






 本文详细介绍了如何在OriginLab中分析TGA和DTG曲线,包括数据表特征、曲线图解读、DTG计算与平滑、热力学事件解析、微分用途、反应归属判断以及TGA-XRD实验协同。通过实例演示,掌握材料热重分析的关键技术和应用。
本文详细介绍了如何在OriginLab中分析TGA和DTG曲线,包括数据表特征、曲线图解读、DTG计算与平滑、热力学事件解析、微分用途、反应归属判断以及TGA-XRD实验协同。通过实例演示,掌握材料热重分析的关键技术和应用。
昨天,我们分享了如何使用Origin Lab分析DSC曲线。在做热分析试验中,我们不仅仅得到一条DSC曲线,还有一条TG(TGA)曲线,通过对TG曲线一阶偏微分,还能得到DTG曲线。那么,今天,我们推送怎样分析材料的TGA和DTG?
读完本教程,可以掌握以下内容:
1.TGA的数据表特征
2.TGA的曲线图及失重率批注
3.TGA的微分DTG计算方法
4.微分热重DTG曲线的平滑降噪
5.TGA和DTG揭示了哪些热力学事件?
6. 我们从TGA中计算微分有什么用?
7. 怎样指认TGA和DTG中的反应归属?
8. 我们怎样开展TGA和XRD实验?
怎样利用OriginLab软件分析TGA(Thermogravimetric Analysis)曲线?相信与材料相关的研究生并不陌生,而且热重分析是材料学领域用得最多的一种热动力学分析手段。
今天我们以一种无机材料(例如金属氧化物)纳米颗粒为例,推出TGA分析的教程。
在上一期,我们推出一篇详细教程:
热重图谱分析之用Origin从DSC曲线计算焓和比热容
其中有两个热重分析图(TGA和DTG)没有做详细介绍,今天推送给各位读者。
1.TGA的数据表特征
我们测得的TGA数据表如下:
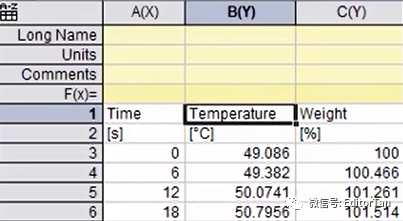
但是我们只绘制失重率与温度的曲线,因此,我们需要将时间数据列删除,并将温度数据列设置为X。我们只需要下表的数据结构:
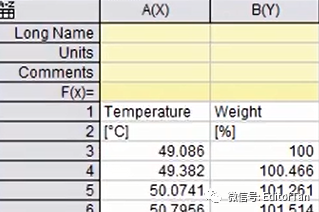
2.TGA的曲线图及失重率批注
选中上表中的两列数据,绘制曲线图。
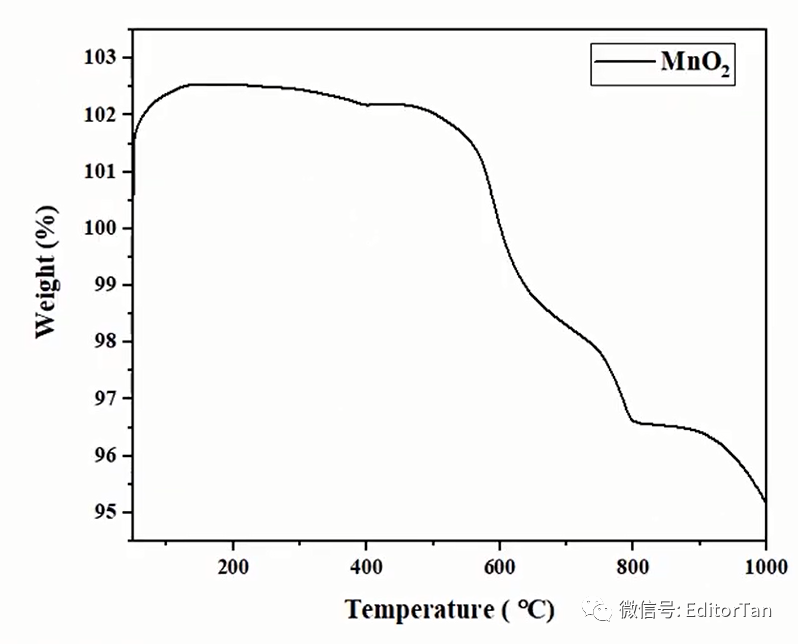
我们根据失重平台,绘制水平参考线:
