






深度学习与视觉应用
算法评估
算法评估相关概念
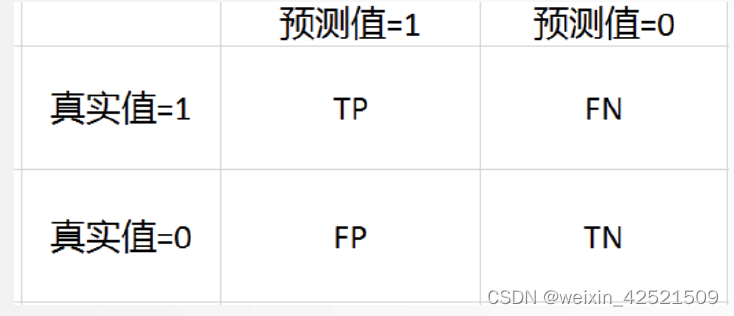
TP:被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP:被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN:被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
混淆矩阵:
P(精确率):TP/(TP+FP),标识“挑剔”的程度
R(召回率):TP/(TP+FN)。召回率越高,准确度越低标识“通过”的程度
精度(Accuracy):(TP+TN)/(TP+FP+TN+FN)
精确率越高召回率越低
置信度与准确率
调整阈值可改变准确率或召回值;不同阈值条件下,Precision与Recall的变化情况
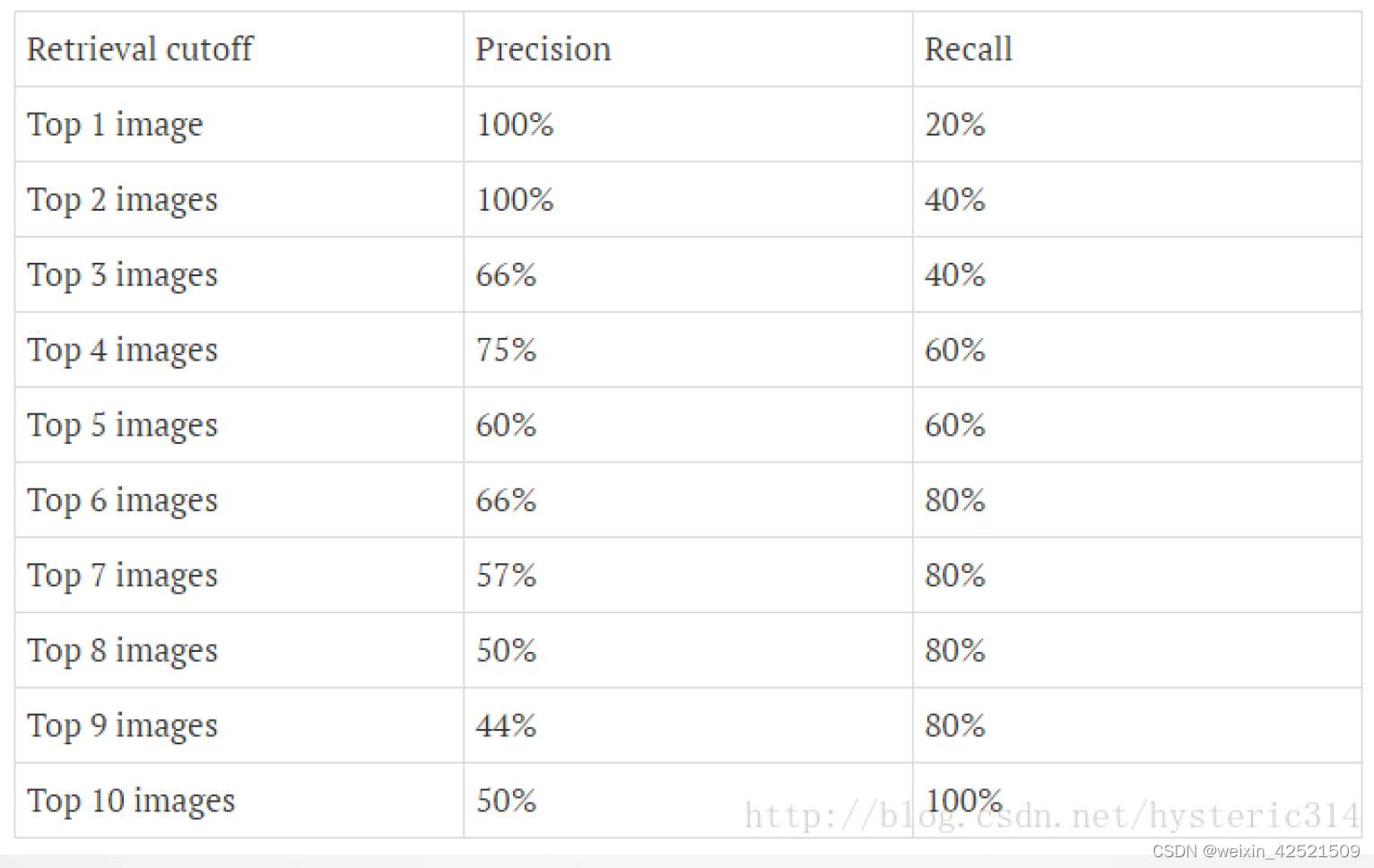
AP计算
mAP:均值平均准确率
