







Hello 大家好呀,我是小张~
本期将给大家介绍一个 Github 项目,用于OCR文本识别的;在之前的教程中,关于用 Python 实现OCR 识别,写过两篇文章:
一篇是关于 python 与 Tesseract ,详情可参考:介绍一个Python 包 ,几行代码可实现 OCR 文本识别; tesseract 是基于传统机器学习方法实现的, 对于英文字符识别还是挺棒的,但中文字符的识别效果就差强人意了~~
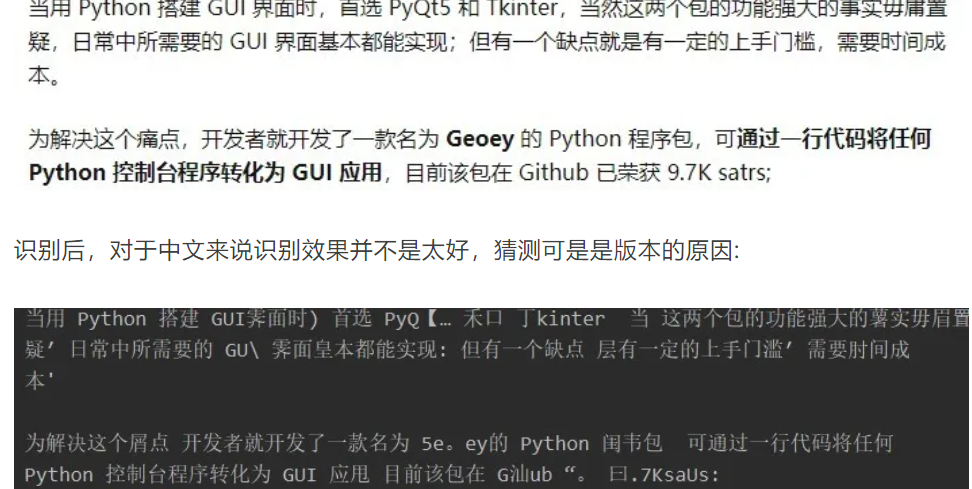
还有一篇是介绍了一个用于文本识别的 Github 项目Easy-OCR,相关用法详情可参考:关于文本OCR检测、分享一个基于深度学习技术的Python库
Easy-OCR 是基于深度学习技术开发的,识别效果要优于 Tesserart,支持识别70+个国家语言,除了文本识别之外还能对文本块区域完成检测功能,并用线框将相关区域标注在原图上

但测试后发现,该库对于某些路标识别效果并不是很精确~
2 PaddleOCR 介绍
这篇文章呢,将介绍一个新的 Github 项目,同样用于 OCR 识别、该项目名叫 PaddleOCR,是 Paddle 的一个分支;PaddleOCR 基于深度学习技术实现的, 所以使用时需要训练好的权重文件,但这个不需要我们担心,因为官方提供的有~
本小节是对 PaddleOCR 项目的简单介绍,如果只对使用步骤感兴趣的同学可以跳过本小节看第三节部分~~~
经测试 PaddleOCR 识别效果非常优秀,下面两张图片是从官网介绍中截取的几张图片
图一
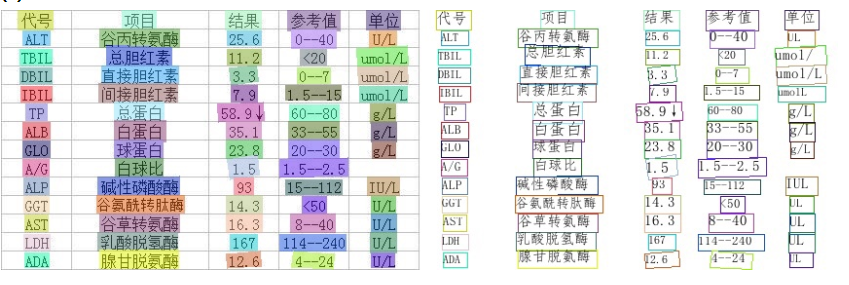
图二

为了测试该项目的识别性能、随后我在网上找了一张关于优惠卷的图片,图片中文字情况比较复杂,垂直、斜体等;还有中英文相结合,甚至还有小数点

最终测试效果如下,无论左边图片文本复杂度有多高,图中文字基本都能识别到,非常Nice 👍

关于 PaddleOCR 模型 ,有以下几个特点
- PaddleOCR 从 2020.5.14 发布,项目迭代到现在,功能一直处于在不断完善的过程;