利用屏幕读数功能,计算两个点失重率之差。
3.TGA的微分DTG计算方法
下面求TGA曲线的一阶微分:
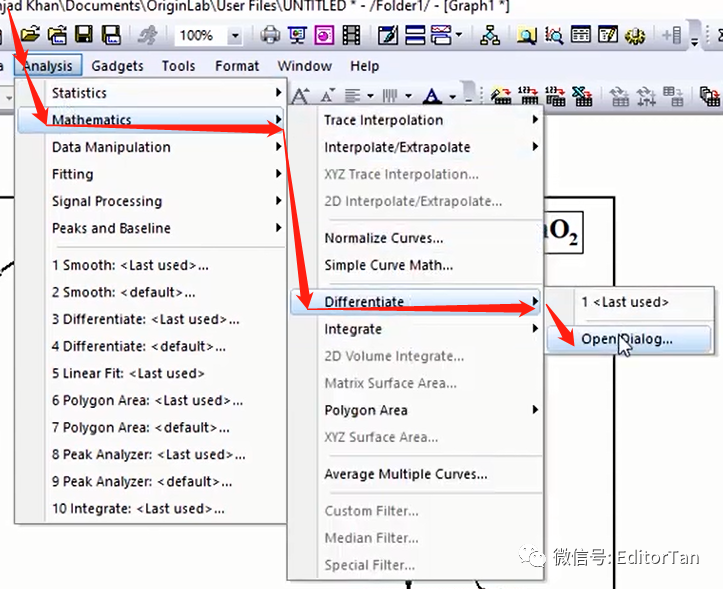
这样会在原数据表中新增一列微分结果数据。选择微分数据和X列绘图,用放大镜放大我们感兴趣的区域,发现微分曲线有毛刺,我们可以对其进行完美的平滑处理。
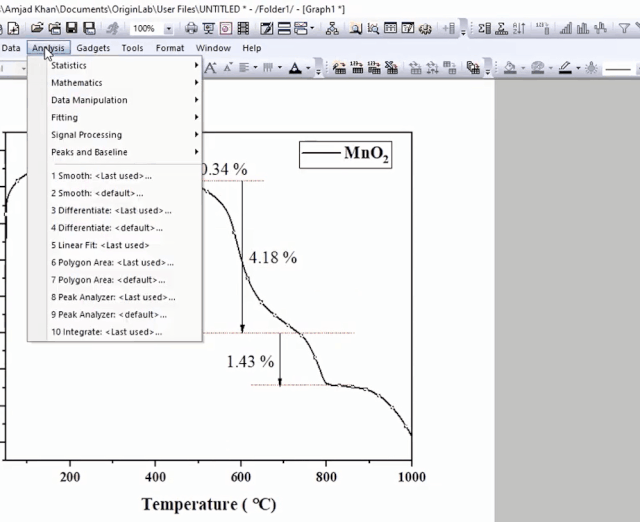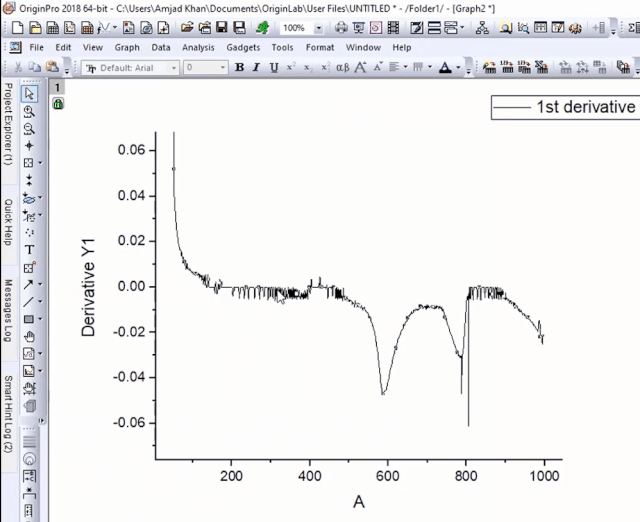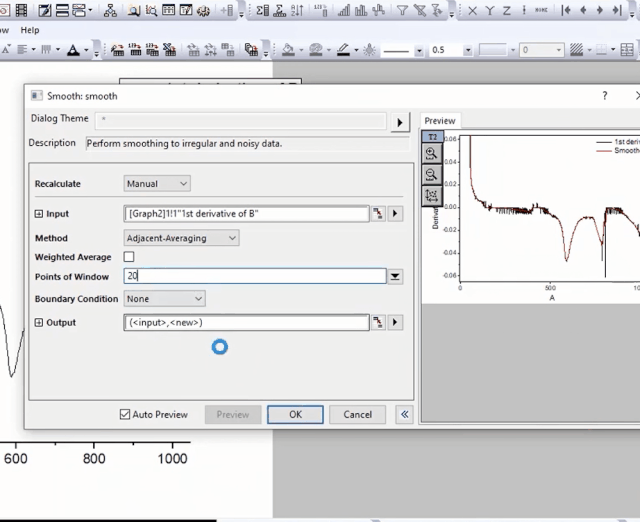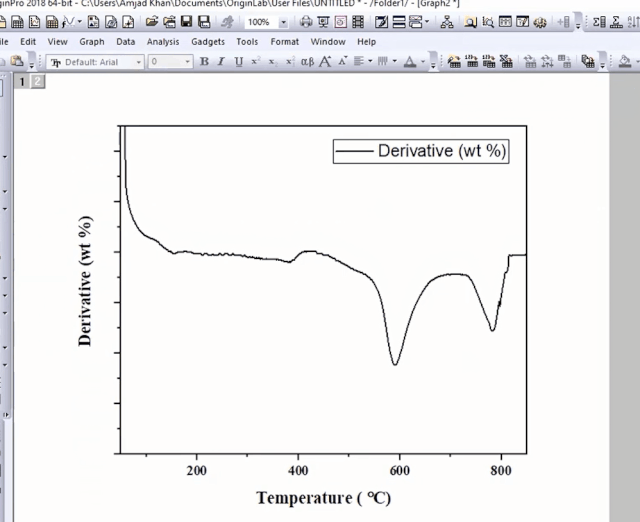
4.微分热重DTG曲线的平滑降噪
上面动图中几个重要操作分解如下:
(1)分析→信号处理→平滑→打开对话框
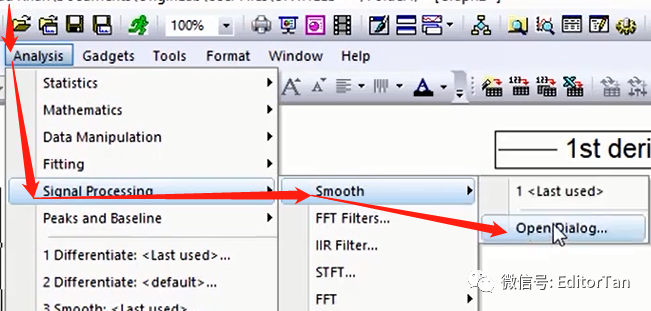
(2)平滑设置
在弹窗中打开自动预览,在Method方法中选择Adjacent-Averaging(相邻平均),调节平滑点数,直到预览的效果达到你满意为止,最后点OK。