其中N代表测试集中所有图片的个数,P(k)表示在能识别出k个图片的时候Precision的值,而△r(k)则表示识别图片个数从k一1变化到k时(通过调整 值)Recall值的变化情况。
AP计算I:实际图像分类任务(多类) 首先使用训练好的模型获得所有测试样本的confidence score,每个类别(如person,car)都会获得一组confidence score。
AP计算II: 实际图像分类任务(多类) 按照上图中的score值从大到小对所有样本进行排序
AP计算III: 实际图像分类任务
目标检测与YOLO
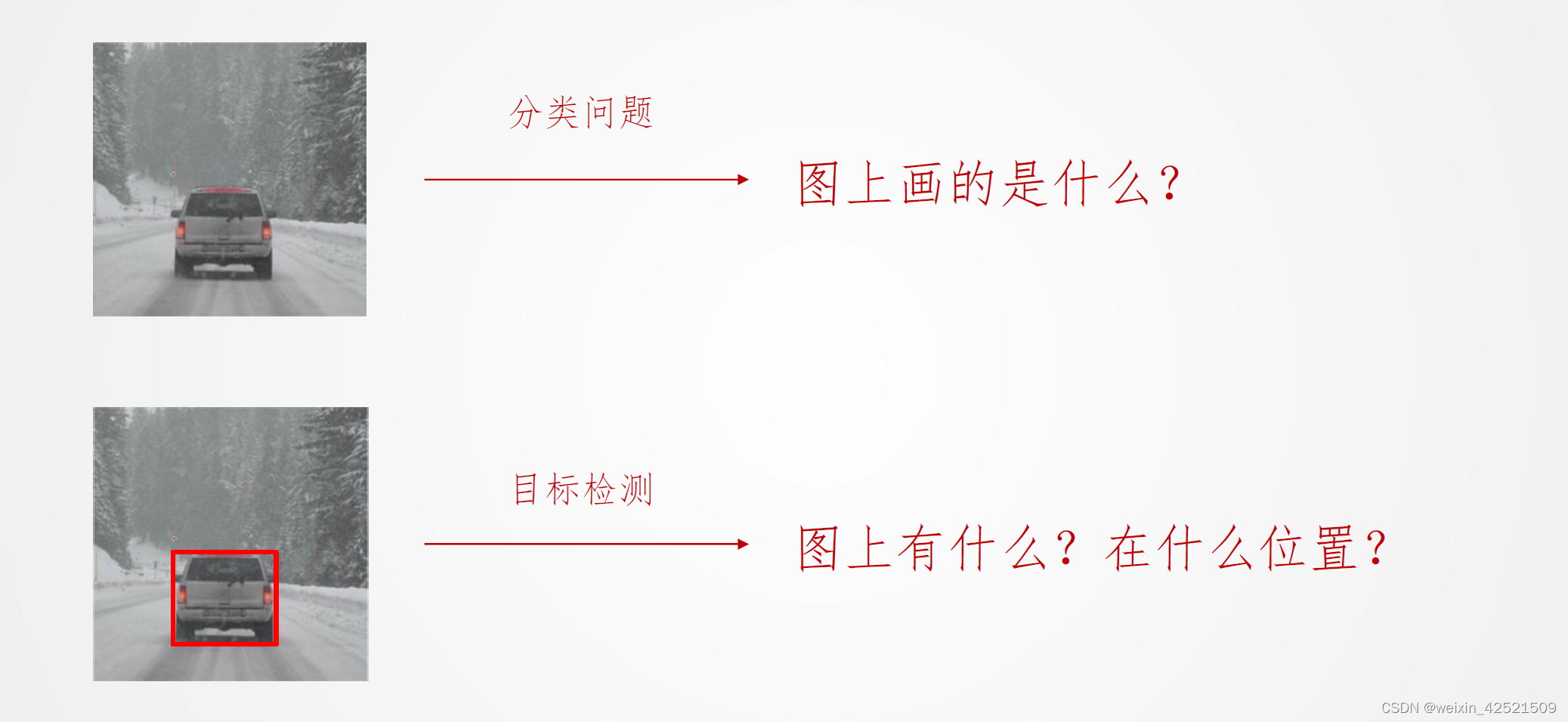
目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。 物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图 片的任何地方,并且物体还可以是多个类别。
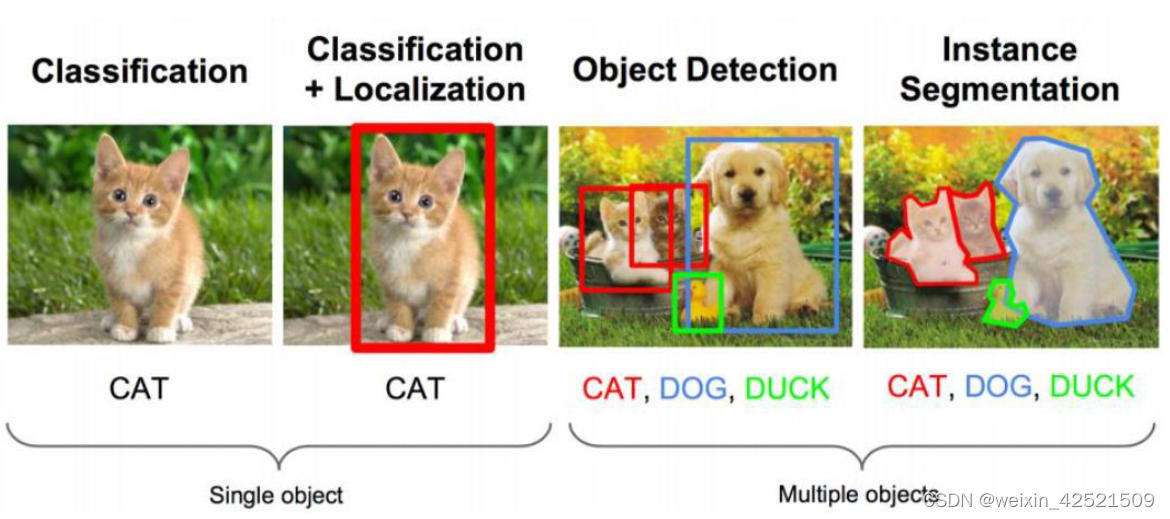

