






论文 3D-STMN: Dependency-Driven Superpoint-Text Matching Network for End-to-End 3D Referring Expression Segmentation,通过超点-文本匹配和依存驱动,实现端到端的高效 3D 指向性分割。
论文题目:
3D-STMN: Dependency-Driven Superpoint-Text Matching Network for End-to-End 3D Referring Expression Segmentation
论文地址:
https://arxiv.org/abs/2308.16632
代码地址:
https://github.com/sosppxo/3D-STMN
动机
3D Visual Grouding 的目标是根据给定的自然语言描述在 3D 场景中定位实例 [1, 2, 3]。近年来,由于其广泛的应用场景,包括自主机器人、人机交互和自动驾驶系统等,已成为学术研究中的热门话题。该领域中,3D 引用表达式分割(3D-RES)任务是一个艰巨的挑战。与仅使用边界框定位目标对象的三维视觉检测任务相比,3D-RES 需要更复杂的理解。它不仅需要在稀疏点云中识别目标实例,而且还需要提供与每个识别的目标实例相对应的精确 3D 掩码。
现有的二阶段方法 [4] 如图 1-(a)所示,在初始阶段,训练一个独立的文本无关的分割模型来生成实例建议,在第二阶段,使用图神经网络构建生成的提议和文本描述之间的联系。这种两阶段范式存在三个主要问题:
- 分割与匹配解耦会产生过度依赖初步的与文本无关的分割结果。第一阶段的任何不准确或遗漏都可能损害后续匹配阶段的准确性。
- 该模型忽略了参考句子中固有的层次和依存结构。它的线性语言建模策略在捕获复杂的语义细微差别方面表现不佳,导致定位和分割中的错误步骤。