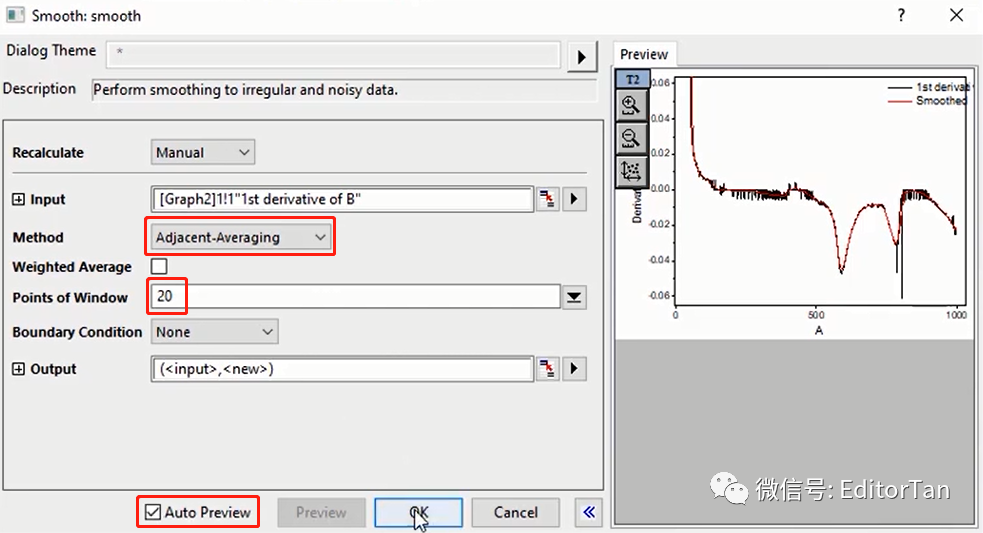
如果预览框中曲线需要局部放大,也可以点击预览口的放大镜工具,框选局部区域放大。
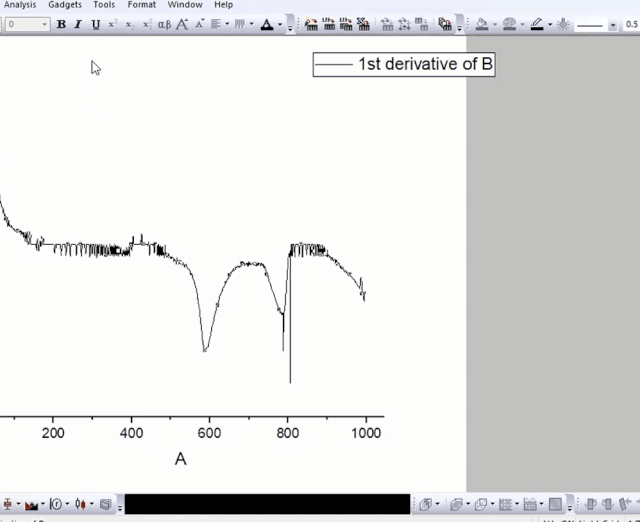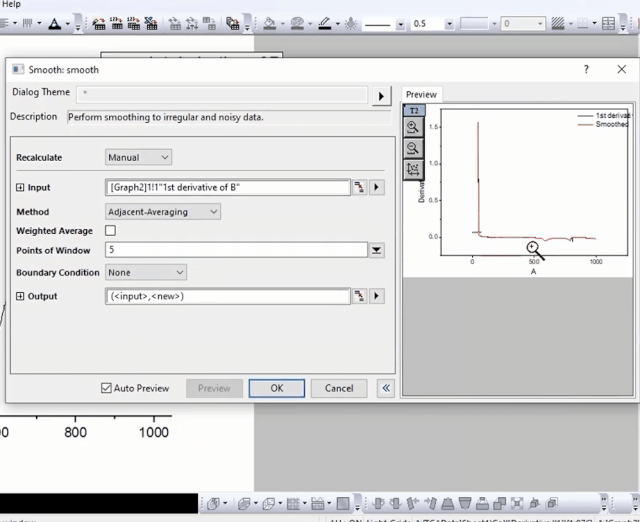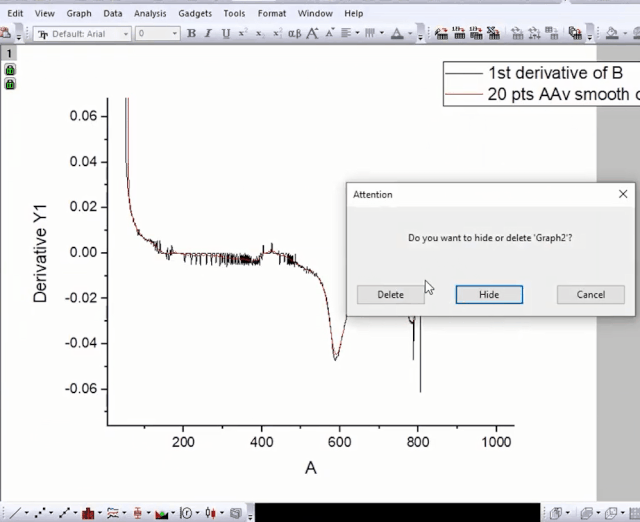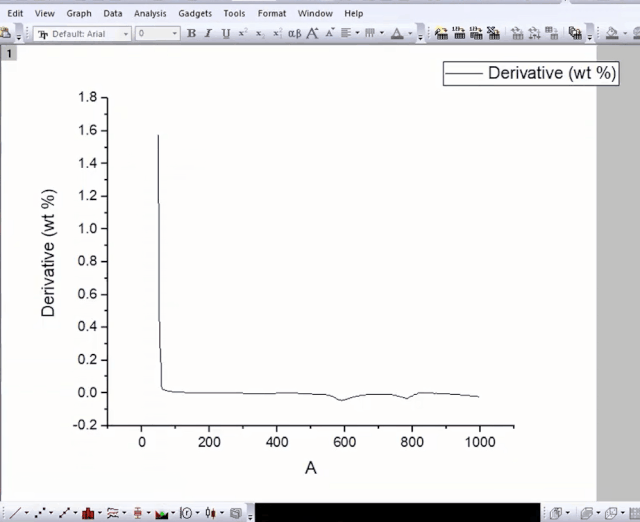
上面的动画中,请仔细多看几遍。你会注意到,在平滑后,我们删除了微分和平滑过程的临时绘图(点击绘图窗口右上角的✘删除此图),然后新增一列,将最后一列平滑数据复制到新列(为什么?因为平滑数据跟它前面的微分数据是关联的),最后删除微分数据和与之关联的平滑数据。
选择X列和刚才新增列(平滑的微分数据),绘制曲线,同样需要放大镜调节视图,最终我们得到TGA和DTG两个发表可用的图:
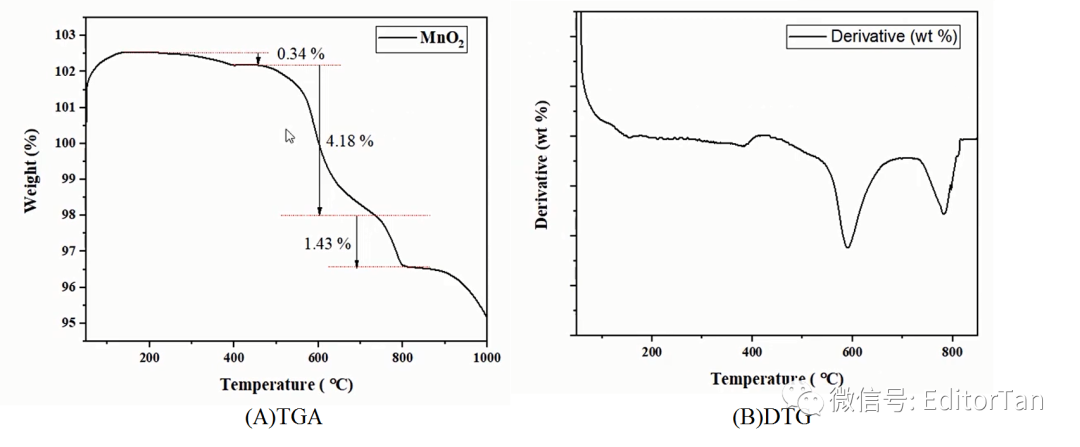
5.TGA和DTG揭示了哪些热力学事件?
