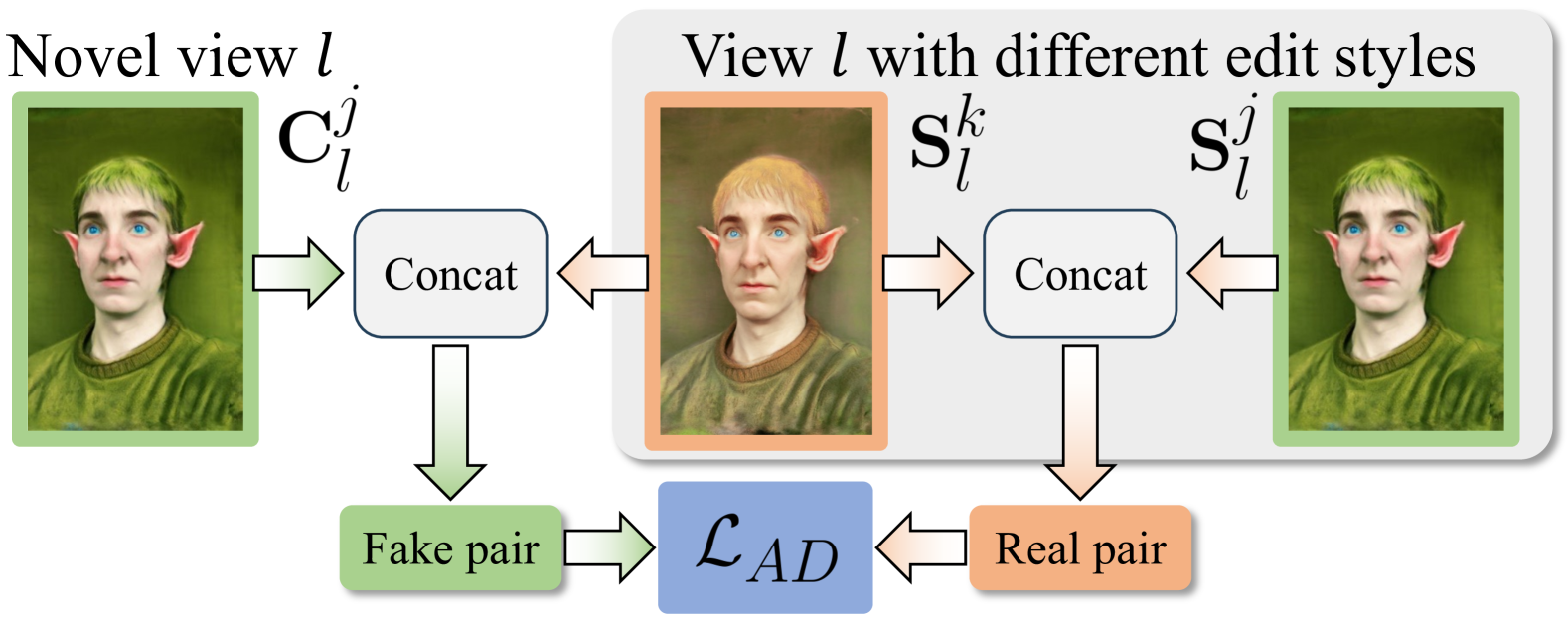
Figure 4:Illustration of our proposed conditional adversarial loss functions. Our conditional discriminator distinguishes artifacts such as blur and distortion in novel-view rendered image 𝐂𝑙𝑗 compared with target image 𝐒𝑙𝑗. 𝐒𝑙𝑗 and 𝐒𝑙𝑘 are edited with same view but various styles, the latter serves as the condition to concatenate with 𝐂𝑙𝑗 and 𝐒𝑙𝑗 and manufacture fake and real pairs.