- 为了放大第二阶段的召回率效率,第一阶段通过低效的迭代聚类提取密集的候选掩码。这个迭代过程大大减慢了模型的推理速度。
一种自然的方法是采用端到端方法,将文本特征与三维点云中的点直接匹配,如图 1-(b)所示。这种方法已被证明在 2D-RES 任务中非常有效 [5]。然而,它的低召回率导致较难直接迁移到稀疏、不规则的 3D 点云数据。
作为一种解决方案,3D VG(REC)中的 3D-SPS 提出了一种方法,该方法逐步选择语言引导的关键点,并使用该关键点信息回归框。然而,这种方法破坏了 3D 掩码在 3D-RES 任务中的连续性,从而降低了分割质量。
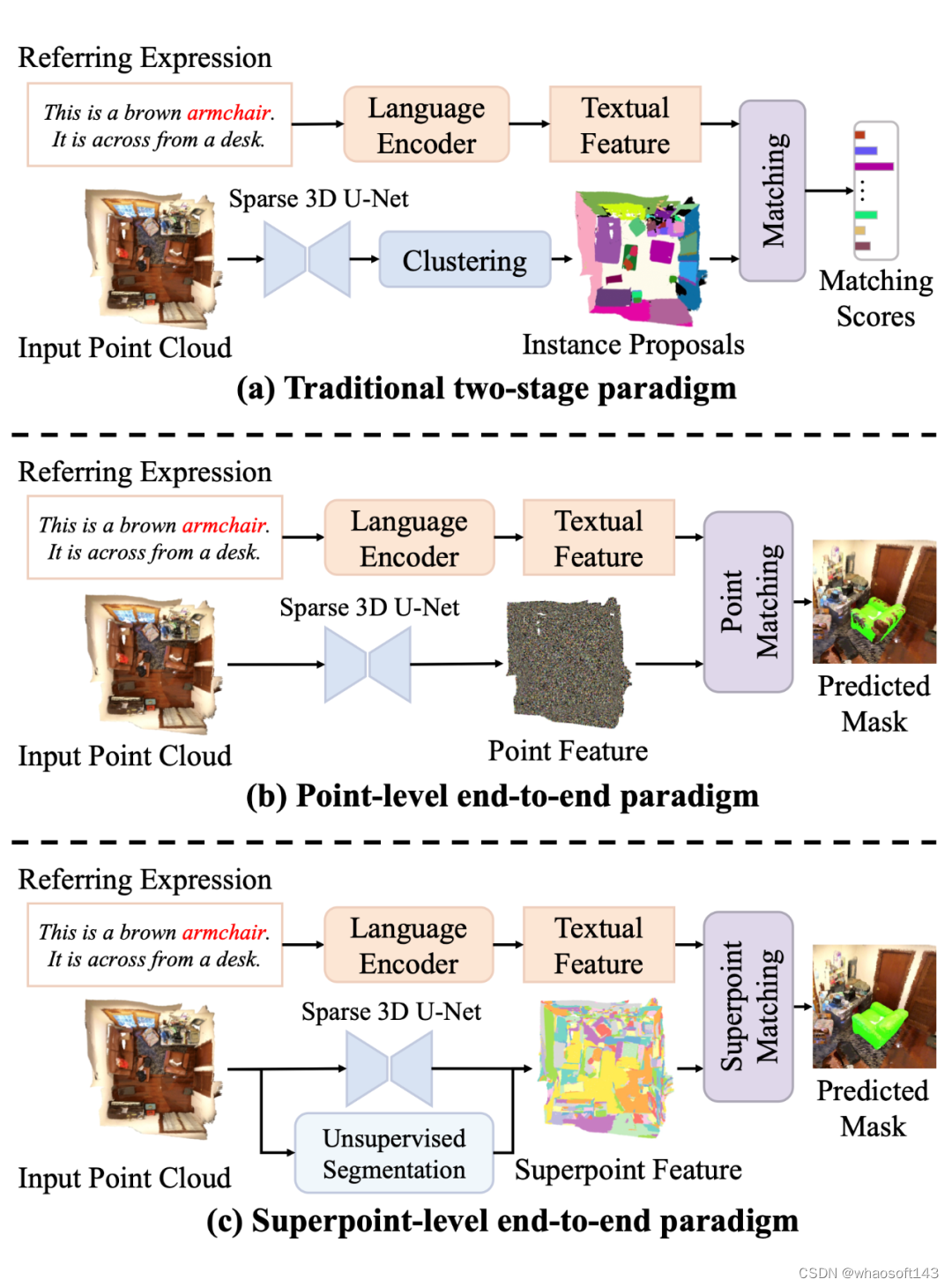
▲ 图1(a)传统两阶段范式,(b)点级端到端范式,(c)超点级端到端范式。
为了解决上述挑战,该工作提出了一种用于端到端 3D-RES 的依存驱动超点文本匹配网络(3D-STMN)。该工作的方法的想法是将指向性表达式与过分割的超点 [6] 进行匹配。如图 1-(c)所示,这些超点最初通过聚类算法聚合,从而获得细粒度的语义单元。与三维点云中的无序点相比,这些超点体现了语义,并且明显更少,在匹配过程中提供了性能和速度的优势。
与 TGNN 中的提议相比,超点是从过度分割派生的细粒度单元,能够覆盖整个场景,从而避免了分割不准确或缺失实例的问题。鉴于此,该工作引入了一种新的 3D-RES 超点文本匹配(STM)机制,利用超点文本特征的聚合来获取目标实例的掩码。
为了从文本角度支持语义解析,该工作设计了一个依存驱动交互(DDI)模块,实现了令牌级交互。该模块利用来自依存语法树的先验信息来引导文本信息的流动。这种结构通过网络架构进一步增强了对不同实例之间关系的推理,从而显着提高了模型的分割能力。
3D-STMN 对 3D-RES 领域做出了如下贡献:
- 论文提出了一种新的基于超点-文本匹配(STM)机制的高效端到端框架 3D-STMN,用于将超点与文本模态对齐,使超点成为多模态表示中极具竞争力的选项。
- 该工作设计了一个依存驱动交互(DDI)模块来利用来自依存语法树的先验信息来引导文本信息的流动,显着提高了模型的分割能力。
- 大量实验表明,该工作的方法在 ScanRefer 基准测试中显着优于之前的两阶段基线, mIoU 提高了 11.7 个百分点,同时也实现了推理速度的惊人增强。
方法
3D-STMN 包含超点-文本匹配(STM)机制和依存驱动交互(DDI)模块。STM 利用密集注释的超点-文本对,而不是更稀疏的实例-文本对,直接将语言指示与它们对应的超点进行关联,从而有效地利用跨模态语义关系。DDI 模块利用依存语法树引导文本信息流,辨别表达式中的重要单词及其相关描述符之间错综复杂的关系,以提高模型的分割能力。图 2 展示了 3D-STMN 的详细构成。
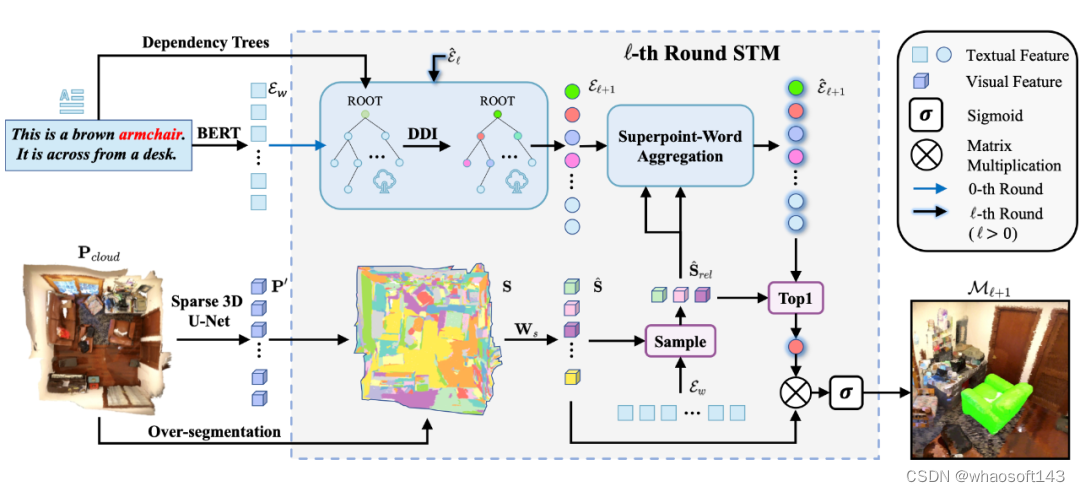
3.1 超点-文本匹配(STM)





3.2 依存驱动的交互(DDI)




3.3 训练损失


实验
该工作是在 3D 参考数据集 ScanRefer 上进行训练并测试的,该数据集包含 51,583 个自然语言表达式,涉及 800 个 ScanNet 场景中的 11046 个对象。所有实验都是用 PyTorch 实现的,并在单个 NVIDIA Tesla A100 GPU 上进行训练。
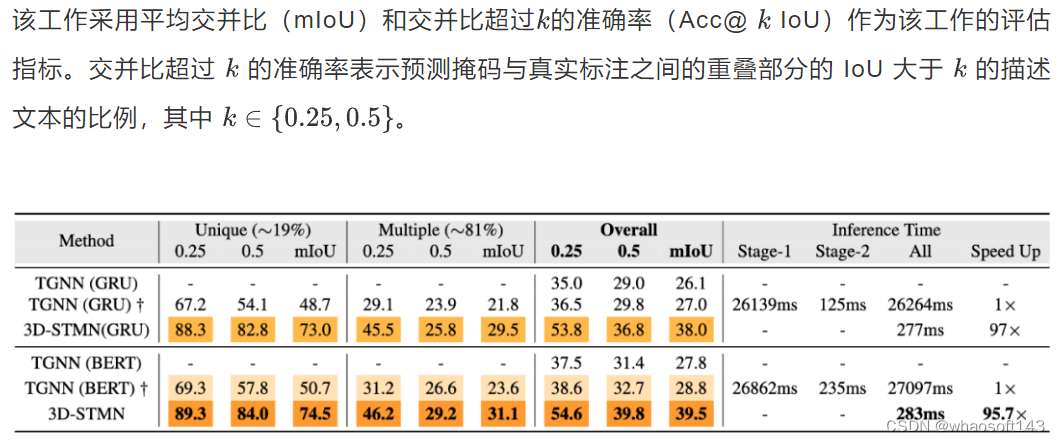
▲ 表1 ScanRefer数据集上的3D-RES结果
此前唯一研究 3D-RES 任务的工作是 TGNN。如表 1 所示,该工作提出的 3D-STMN 在 Acc@0.25、Acc@0.5 和 mIoU 方面取得了显著的改进,整体性能提升分别达到了 17.1%、8.4% 和 11.7%。