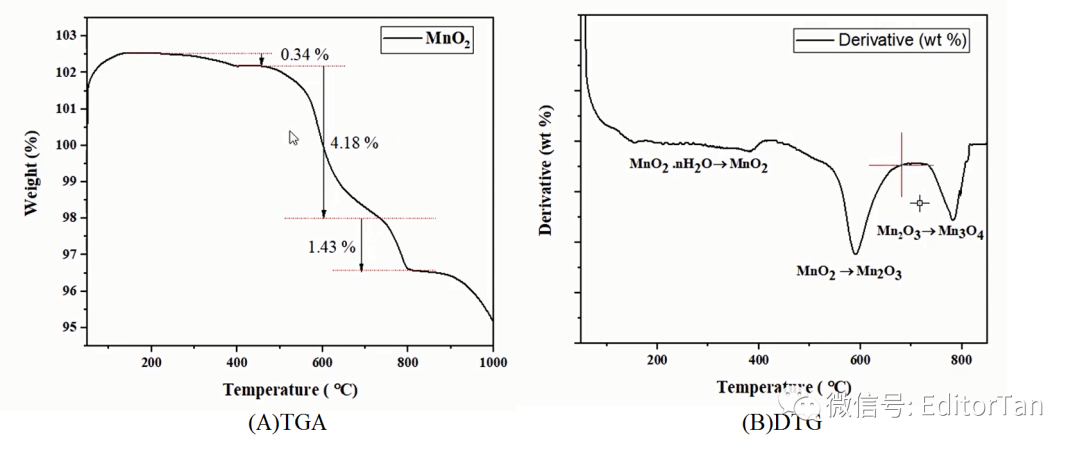
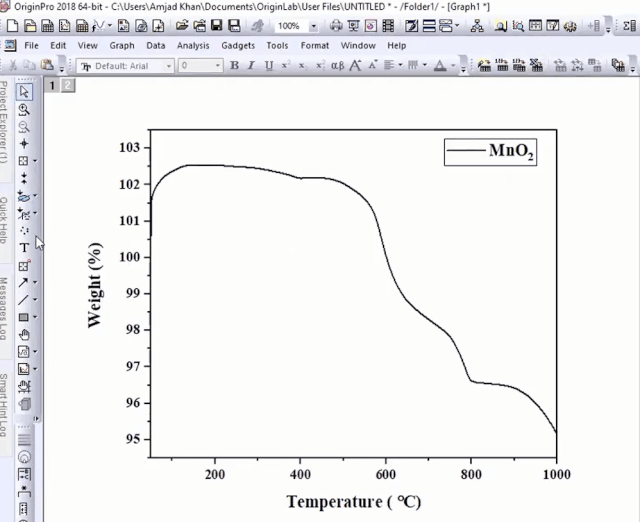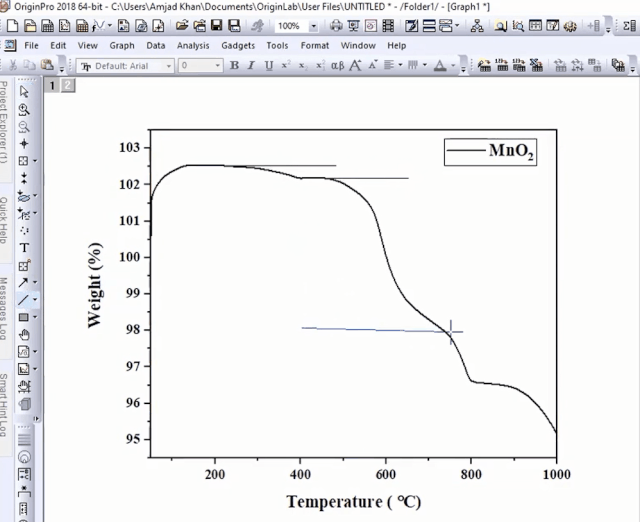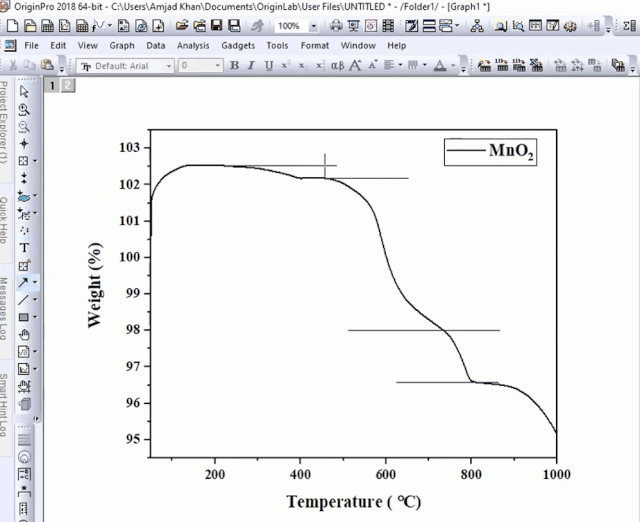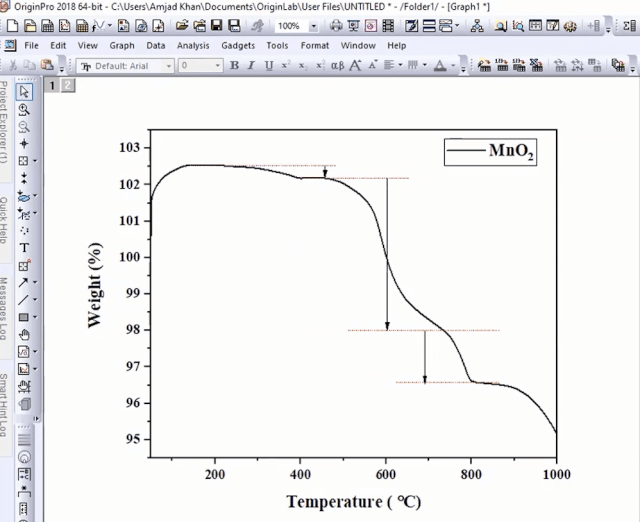
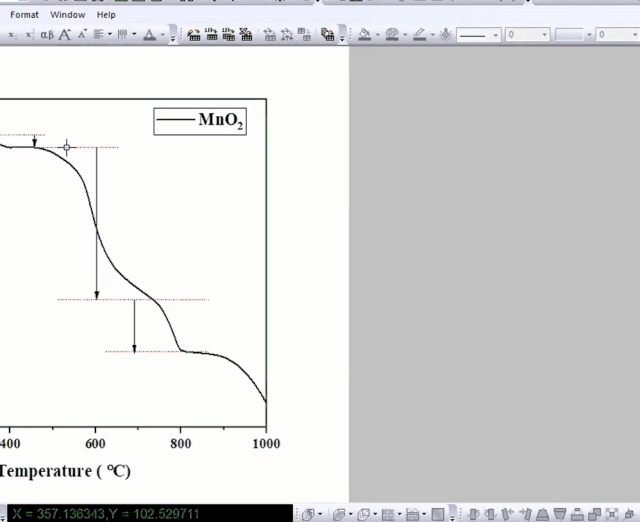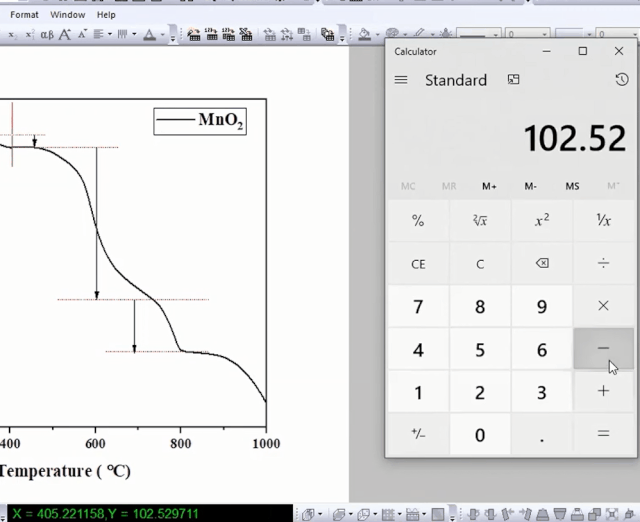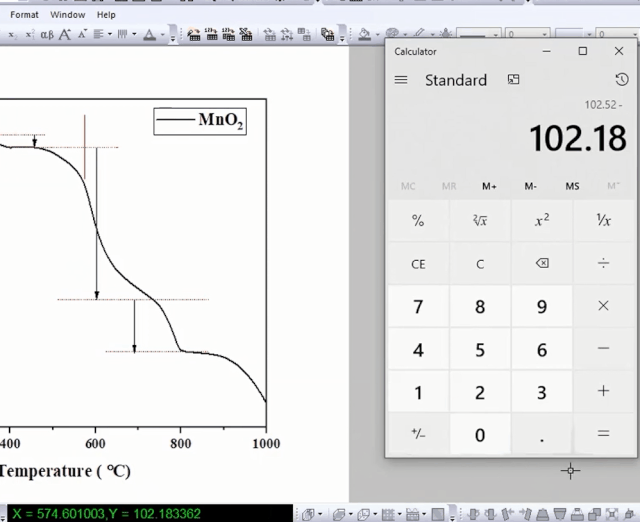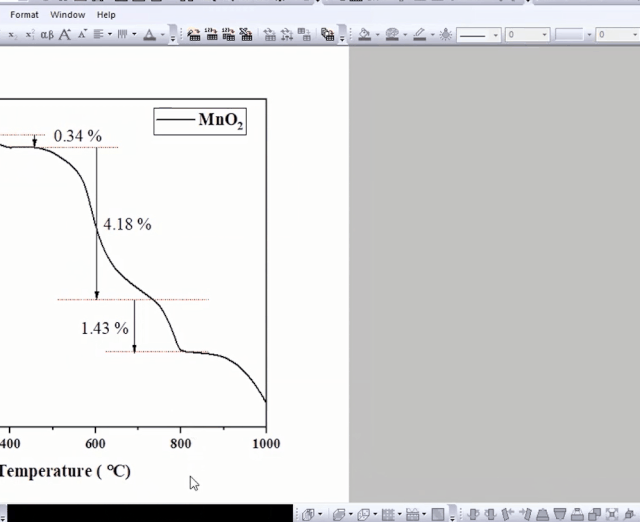
在TGA图中,开始阶段,质量损失率为0.35%来源于材料结晶水的分解和材料本身的脱水。
在DTG中,我们很容易得到这一过程的温度范围。
我们在图中对这一过程进行标注,如下图所示: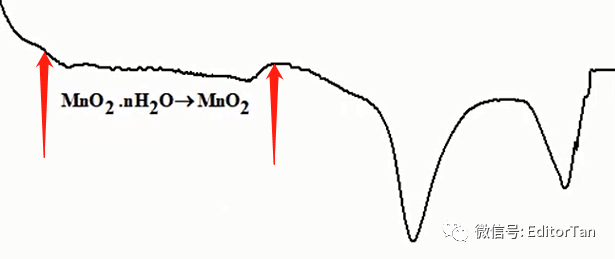 第二阶段的质量损失(4.18%)归属于
向
的物相转化。
我们对这一过程进行标记,结果如下:
第二阶段的质量损失(4.18%)归属于
向
的物相转化。
我们对这一过程进行标记,结果如下:
