







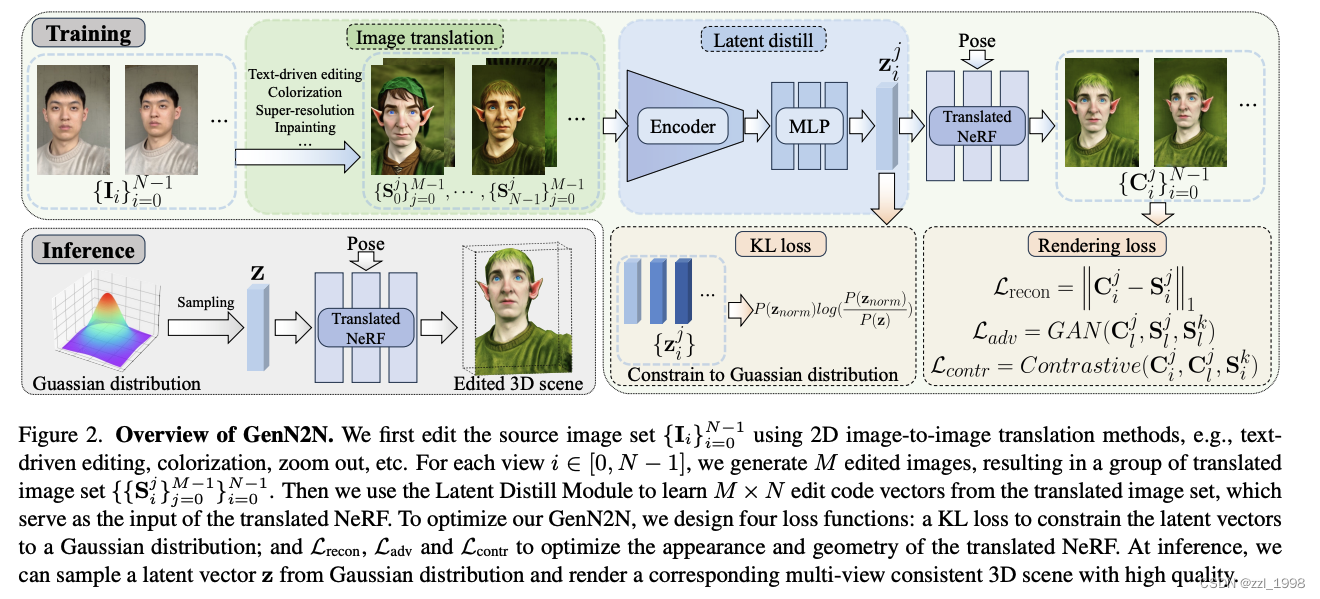
- 给定一个NeRF场景,本文提出GenN2N,可以借助2D图片编辑方法实现多视角一致的3D编辑,例如:文本引导编辑(text-driven editing)、着色(colorization)、超分(superresolution)和图像修复(inpainting)。
- 由于2D编辑存在多视角不一致性问题,本文提出通过生成模型建模每个2D编辑对应的潜在3D编辑,具体来说:
- 训练阶段:
- 给定场景的N张多视角图片,通过NeRFStudio训练一个NeRF;
- 对每个视角,通过2D图片编辑方法生成M个编辑图像;
- 通过隐码蒸馏模块(Latent Distill Module)将编辑图像映射为隐码,并设计了一个KL损失让隐码为高斯分布;
- 给定隐码,以类似EG3D的方式生成一个NeRF,并渲染出多视角图片,通过重建损失(reconstruction loss)、对抗损失(adversarial loss)和对比损失(contrastive loss)优化网络。
- 推理阶段:
- 从高斯分布中采样隐码,渲染对应的编辑后3D场景。
隐码蒸馏模块(Latent Distill Module)
- 隐码:使用Stable Diffusion的VAE encoder提取2D编辑图片的的特征,然后使用一个MLP将提取特征映射为64维的隐码。在训练过程中,VAE保持固定,仅训练MLP网络。
- KL损失:让隐码符合高斯分布。
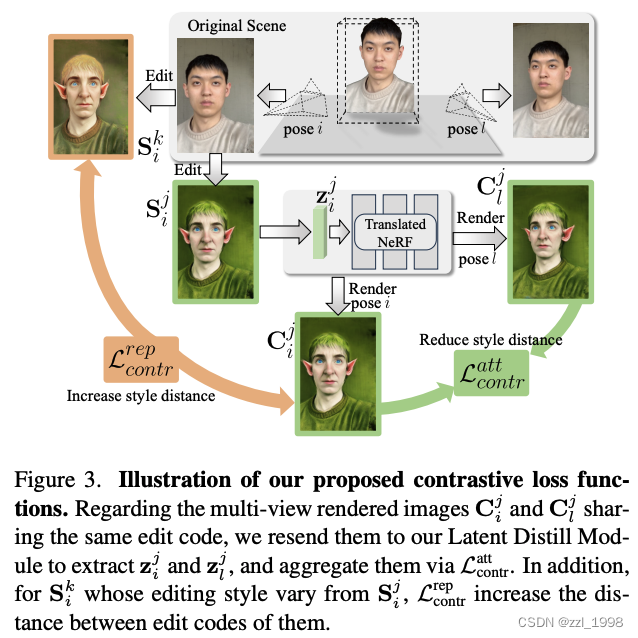
- 对比损失:让相同3D编辑模型不同视角下图像的隐码进可能接近,让相同视角下不同3D编辑模型的图像的隐码近可能拉远。同时引入一个阈值,鼓励差异:
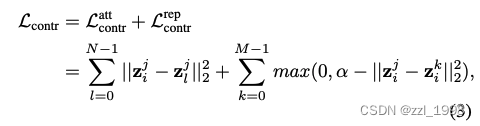
NeRF-to-NeRF变化
- 模型:在原始NeRF基础上,引入了额外可训练模块
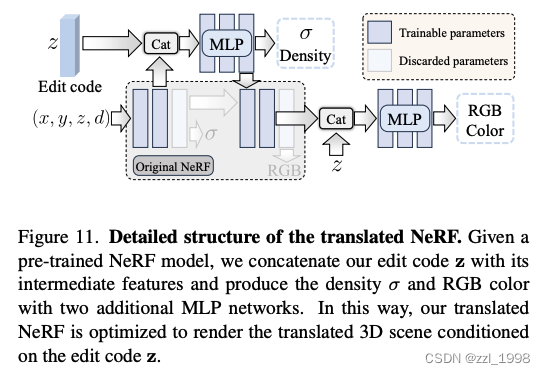
- 重建损失:使用L1和LPIPS损失约束
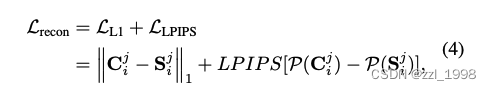
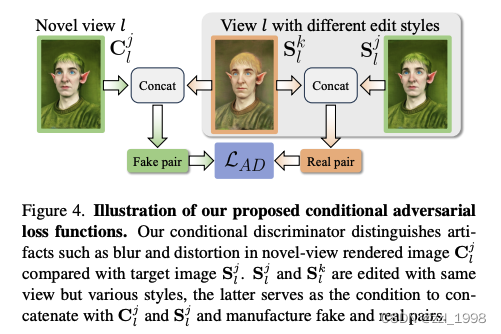
- 对抗损失:由于编辑图像存在多视角不一致,因此仅依赖重建损失效果不佳。本文引入对抗损失,提高渲染质量。具体来说:认为同一视角下的不同编辑图像为真;同一视角下的编辑图像和对应渲染图像为假。
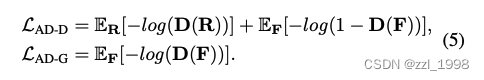
- 优化目标:
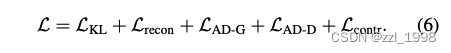
实验
在4个任务上进行了实验:
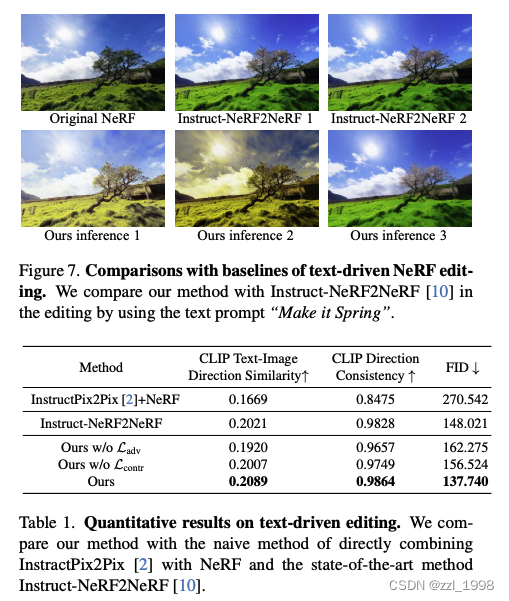
- 文本引导编辑:使用InstructPix2Pix;