在推断速度方面,该工作计算了每个描述的平均推断时间。该工作的 3D-STMN 表现出明显优势,比两阶段的 TGNN 快了 95.7 倍。由于该工作模型的推断时间控制在 0.3 秒以内,使得 3D-RES 的实时应用成为可能。无论是使用 BERT 还是 GRU 特征,该工作的 3D-STMN 都明显优于 TGNN,突出了该工作模型的鲁棒性和推断能力。在 “Unique” 设置中,该工作的模型将 Acc@0.25 提升了 30 个点,突显了其对于唯一对象的精确性。
4.1 消融
该工作首先对于 STM 机制进行了消融实验。首先针对是否使用超点级特征,从表 2 中可以看出,在相同的设置下,第二行在所有指标上都显着优于第一行,证明了使用超点作为表示的有效性。
接下来,在第 3-6 行,该工作添加了 DDI 模块。无论 DDI 模块的结构如何,它都会极大地增强分割核的性能,导致所有指标的显着改进,证明了依存驱动特征的细粒度分辨能力。在 STM 框架中,分割内核策略的选择在依存驱动特征如何构建内核进行分割方面起着关键作用。
该工作测试了三种不同的策略:i)Root:它使用根节点的嵌入来制定分割内核;ii)Top1:利用得分最高的词嵌入,这是通过沿超点维度平均词嵌入得出的;iii)Average:利用通过平均所有单词的嵌入计算的嵌入。该工作的发现,如表 2 所示,Top1 策略因其灵活的视觉自适应性而成为最有效的。因此,后续实验选择了此设置。
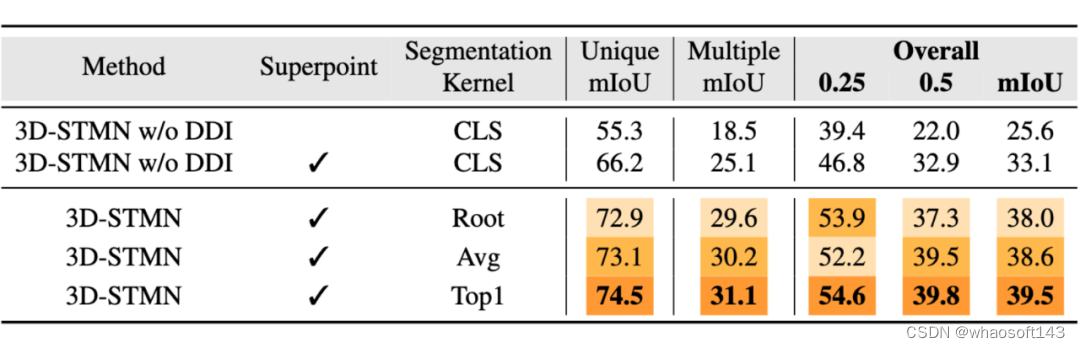
▲ 表2 STM 机制的消融,其中 “w/o DDI” 表示直接使用 [CLS] Token 去生成分割核,而非采用 DDI 模块。
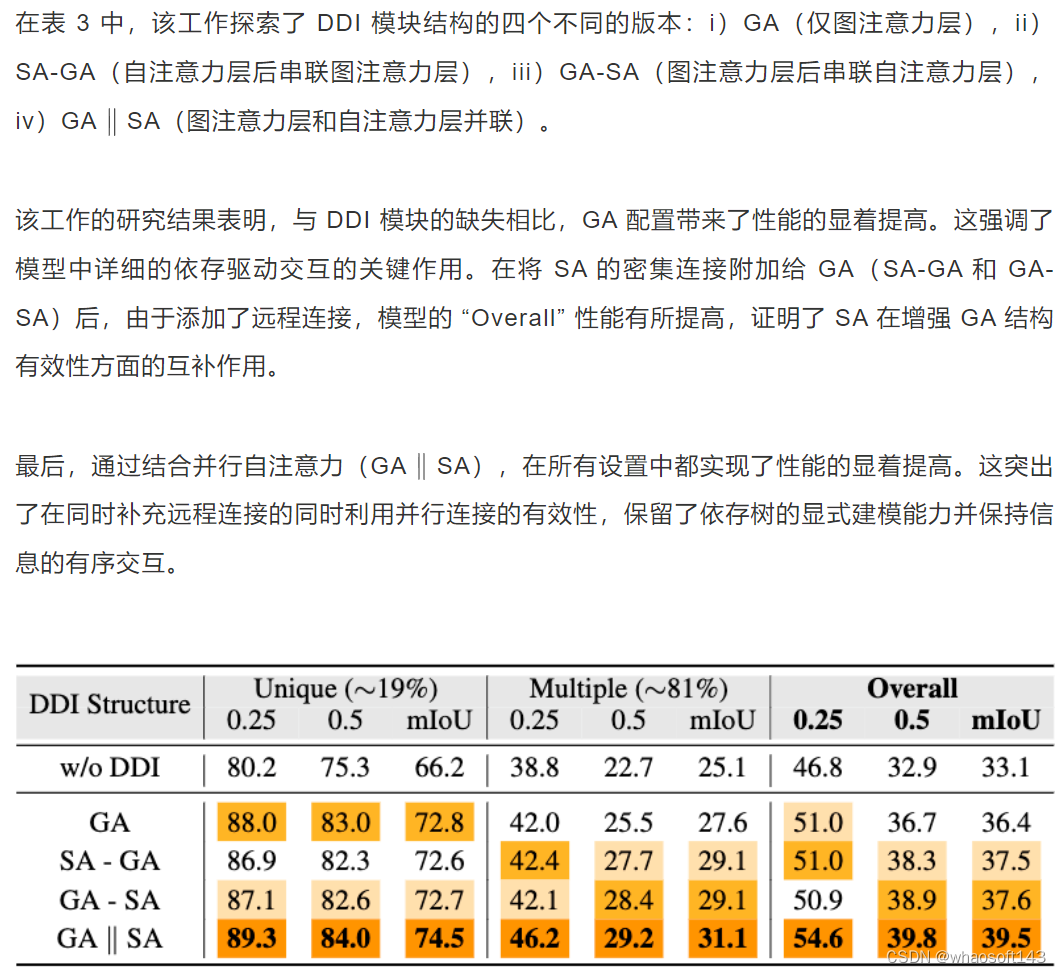