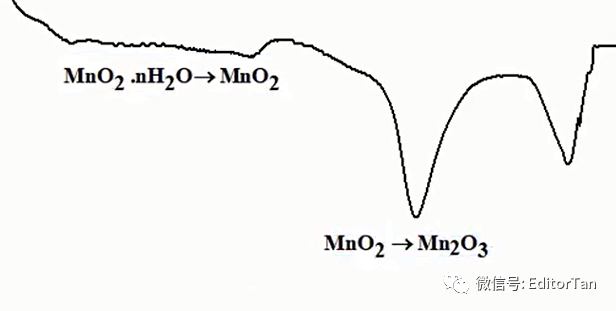 第三阶段的质量损失(1.43%)归属于
向
的物相转化。
最后得到下图的效果:
第三阶段的质量损失(1.43%)归属于
向
的物相转化。
最后得到下图的效果:
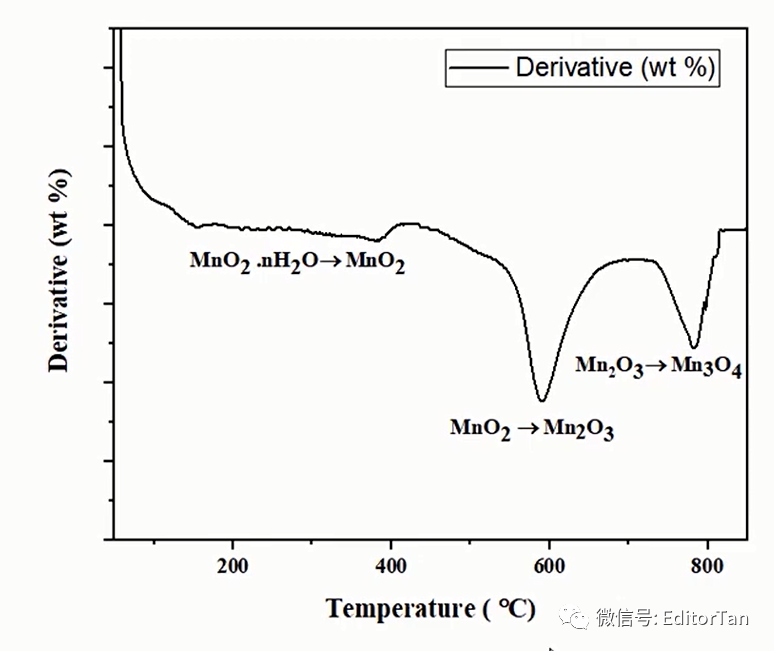 6. 我们从TGA中计算微分有什么用?
答案:在TGA曲线中,我们得不到那些热力学现象(相变峰、结晶峰)发生的准确温度。然而,在DTG曲线中,我们能清楚地找出每一处热力学现象的焓变峰的准确温度。
这在其他很多实验曲线中也是如此,例如我们研究电池的充放电曲线,我们看不到真正的充放电平台的电位,但是我们通过微分电容曲线就可以清楚地找到准确的氧化或还原反应发生的电位平台。例如编辑之谭前期推出的一系列教程:
Origin绘图:两步搞定曲线的微分
7. 怎样指认TGA和DTG中的反应归属
我怎么知道TGA失重率和DTG的吸热峰归属于水蒸发还是归属于物相转化?
答案:有两个可能的途径:
(1)可以通过相关文献;
(2)可以通过XRD分析。
8. 我们怎样开展TGA和XRD实验?
在XRD分析研究中,你需要在上述每个热力学事件对应温度下制备样品,并测试XRD。
例如本文样品需要做4个XRD测试,具体步骤如下:
(1)在测试TGA之前,测试原始样品的XRD(第一个XRD)。
(2)在全温度范围(50~1000 ℃)测试TGA。
(3)分析TGA,发现该材料的TGA中有3个明显的断崖式下降,可以初步判断存在3个热力学过程。
注意:材料吸附水分(游离态水分)的蒸发往往发生在100 ℃以内。
(4)第一个热力学过程对应于结晶水的分解反应,结束于400 ℃。我们选择一个新制备的样品,将其在420 ℃(大于结晶水分解温度,表示生成了第一种物相)煅烧,最后测试该煅烧的样品XRD(第二个XRD,很显然归属于MnO2)。
6. 我们从TGA中计算微分有什么用?
答案:在TGA曲线中,我们得不到那些热力学现象(相变峰、结晶峰)发生的准确温度。然而,在DTG曲线中,我们能清楚地找出每一处热力学现象的焓变峰的准确温度。
这在其他很多实验曲线中也是如此,例如我们研究电池的充放电曲线,我们看不到真正的充放电平台的电位,但是我们通过微分电容曲线就可以清楚地找到准确的氧化或还原反应发生的电位平台。例如编辑之谭前期推出的一系列教程:
Origin绘图:两步搞定曲线的微分
7. 怎样指认TGA和DTG中的反应归属
我怎么知道TGA失重率和DTG的吸热峰归属于水蒸发还是归属于物相转化?
答案:有两个可能的途径:
(1)可以通过相关文献;
(2)可以通过XRD分析。
8. 我们怎样开展TGA和XRD实验?