图4:我们提出的条件对抗损失函数的说明。与目标图像 𝐒𝑙𝑗 相比,我们的条件反射区分了诸如新视图渲染图像 𝐂𝑙𝑗 中的模糊和失真之类的伪影。 𝐒𝑙𝑗 和 𝐒𝑙𝑘 以相同的视图但不同的样式编辑,后者用作与 𝐂𝑙𝑗 和 𝐒𝑙𝑗 拼接并制造假的和真实的对的条件。
3.1Latent Distill Module 3.1潜在蒸馏模块
Image Translation. As illustrated in Fig. 2, GenN2N is a unified framework for NeRF-to-NeRF translation, in which the core is to perform a 2D image-to-image translation and lift 2D edits into universal 3D NeRF-to-NeRF translation. Given the source multi-view image set {𝐈𝑖}𝑖=0𝑁−1 of a NeRF scene, we first perform image editing M times for each view using a plug-and-play 2D image-to-image translator, producing a group of translated image set {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1. In this paper, we use several 2D translation tasks to show the adaptability of our GenN2N: text-driven editing, super-resolution, colorization and inpainting. For more details about those 2D image editing methods, please refer to the supplementary materials.
图像翻译。如图2所示,GenN2N是NeRF到NeRF翻译的统一框架,其中核心是执行2D图像到图像翻译并将2D编辑提升到通用的3D NeRF到NeRF翻译。给定NeRF场景的源多视图图像集 {𝐈𝑖}𝑖=0𝑁−1 ,我们首先使用即插即用2D图像到图像转换器对每个视图执行图像编辑M次,产生一组转换的图像集 {{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1 。在本文中,我们使用几个2D翻译任务来展示我们的GenN2N的适应性:文本驱动编辑,超分辨率,彩色化和修复。有关这些2D图像编辑方法的更多详细信息,请参阅补充材料。
Edit Code. Since 2D image-to-image translation may generate different content even with the same editing target, causing the inconsistency problem in the 3D scene. We propose to map each edited image 𝐒𝑖𝑗 into a latent feature vector named edit code to characterize these diverse editings. We employ the off-the-shelf VAE encoder from stable diffusion [30] to extract the feature from 𝐒𝑖𝑗 and then apply a tiny MLP network to produce this edit code 𝐳𝑖𝑗∈ℝ64. During the training process, we keep the pre-trained encoder fixed and only optimize the parameters of the tiny MLP network. This mapping process can be formulated as follows:
编辑代码。由于2D图像到图像的转换可能会产生不同的内容,即使具有相同的编辑目标,导致在3D场景中的不一致性问题。我们建议将每个编辑后的图像 𝐒𝑖𝑗 映射到一个名为编辑代码的潜在特征向量中,以表征这些不同的编辑。我们使用来自稳定扩散[ 30]的现成VAE编码器来提取 𝐒𝑖𝑗 的特征,然后应用一个微小的MLP网络来生成这个编辑代码 𝐳𝑖𝑗∈ℝ64 。在训练过程中,我们保持预训练的编码器固定,只优化微小MLP网络的参数。这个映射过程可以用公式表示如下:
| 𝐳𝑖𝑗=𝒟(𝐒𝑖𝑗)=ℳ(ℰ(𝐒𝑖𝑗)), | (1) |
where 𝒟 represent this mapping process, ℰ is the fixed encoder, and ℳ is the learnable tiny MLP.
其中 𝒟 表示该映射过程, ℰ 是固定编码器,而 ℳ 是可学习的微小MLP。
KL loss. In order to facilitate effective sampling of the edit code so as to control the editing diversity of our NeRF-to-NeRF translation, we need to constrain the edit code to a well-defined distribution. Thus we design a KL loss to encourage 𝐳𝑖𝑗 to approximate a Gaussian distribution:
KL损失。为了便于对编辑代码进行有效采样,从而控制NeRF到NeRF翻译的编辑多样性,我们需要将编辑代码约束到定义良好的分布。因此,我们设计KL损失以鼓励 𝐳𝑖𝑗 近似高斯分布:
| ℒKL=𝔼𝐒∈{{𝐒𝑖𝑗}𝑗=0𝑀−1}𝑖=0𝑁−1[𝑃(𝐳𝑛𝑜𝑟𝑚𝑎𝑙)𝑙𝑜𝑔(𝑃(𝐳𝑛𝑜𝑟𝑚𝑎𝑙)𝑃(𝒟(𝐒)))], | (2) |
where 𝑃(𝐳𝑛𝑜𝑟𝑚𝑎𝑙) denotes probability distribution of the standard Gaussian distribution in ℝ64 and 𝑃(𝒟(𝐒)) means probability distribution of the extracted edit codes.