-
在 PaddleOCR 识别中,会依次完成三种任务:检测、方向分类及文本识别;
-
关于预训练权重,PaddleOCR 官网根据提供权重文件大小分为两类:
- 一类为轻量级,(检测+分类+识别)三类权重加起来大小一共才 9.4 M,适用于手机端和服务器部署;
- 另一类(检测+分类+识别)三类权重内存加起来一共 143.4 MB ,适用于服务器部署;
- 无论模型是否轻量级,识别效果都能与商业效果相比,在本期教程中将选用轻量级权重用于测试;
-
支持多语言识别,目前能够支持 80 多种语言;
-
除了能对中文、英语、数字识别之外,还能应对字体倾斜、文本中含有小数点字符等复杂情况
-
提供有丰富的 OCR 领域相关工具供我们使用,方便我们制作自己的数据集、用于训练
- 半自动数据标注工具;
- 数据合成工具;
-
支持 pip 安装,简单上手;
3 PaddleOCR 使用
简单介绍完之后,下面将手把手教大家怎么去使用 PaddleOCR,
3.1 环境介绍
介绍一下本次所用的测试环境
- os:Win10;
- Python:3.7.9;
3.2 安装 PaddlePaddle2.0
PaddleOCR 需在 PaddlePaddle2.0 下才可以正常运行,开始之前请确保 PaddlePaddle2.0 已经安装,
pip3 install --upgrade pip
#
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
3.2 克隆 PaddleOCR 仓库
用 git clone 命令或者 Download 把项目仓库直接下载到本地
git clone https://github.com/PaddlePaddle/PaddleOCR
这里我用的是 git 命令
3.3 安装PaddleOCR 第三方依赖包
命令行进入 PaddleOCR 文件夹下
cd PaddleOCR
安装第三方依赖项
pip3 install -r requirements.txt
这一步骤如果报错的话,建议把改项目放置在一个虚拟环境中再进行安装,如果用虚拟环境的话,记得还需要安装一下 PaddlePaddle 包
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
3.4 下载权重文件
权重链接地址分别贴在下方,需依次下载到本地;检测权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar
方向分类权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