数据输出集表达

基本的滑动窗口

 滑动太多次,计算太慢
滑动太多次,计算太慢
目标大小不同,每个滑动位置需要用很多框
简化二分类问题,只检测葫芦娃的脸

分类问题扩展成回归+分类问题
语义分割
为什么要语义分割?
语义分割:找到同一画面中的不同类型目标区域

实例分割:同一类型自标要分出来具体实例(谁是谁) 目标检测:标出来外包围矩形

语义分割的目标
对图中每一个像素进行分类,得到对应标签
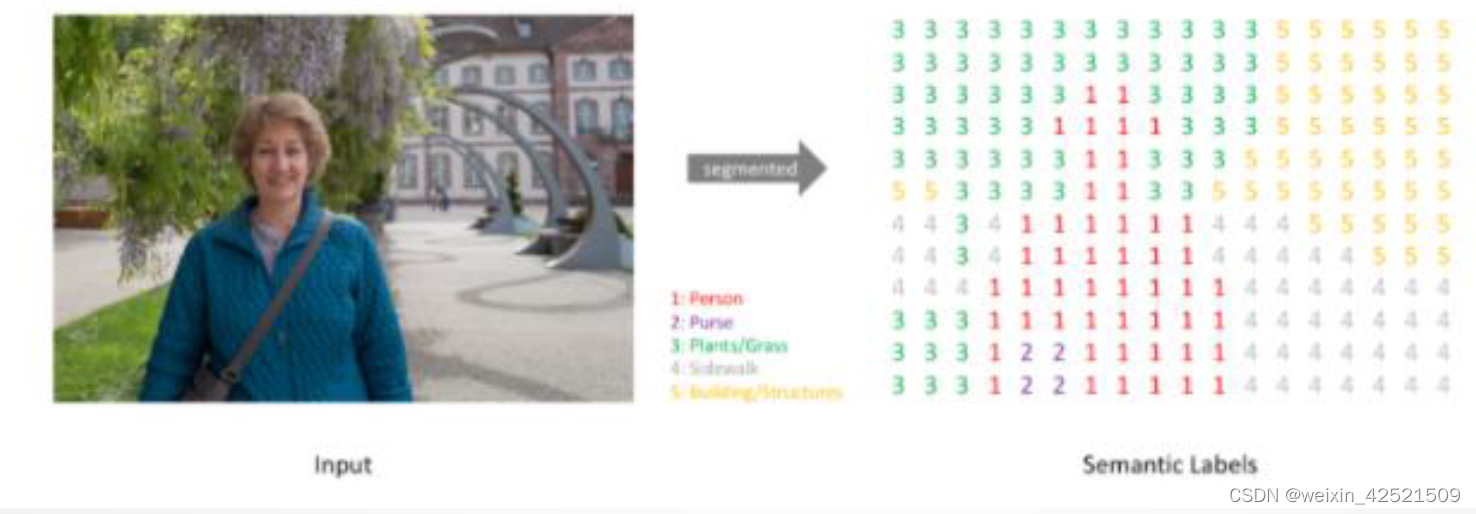
 基本思想:滑动窗口
基本思想:滑动窗口
滑动次数太多,计算太慢,重复计算太多
 风格迁移
风格迁移
如果你是一位摄影爱好者,也许接触过滤镜。它能改变照片的颜色样式,从而使风景照更加锐利或者令人像更加美白。但一个滤镜通常只能改变照片的 某个方面。如果要照片达到理想中的样式,经常需要尝试大量不同的组合, 其复杂程度不亚于模型调参。
这里我们需要两张输入图像,一张是内容图像,另一张是样式图像,我们将使用神经网络修改内容图像使其在样式上接近样式图像。