其中, 𝑃(𝐳𝑛𝑜𝑟𝑚𝑎𝑙) 表示 ℝ64 中的标准高斯分布的概率分布,并且 𝑃(𝒟(𝐒)) 表示所提取的编辑代码的概率分布。

Figure 5:Text-Driven Editing. We sample 4 inference results for both text-driven editing tasks. The diversity of geometry and appearance showcases awesome generative ability of GenN2N, on the premise of maintaining the 3D consistency between different viewpoints.
图5:文本驱动编辑。我们对这两个文本驱动的编辑任务的4个推理结果进行了采样。几何和外观的多样性展示了GenN2N强大的生成能力,前提是保持不同视点之间的3D一致性。

Figure 6:Colorization. Our method colorizes the gray-scale 3D scene consistently across views. By changing the edit code during inference, diverse colorized scenes can be rendered with satisfying photorealism and reasonably rich colors.
图6:着色。我们的方法着色的灰度3D场景一致的意见。通过在推理过程中更改编辑代码,可以以令人满意的照片真实感和合理丰富的颜色渲染各种彩色场景。
Contrastive loss. It is not assured that edit codes 𝐳 obtained from the Latent Distill Module contain only the editing information while excluding viewpoint-related effects. However, since the translated NeRF utilizes 𝐳 to edit scenes, it yields instability if 𝐳 violently changes given images that are similar in appearance but different in viewpoints. To ensure the latent code does not depend on 2D viewpoints but truly reflects the 3D edits, we regularize the latent code through a contrastive learning scheme. Specifically, we reduce the distance between edit codes of different-view rendered images from a translated NeRF that share the same edit code, while increasing the distance between same-view images that are multi-time edited by the 2D image-to-image translator. As illustrated in Fig. 3, given an edit code 𝐳𝑖𝑗 extracted from the 𝑖-th input view at the 𝑗-th edited image 𝐒𝑖𝑗, we render multi-view images {𝐂𝑙𝑗}𝑙=0𝑁−1 using the translated NeRF conditioned on 𝐳𝑖𝑗. Then we employ contrastive learning to encourage the edit code 𝐳𝑖𝑗 to be close to {𝐳𝑙𝑗}𝑙=0𝑁−1 extracted from {𝐂𝑙𝑗}𝑙=0𝑁−1, while being distinct from the edit codes {𝐳𝑖𝑘}𝑘=0𝑀−1 extracted from {𝐒𝑖𝑘}𝑘=0𝑀−1, where 𝑘≠𝑗.
对比损失。不能保证从Latent Distill Module获取的编辑代码 𝐳 仅包含编辑信息,而排除视点相关效果。然而,由于翻译后的NeRF使用 𝐳 来编辑场景,如果 𝐳 剧烈地改变外观相似但视点不同的给定图像,则会产生不稳定性。为了确保潜在代码不依赖于2D视点,而是真实地反映3D编辑,我们通过对比学习方案来正则化潜在代码。具体来说,我们减少了来自翻译的NeRF的不同视图渲染图像的编辑代码之间的距离,这些编辑代码共享相同的编辑代码,同时增加了由2D图像到图像翻译器多次编辑的相同视图图像之间的距离。如图3所示,给定在第5#个编辑图像 𝐒𝑖𝑗 处从第4#个输入视图提取的编辑代码 𝐳𝑖𝑗 ,我们使用以 𝐳𝑖𝑗 为条件的转换NeRF来渲染多视图图像 {𝐂𝑙𝑗}𝑙=0𝑁−1 。 然后,我们采用对比学习来鼓励编辑代码 𝐳𝑖𝑗 接近从 {𝐂𝑙𝑗}𝑙=0𝑁−1 提取的 {𝐳𝑙𝑗}𝑙=0𝑁−1 ,而与从 {𝐒𝑖𝑘}𝑘=0𝑀−1 提取的编辑代码 {𝐳𝑖𝑘}𝑘=0𝑀−1 不同,其中 𝑘≠𝑗 。
Specifically, our contrastive loss is designed as follows:
具体而言,我们的对比损失设计如下:
| ℒcontr | =ℒcontratt+ℒcontrrep | (3) | ||
| =∑𝑙=0𝑁−1‖𝐳𝑖𝑗−𝐳𝑙𝑗‖22+∑𝑘=0𝑀−1𝑚𝑎𝑥(0,𝛼−‖𝐳𝑖𝑗−𝐳𝑖𝑘‖22), |
where 𝛼 represents the margin that encourages the difference in features, and 𝑘≠𝑗.