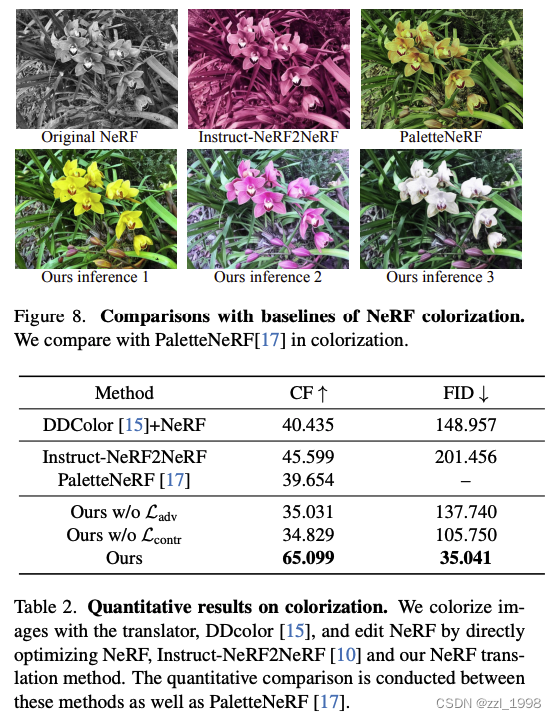
- 着色:使用DD-Color
- 超分:使用ResShift;

- Inpainting:使用SAM和LaMa
















 60
60











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