▲ 表3 DDI 模块的消融
4.2 定性分析
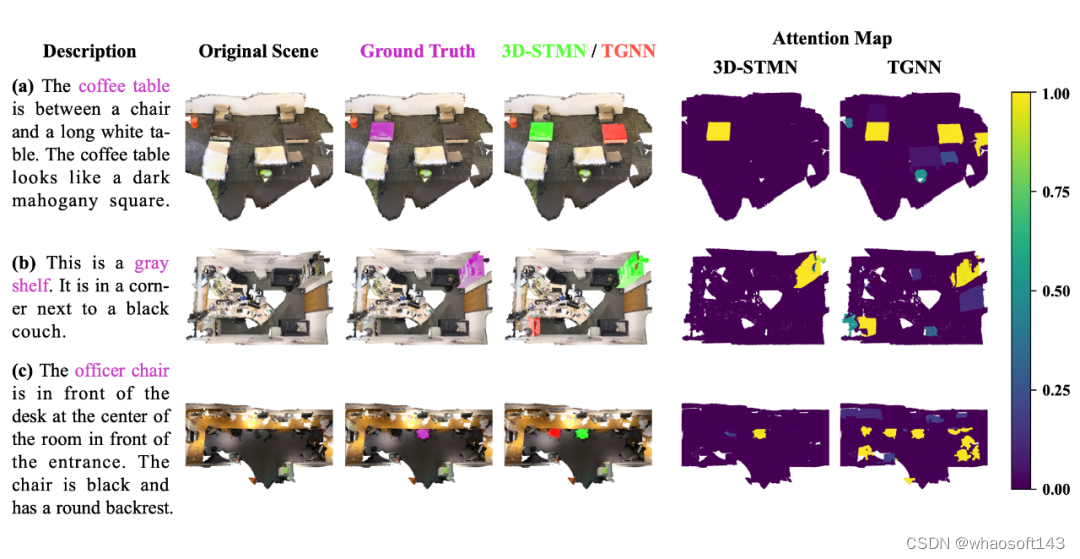
该工作对 ScanRefer 验证集进行了定性比较,展示了 3D-STMN 相对于 TGNN 在辨别能力上的显著优势。图 3 直观地展示了无论测试样本的难度级别如何,3D-STMN 在准确定位目标对象的注意力图上都有着优越的性能。3D-STMN 生成的注意力高度聚焦,展现了卓越的精确性。
相反,TGNN 在辨别方面存在困难,在多个语义相似对象上显示出显著高的注意力值,如图 3 的(a)、(b)和(c)所示。值得注意的是,当面临包含多个与目标相似的对象,并伴随着更长、更复杂的文本描述(如图 3 的(a)和(c)所示)的场景时,TGNN 无法区分和准确定位目标,其性能可与随机猜测相似。
相反,3D-STMN 能够对这些具有挑战性的样本进行精确的分割。类似于人类,它对靠近目标的对象有微妙但明显的关注,并将它们与背景区分开来,如图 2 的(c)中所示。
总结
这项研究提出了 3D-STMN,这是一种高效且密集对齐的 3D-RES 端到端方法。
通过使用超点文本匹配(STM)机制,该模型成功地摆脱了传统两阶段范式的局限性。使得模型可以利用端到端密集监督,具备精确分割和快速推理速度的优点。特别地,该模型每个场景实现了不到 1 秒令人印象深刻的推理速度,这使得它非常适合实时应用,并且高度适用于时间敏感的场景。此外,所提出的依存驱动交互(DDI)模块显着提高了模型对引用表达式的理解。通过显式建模依赖关系,该模型展示了改进的定位和分割能力,性能显着提高。
得益于精细、高效的设计,该模型甚至可以在 1080Ti 上进行训练!















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