其中 𝛼 表示鼓励特征差异的余量,而 𝑘≠𝑗 。
3.2NeRF-to-NeRF translation
3. 2NeRF到NeRF的翻译
Translated NeRF. After 2D image-to-image translation, we need to lift these 2D edits to the 3D NeRF. For this purpose, we propose to modify the original NeRF as a translated NeRF that takes the edit code 𝐳 as input and generates the translated 3D scene according to the edit code. We refer readers to the supplementary for more details about the network architecture.
翻译nef。在2D图像到图像的转换之后,我们需要将这些2D编辑提升到3D NeRF。为此,我们建议将原始NeRF修改为翻译后的NeRF,其将编辑代码 𝐳 作为输入并根据编辑代码生成翻译后的3D场景。有关网络架构的更多详细信息,请读者参阅补充资料。
Reconstruction loss. Given an edit code 𝐳𝑖𝑗 extracted from the edited image 𝐒𝑖𝑗, we can generate a translated NeRF to render 𝐂𝑖𝑗 from the same viewpoint. Then we define the reconstruction loss as the L1 normalization and Learned Perceptual Image Patch Similarity (LPIPS) [49] between the rendered image 𝐂𝑖𝑗 and the edited image 𝐒𝑖𝑗 as follows:
重建损失。给定从编辑的图像 𝐒𝑖𝑗 提取的编辑代码 𝐳𝑖𝑗 ,我们可以生成翻译的NeRF以从相同的视点渲染 𝐂𝑖𝑗 。然后,我们将重建损失定义为渲染图像 𝐂𝑖𝑗 和编辑图像 𝐒𝑖𝑗 之间的L1归一化和学习感知图像块相似性(LPIPS)[ 49],如下所示:
| ℒrecon | =ℒL1+ℒLPIPS | (4) | ||
| =‖𝐂𝑖𝑗−𝐒𝑖𝑗‖1+𝐿𝑃𝐼𝑃𝑆[𝒫(𝐂𝑖𝑗)−𝒫(𝐒𝑖𝑗)], |
where 𝒫 means a patch sampled from the image. Note that due to the lack of 3D consistency of the edited multi-view image, the supervision of the edited image from other viewpoints {𝐒𝑙𝑗}𝑙≠𝑖 will lead to conflicts in pixel-space optimization. Therefore, we only employ reconstruction loss on the same view image 𝐒𝑖𝑗 to optimize the translated NeRF.
其中 𝒫 表示从图像采样的补丁。注意,由于编辑的多视点图像缺乏3D一致性,从其他视点 {𝐒𝑙𝑗}𝑙≠𝑖 对编辑的图像的监督将导致像素空间优化中的冲突。因此,我们仅在相同视图图像 𝐒𝑖𝑗 上采用重建损失来优化经平移的NeRF。

Figure 7:Comparisons with baselines of text-driven NeRF editing. We compare our method with Instruct-NeRF2NeRF [10] in the editing by using the text prompt “Make it Spring”.