识别权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
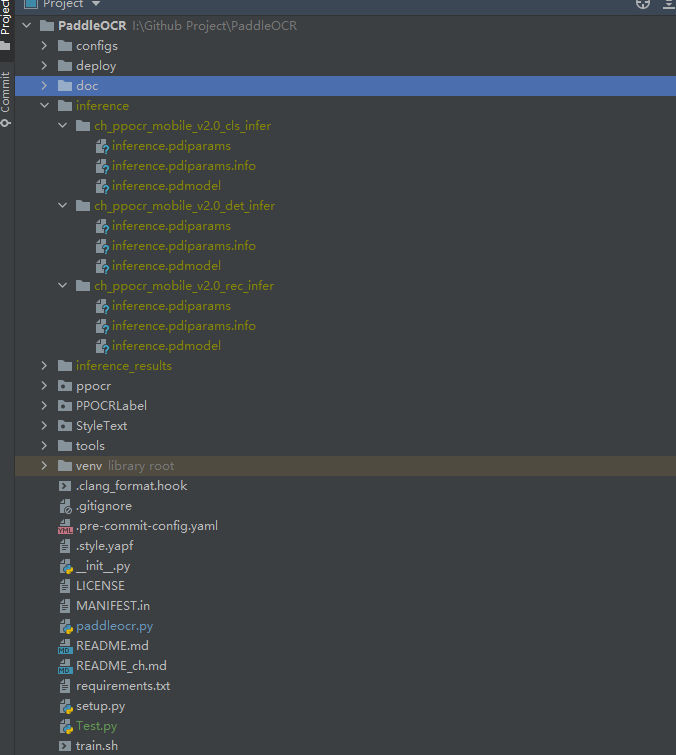
下载到本地之后分别进行解压,创建一个 inference 文件夹,把前面解压后的三个文件夹放入 inference 中,再把 inference 文件夹放入 PaddleOCR 中,最终树形目录结构效果如下:
**3.5 PaddleOCR 使用 **
以上环境配置好之后,就可以使用 PaddleOCR 进行识别了,在PaddleOCR 项目环境下打开终端,根据自己情况,输入下面三种类型中的一种即可完成文本识别
**1,使用 gpu,识别单张图片 **
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
2,使用 gpu ,识别多张图片
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
3,不使用gpu,识别单张图片
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
里面有两个参数需要自己配置一下,参数说明:
image_dir-> 为需要识别图片路径或文件夹;det_model_dir-> 存放识别后图片路径或文件夹;
PaddleOCR 识别一张图片很快,只用 CPU 的话,也只需要两三秒
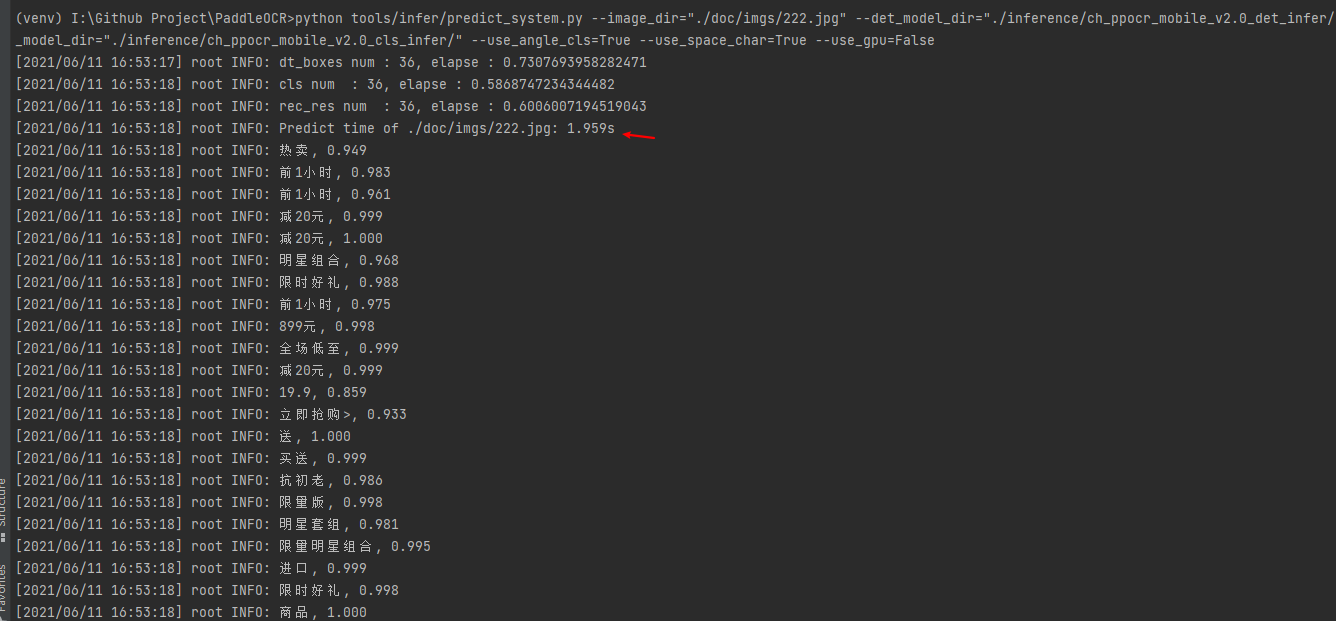
4. 数据、源码获取
为了方便,我已经把测试数据、项目代码都打包在一起了,下载后完成以下两个步骤即可正常使用(使用方法参考章节 3.5 部分)
- 创建虚拟环境;
- pip 工具安装依赖项;
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
# 依赖项
pip3 install -r requirements.txt
获取方式:关注微信公号:小张Python (本号),后台回复关键字:210612 即可
5 小总结
Paddle-OCR 属于Paddle 框架其中的一个应用,Paddle 除了 OCR 之外还有许多其它好玩的模型,关键开发者提供有训练好的预权重文件、降低了使用门槛
后期呢,我也打算将从中挑一些好玩的项目,通过博文的方式手把手教大家跑起来
好了,关于 PaddleOCR 的使用就介绍到这里了,如果内容对你有帮助的话不妨点个赞来鼓励一下我~
最后感谢大家的阅读,我们下期见















 5741
5741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