在XRD分析研究中,你需要在上述每个热力学事件对应温度下制备样品,并测试XRD。
例如本文样品需要做4个XRD测试,具体步骤如下:
(1)在测试TGA之前,测试原始样品的XRD(第一个XRD)。
(2)在全温度范围(50~1000 ℃)测试TGA。
(3)分析TGA,发现该材料的TGA中有3个明显的断崖式下降,可以初步判断存在3个热力学过程。
注意:材料吸附水分(游离态水分)的蒸发往往发生在100 ℃以内。
(4)第一个热力学过程对应于结晶水的分解反应,结束于400 ℃。我们选择一个新制备的样品,将其在420 ℃(大于结晶水分解温度,表示生成了第一种物相)煅烧,最后测试该煅烧的样品XRD(第二个XRD,很显然归属于MnO2)。
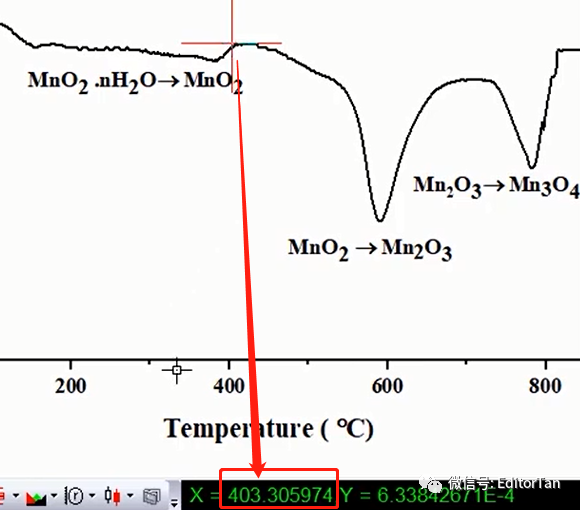 (5)同理,对于第二个热力学过程结束于680 ℃,我们再利用新制样品在700 ℃下煅烧用于测试XRD(第三个XRD)。
(5)同理,对于第二个热力学过程结束于680 ℃,我们再利用新制样品在700 ℃下煅烧用于测试XRD(第三个XRD)。
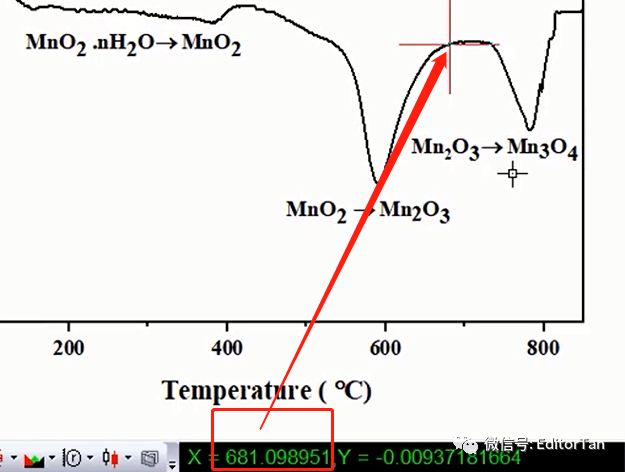 (6)同理,第三个热力学过程结束于810 ℃,我们测试830 ℃煅烧样品的XRD(第四个XRD)。
(6)同理,第三个热力学过程结束于810 ℃,我们测试830 ℃煅烧样品的XRD(第四个XRD)。
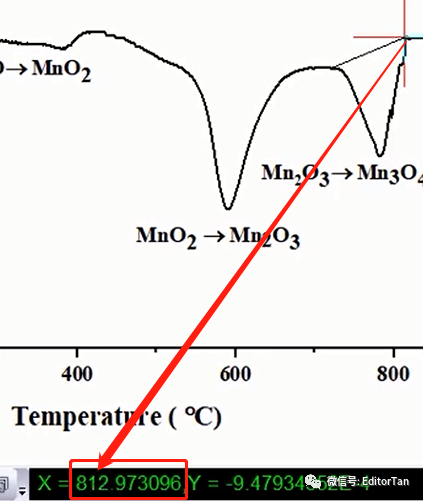 简言之,具体实验安排如下:
(1)新制样品→XRD
(2)新制样品+420 ℃煅烧→XRD
(3)新制样品+700 ℃煅烧→XRD
(4)新制样品+830 ℃煅烧→XRD
通过这种方式,我们就能指认TGA和DTG曲线中各个突变、各个吸热峰对应的物相,进而可以推断在各个热事件中发上了哪些反应了。
简言之,具体实验安排如下:
(1)新制样品→XRD
(2)新制样品+420 ℃煅烧→XRD
(3)新制样品+700 ℃煅烧→XRD
(4)新制样品+830 ℃煅烧→XRD
通过这种方式,我们就能指认TGA和DTG曲线中各个突变、各个吸热峰对应的物相,进而可以推断在各个热事件中发上了哪些反应了。


声明:壹砼壹世界使用的图片、音频、视频,来源于互联网。如有侵权,请后台联系删除。壹砼壹世界感谢你的关注。壹砼壹世界,带你在建材的天空中翱翔。


















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