图7:与文本驱动NeRF编辑基线的比较。我们通过使用文本提示符“Make it Spring”在编辑中比较了我们的方法与Instruct-NeRF 2NeRF [ 10]。
| Method | CLIP Text-Image CLIP文本-图像 | CLIP Direction 剪辑方向 | FID ↓ FID编号0# |
| Direction Similarity↑ 方向相似度 ↑ | Consistency ↑ 一致性 ↑ | ||
| InstructPix2Pix [2]+NeRF | 0.1669 | 0.8475 | 270.542 |
| Instruct-NeRF2NeRF 指令NeRF 2NeRF | 0.2021 | 0.9828 | 148.021 |
| Ours w/o ℒadv | 0.1920 | 0.9657 | 162.275 |
| Ours w/o ℒcontr | 0.2007 | 0.9749 | 156.524 |
| Ours 我们 | 0.2089 | 0.9864 | 137.740 |
Table 1:Quantitative results on text-driven editing. We compare our method with the naive method of directly combining InstractPix2Pix [2] with NeRF and the state-of-the-art method Instruct-NeRF2NeRF [10].
表1:文本驱动编辑的定量结果。我们将我们的方法与直接将InstactPix 2 Pix [ 2]与NeRF结合的简单方法以及最先进的方法Instruct-NeRF 2NeRF [ 10]进行了比较。
Adversarial loss. Since the 3D consistency of edited multi-view images is not assured, relying solely on the reconstruction loss on the same view often leads to blurry or distorted artifacts on novel views. Previous research demonstrates the effectiveness of conditional adversarial training in preventing the production of blurry rendered images resulting from conflicts that arise from noise in the camera extrinsic when performing image supervision from different viewpoints [12]. The function of the condition is to guide discriminator with fine-grained information from the same viewpoint, thus preventing GAN mode collapse.
对抗性损失。由于编辑的多视图图像的3D一致性不能得到保证,因此仅依赖于同一视图上的重建损失通常会导致新视图上的模糊或失真伪影。以前的研究证明了条件对抗训练在防止产生模糊渲染图像方面的有效性,这些模糊渲染图像是由从不同视角执行图像监督时相机外部噪声引起的冲突造成的[ 12]。该条件的功能是从相同的视点用细粒度信息引导卷积,从而防止GAN模式崩溃。
It inspires us to incorporate conditional adversarial loss on rendered images from the translated NeRF, which is conducive to distinguish artifacts in rendered images. As illustrated in Fig.4, the discriminator 𝐃 takes into real pairs and fake pairs. Each real pair 𝐑 consists of 𝐒𝑗 and 𝐒𝑗−𝐒𝑘 where 𝐒𝑗∈{𝐒𝑖𝑗}𝑖=0𝑁−1 and 𝐒𝑘∈{𝐒𝑖𝑘}𝑖=0𝑁−1 are from two sets of edited images from the image translation. Similarly, each fake pair 𝐅 consists of 𝐂𝑗 and 𝐂𝑗−𝐒𝑘 in which 𝐂𝑗∈{𝐂𝑖𝑗}𝑖=0𝑁−1 is generated by translated NeRF. Note that the images in the same pair come from the same viewpoint. The pairs are concatenated in RGB channels and fed into the discriminator. We optimize the discriminator 𝐃 and translated NeRF with the objective functions below:
它启发我们在翻译的NeRF中的渲染图像上加入条件对抗损失,这有助于区分渲染图像中的伪影。如图4中所示,序列号 𝐃 分为真实的对和伪对。每个真实的对 𝐑 由 𝐒𝑗 和 𝐒𝑗−𝐒𝑘 组成,其中 𝐒𝑗∈{𝐒𝑖𝑗}𝑖=0𝑁−1 和 𝐒𝑘∈{𝐒𝑖𝑘}𝑖=0𝑁−1 来自图像转换的两组编辑图像。类似地,每个伪对 𝐅 由 𝐂𝑗 和 𝐂𝑗−𝐒𝑘 组成,其中 𝐂𝑗∈{𝐂𝑖𝑗}𝑖=0𝑁−1 由翻译的NeRF生成。请注意,同一对中的图像来自同一视点。这些对在RGB通道中连接并馈送到RGB中。我们用以下的目标函数优化了NeRF和翻译后的NeRF:
| ℒAD-D | =𝔼𝐑[−𝑙𝑜𝑔(𝐃(𝐑))]+𝔼𝐅[−𝑙𝑜𝑔(1−𝐃(𝐅))], | (5) | ||
| ℒAD-G | =𝔼𝐅[−𝑙𝑜𝑔(𝐃(𝐅))]. |
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











