







L2范数
除了L1范数,还有一种更受宠幸的规则化范数是L2范数: ||W||2。它也不逊于L1范数,它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。这用的很多吧,因为它的强大功效是改善机器学习里面一个非常重要的问题:过拟合。至于过拟合是什么,上面也解释了,就是模型训练时候的误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。通俗的讲就是应试能力很强,实际应用能力很差。擅长背诵知识,却不懂得灵活利用知识。例如下图所示(来自Ng的course):
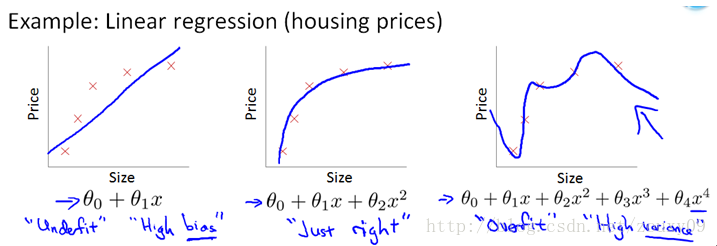
上面的图是线性回归,下面的图是Logistic回归,也可以说是分类的情况。从左到右分别是欠拟合(underfitting,也称High-bias)、合适的拟合和过拟合(overfitting,也称High variance)三种情况。可以看到,如果模型复杂(可以拟合任意的复杂函数),它可以让我们的模型拟合所有的数据点,也就是基本上没有误差。对于回归来说,就是我们的函数曲线通过了所有的数据点,如上图右。对分类来说,就是我们的函数曲线要把所有的数据点都分类正确,如下图右。这两种情况很明显过拟合了。
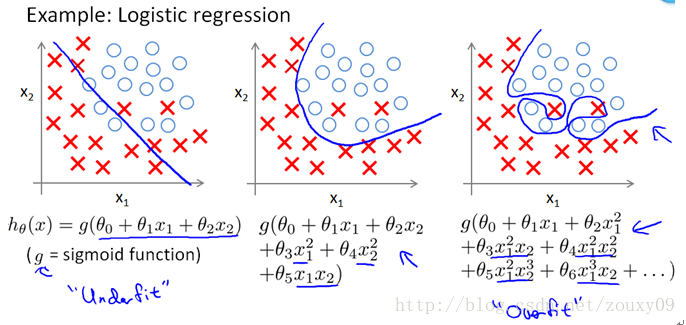
OK,那现在到我们非常关键的问题了,为什么L2范数可以防止过拟合?回答这个问题之前,我们得先看看L2范数是个什么东西。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?我也不懂,我的理解是:限制了参数很小,实际上就限制了多项式某些分量的影响很小(看上面线性回归的模型的那个拟合的图),这样就相当于减少参数个数。其实我也不太懂,希望大家可以指点下。
这里也一句话总结下:通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。
L2范数的好处是什么呢?这里也扯上两点:
1)学习理论的角度:从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。
2)优化计算的角度:
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。哎,等等,这condition number是啥?我先google一下哈。
这里我们也故作高雅的来聊聊优化问题。优化有两大难题,一是:局部最小值&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2213
2213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