方法
首先,我们初始化合成图像,例如将其初始化成内容图像。该合成图像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模 型参数。
然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中 的模型参数在训练中无须更新。深度卷积神经网络凭借多个层逐级抽 取图像的特征。我们可以选择其中某些层的输出作为内容特征或样式 特征。
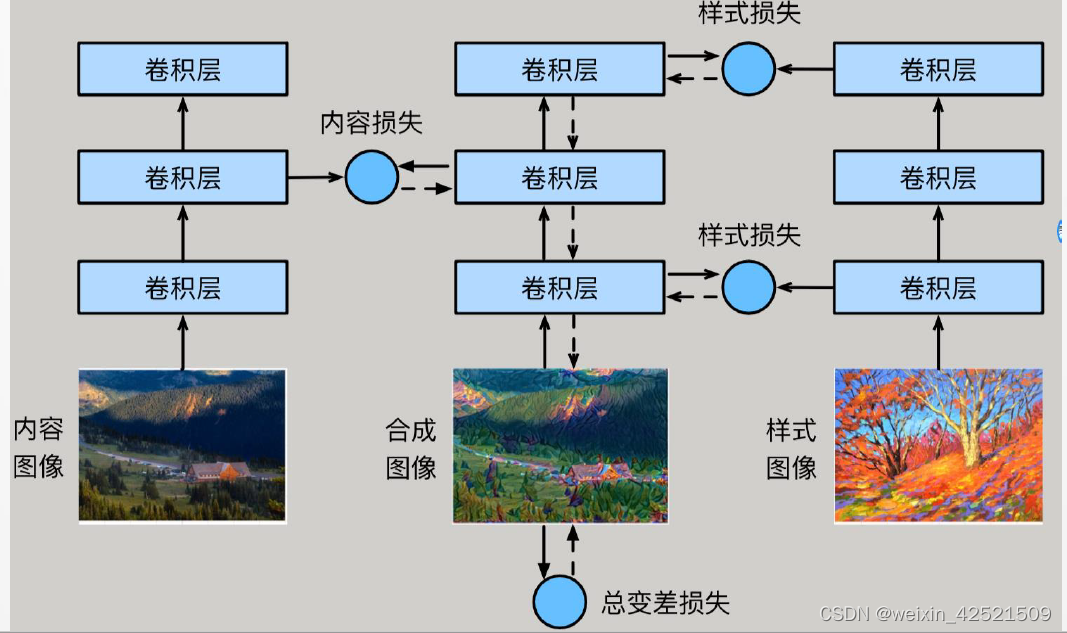
样式迁移常用的损失函数由3部分组成:
内容损失(contentloss)使合成图像与内容图像在内容特征上接近
样式损失(style loss)令合成图像与样式图像在样式特征上接近
总变差损失(total variation loss)则有助于减少合成图像中的噪点。
最后,当模型训练结束时,我们输出样式迁移的模型参数,即得到最终 的合成图像。 W
内容代价函数
![]()
声明:以上来自屈桢深老师课件















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









